
大家好,我是
为人造的智能操碎了心
的智能禅师。
今天带来的文章,由同济大学研究生张子豪投稿。介绍了人工智能与信息安全的交叉前沿研究领域:深度学习攻防对抗。
文章介绍了如何用对抗样本修改图片,误导神经网络指鹿为马;对 NIPS 2017 神经网络对抗攻防赛 3 项冠军清华团队的算法模型进行了解读。
文章部分内容来自 2018 CNCC 中国计算机大会—人工智能与信息安全分会场报告。
本文内容不代表人工智能头条及智能禅师观点。
TD;DR
GAN 一点都不撸棒,简直不要太好骗:胖达变成猴,山误认为狗
对抗样本不是仅在最后预测阶段产生误导,而是从特征提取过程开始就产生误导
NIPS 2017 神经网络对抗攻防赛中,清华大学的学霸们采用了多种深度学习模型集合攻击的方案,训练出的攻击样本具备良好的普适性和可迁移性。
全文大约3500字。读完可能需要好几首下面这首歌的时间
👇

胖虎和吴亦凡,边界是如此的模糊
王力宏和张学友,看上去竟如此的神似
人脸识别、自动驾驶、刷脸支付、抓捕逃犯、美颜直播…人工智能与实体经济深度结合,彻底改变了我们的生活。神经网络和深度学习貌似强大无比,值得信赖。
但是人工智能是最聪明的,却也是最笨的,其实只要略施小计就能误导最先进的深度学习模型指鹿为马。
大熊猫 = 长臂猿
早在2015年,“生成对抗神经网络 GAN 之父” Ian Goodfellow 在 ICLR 会议上展示了攻击神经网络欺骗成功的案例。
在原版大熊猫图片中加入肉眼难以发现的干扰,生成对抗样本。就可以让 Google 训练的神经网络误认为它 99.3% 是长臂猿。

阿尔卑斯山 = 狗
2017 NIPS 对抗样本攻防竞赛案例:阿尔卑斯山图片篡改后被神经网络误判为狗、河豚被误判为螃蟹。
对抗样本不仅仅对图片和神经网络适用,对支持向量机、决策树等算法也同样有效。

那么,具体有哪些方法,可以把
人工智能
,变成
人工智障
呢?
人工智障:逃逸攻击,白盒/黑盒,对抗样本
逃逸攻击可分为白盒攻击和黑盒攻击。
白盒攻击
是在已经获取机器学习模型内部的所有信息和参数上进行攻击,令损失函数最大,直接计算得到对抗样本.
黑盒攻击
则是在神经网络结构为黑箱时,仅通过模型的输入和输出,逆推生成对抗样本。下图左图为白盒攻击(自攻自受),右图为黑盒攻击(用他山之石攻此山之玉)。
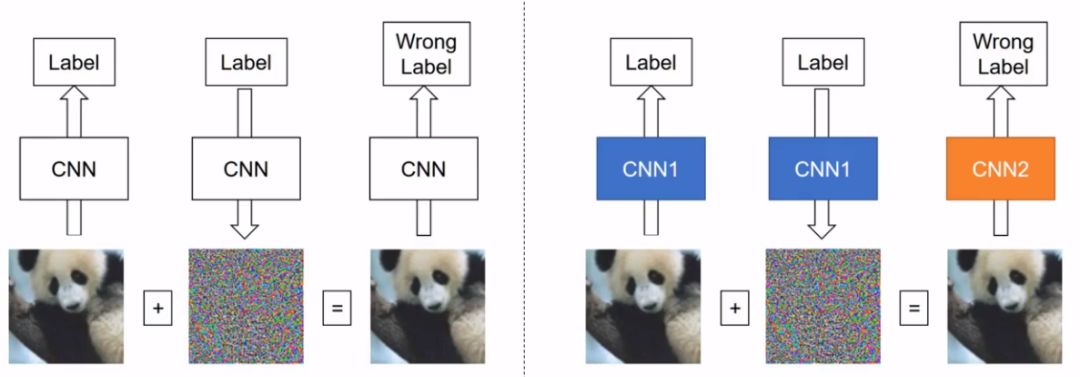
对机器学习模型的逃逸攻击,绕过深度学习的判别并生成欺骗结果,攻击者在原图上构造的修改被称为
对抗样本
。

神经网络对抗样本生成与攻防是一个非常有(zhuang)趣(bi)且有前景的研究方向。
2018年,Ian Goodfellow 再发大招,不仅欺骗了神经网络,还能欺骗人眼。
论文链接👇
https://arxiv.org/abs/1802.08195
文中提出了首个可以欺骗人类的对抗样本。下图左图为猫咪原图,经过对抗样本干扰之后生成右图,对于右图,神经网络和人眼都认为是狗。

下图中,绿色框为猫的原图。左上角显示了攻击的目标深度模型数量越多,生成的图像对人类来说越像狗。 左下角显示了针对 10 个模型进行攻击而生成的对抗样本,当 eps = 8 的时候,人类受试者已经把它认成狗了。

除此之外,人工智能还面临模型推断攻击、拒绝服务攻击、传感器攻击等多种信息安全挑战。
对抗样本有多好骗?
对抗样本会在原图上增加肉眼很难发现的干扰,但依旧能看得出来和原图的区别,下图左图为对抗样本,右图为熊猫原图。

对抗样本不是仅在最后预测阶段产生误导,而是从特征提取过程开始就产生误导. 下图展示了第147号神经元分别在正常深度学习模型和对抗样本中的关注区域。在正常模型中,第147号神经元重点关注小鸟的头部信息。在对抗样本中,第147号神经元则完全被误导了,关注的区域杂乱无章。

同时也说明,
对抗样本不是根据语义生成的
,它并不智能。而且,正如接下来讲述的,对抗样本对图片预处理过程非常敏感,任何区域截图、放大缩小、更换模型都很容易让对抗样本失效。










