机器之心经授权转载
公众号:集智俱乐部(ID:swarma_org)
作者:吴迪
“语言可能是人类面对人工智能最后的壁垒,尤其是中文。”
在3月18日集智俱乐部在中央财经大学学术会堂举办的公开讲座上,华院数据首席数据科学家尹相志结合NLU(Natural Language Understanding,自然语言理解)在金融领域的应用之处侃侃而谈。在阿尔法狗在围棋领域击败人类之后,人类又一引以为傲的智慧壁垒被攻破,那么究竟有没有一个领域是人工智能暂时无法企及人类的?尹相志给出的答案是中文。
NLP(Natural Language Processing,自然语言处理)是人工智能的一个子领域,也是人工智能中最为困难的问题之一,“语言本身就是一种特殊的数据,它本身就覆盖着意义,我们需要提取的是语言的意义,而不是语言的符号形式。”
而NLU将通过对自然语言的理解,实现极佳的人机交互体验,将人类从无聊、繁琐但必要的事务性工作中解脱出来。
 尹相志在集智俱乐部的公开讲座
尹相志在集智俱乐部的公开讲座
新时代的“孔乙己之问”:
形容「物流很快」有几种说法?
金融从业者每天一早就要读报表、新闻,写出晨报或纪要;而一个医生每天也要对病房、病人的情况进行记录,并进行分析。这些“繁琐但必要”的工作,正是NLU的用武之地。
“人工智能首先替代的不是体力劳动。”尹相志说。人工智能将首先攻陷重复劳动较多、毛利率较高的行业,例如金融、医疗。
传统的NLU技术往往采用穷举法,在尹相志看来,这一招对于神秘莫测、巨量词汇的中文不管用。
“想想看,在电商网站的评论中,形容「物流很快」有几种说法?”尹相志的这个提问,让人想起了鲁迅《孔乙己》中的「孔乙己之问」:茴香豆的茴有几种写法?
这两个问题的不同点是,「孔乙己之问」相对封闭,可以通过穷举法轻松回答,而由于中文词汇的多义性,“尹相志之问”则几乎不可能通过穷举法回答,“我们分析,形容「物流很快」至少有3600种说法,比如「第二天就到了」「物流很给力」「给快递点赞」等等,这就给NLU技术提出了很高的考验。”
 汉语表达的多样性
汉语表达的多样性
金融业NLU应用痛点:
实体/关系识别
“对于人工智能,最难的就是理解语言中不同代词的具体所指。”尹相志举例说,在一段文字中,可能出现多个「公司」的单词,那么人工智能就要判断这些「公司」分别是什么公司,而它们之间又是什么关系,这样才能真正理解一段文字。
尹相志说,在金融业的法金授信、二级市场分析、个人资料掩码、授信照会、投资研究等实际工作中,都可以由NLU对实体、关系进行识别。同样的工作如果由人工来做,难免出现疏漏、错误,并且会产生高昂的时间和工资成本。
 活动现场照片
活动现场照片
词向量:NLU的华丽杀招
NLU的核心命题,在于将语言符号数字化。因此,人们利用计算机工具,将词变成了“词向量”,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,然后透过深度学习将高达数百维度的超大向量压缩至200~300维,这样高度压缩的结构就是词向量,这个维度就代表了当前的词。通过阅读“词向量”,人工智能可以把语言“可视化”。
“透过自然语言整理知识图谱,知识图谱再透过自然语言进行推理,是人工智能的下一波增长点。”尹相志预测。
除了语义模拟之外,尹相志还举例介绍了如何利用词向量快速生成实体列表与商务规则。为了消灭歧义,可引入语义增强、语义消歧两种手段。
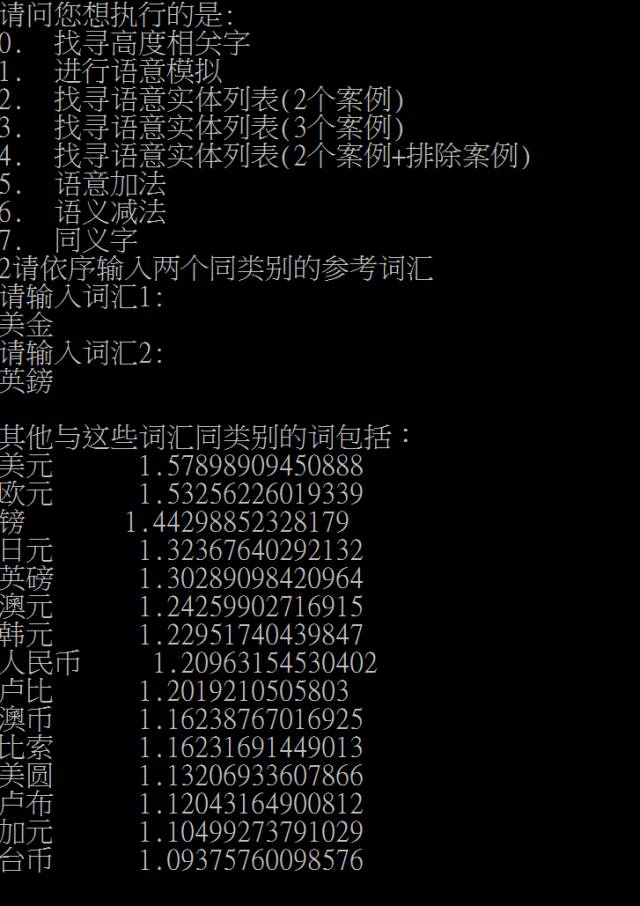
词向量的应用
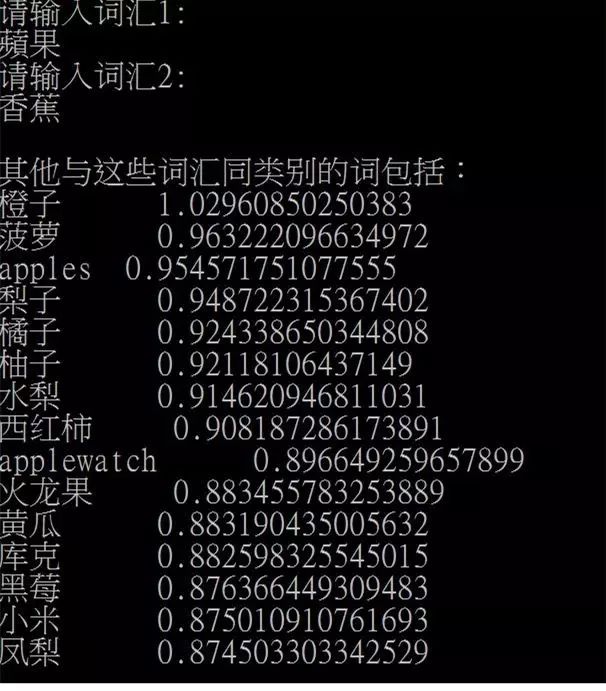
词向量的应用: 语义增强和语义消歧
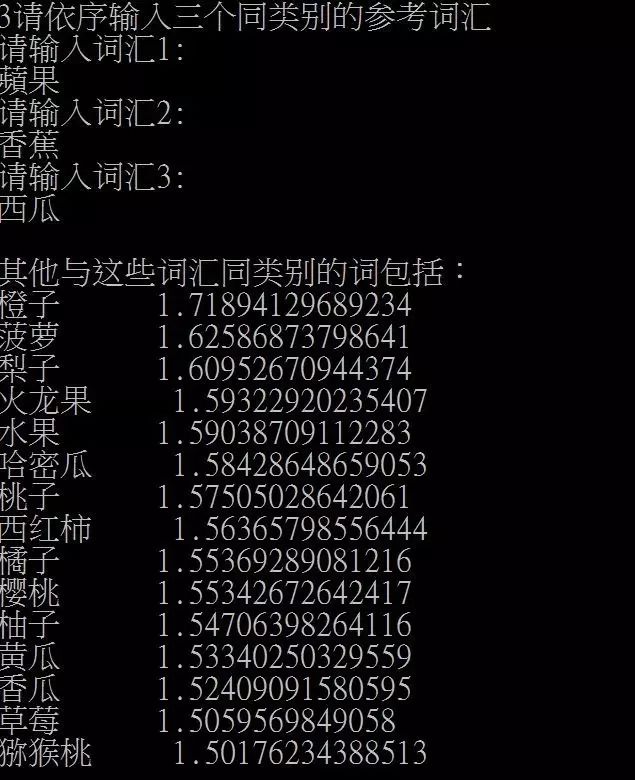
词向量的应用: 语义增强和语义消歧
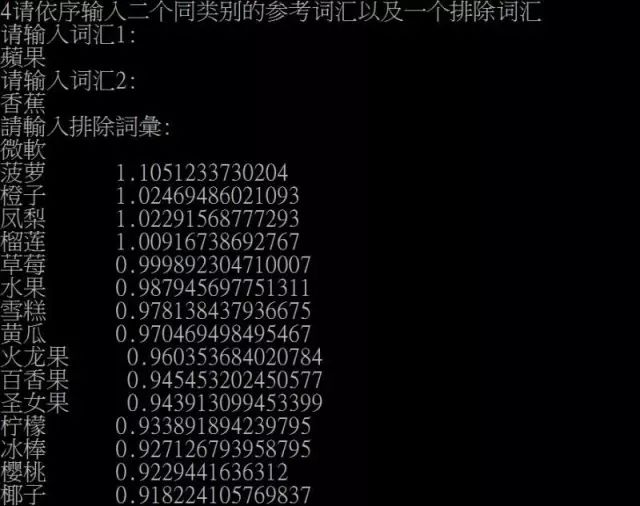
词向量的应用: 语义增强和语义消歧
Brain of Things 2017竞赛题剧透:
人工智能竟然要做这些事
辨别玩具狗和真狗、识别行车记录仪场景、识别超市货架……在2016年的Brain of Things竞赛中,人工智能大显神威,让人看到了机器深度学习的更大潜力。
今年,人工智能又要在比赛中面对怎样脑洞大开的题目?尹相志剧透了初赛和复赛的题目,并且“友情提示”:这些题目都很难。
一、 K线图智能视觉特征理解
赛事提供历史K线图和对应的K线图评论,参赛者需通过训练使计算机自动撰写对应的K线评论。详细数据集内容与评比规则后续将与大赛报名一起发布。
二、市场消息股价影响评估
赛事提供过往宏观、行业等消息和个股的行情、资讯、公告、重大事项等消息,参赛者需要通过训练使计算机可以评估市场消息对于股价的影响。详细数据集内容与评比规则后续将与大赛报名一起发布。
三、泛金融领域商业模式赛
智能投顾、风险控制、定价、欺诈检测、企业和个人征信、财富管理、智能助手、区块链、消费金融、供应链金融等大数据和人工智能在金融领域的创新应用等科技金融领域,提交商业计划化书,商业计划书需含有可操作商业模式和具体实施路径。
想想看,要是AI能较好地完成这些任务,炒股还用愁吗?让我们期待AI的精彩表现吧。
“声称可以识别90%以上自然语言的技术,
很可能是忽悠你的”
在答问环节中,尹相志承认,目前人对于人脑和电脑的学习机制都没有完全研究透彻,人工智能也就很难真的完全理解人类自然语言,“声称可以识别90%以上中文自然语言的技术,恐怕是要小心他在忽悠你了。”只有谦卑的面对技术成未成熟的现实,才有可能向前进步,如何辨别真技术和假忽悠,将成为技术成熟的重要关键。
尹相志认为,技术的产业化应用一定要非常谨慎,反复的失败尝试,会影响投资者和公众的信心。不过,尹相志确信,未来随着算法的完善,NLU的准确率和应用性将越来越强。
©本文为机器之心转载,转载请联系原公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








