
关注
鸿蒙技术社区
,回复
【鸿蒙】
送
价值
399元
的
鸿蒙智能小车
开发套件
(数量有限,先到先得)
,还可以
免费下载
鸿蒙
入门资料
!
👇
扫码
立刻关注
👇
专注开源技术,共建鸿蒙生态
Epoll 是个很老的知识点,是后端工程师的经典必修课。这种知识具备的特点就是研究的人多,所以研究的趋势就会越来越深。当然分享的人也多,由于分享者水平参差不齐,也产生的大量错误理解。
今天我再次分享 epoll,肯定不会列个表格,对比一下差异,那就太无聊了。
我将从线程阻塞的原理,中断优化,网卡处理数据过程出发,深入的介绍 epoll 背后的原理,最后还会 diss 一些流行的观点。相信无论你是否已经熟悉 epoll,本文都会对你有价值。
①epoll 性能到底有多高。很多文章介绍 epoll 可以轻松处理几十万个连接。而传统 IO 只能处理几百个连接,是不是说 epoll 的性能就是传统 IO 的千倍呢?
②很多文章把网络 IO 划分为阻塞,非阻塞,同步,异步。并表示:非阻塞的性能比阻塞性能好,异步的性能比同步性能好。
如果说阻塞导致性能低,那传统 IO 为什么要阻塞呢?epoll 是否需要阻塞呢?Java 的 NIO 和 AIO 底层都是 epoll 实现的,这又怎么理解同步和异步的区别?
③都是 IO 多路复用。既生瑜何生亮,为什么会有 select,poll 和 epoll 呢?为什么 epoll 比 select 性能高?
PS:本文共包含三大部分:初识 epoll、epoll 背后的原理 、Diss 环节。本文的重点是介绍原理,建议读者的关注点尽量放在:“为什么”。
Linux 下进程和线程的区别其实并不大,尤其是在讨论原理和性能问题时,因此本文中“进程”和“线程”两个词是混用的。
epoll 是 Linux 内核的可扩展 I/O 事件通知机制,其最大的特点就是性能优异。
下图是 libevent(一个知名的异步事件处理软件库)对 select,poll,epoll ,kqueue 这几个 I/O 多路复用技术做的性能测试。
很多文章在描述 epoll 性能时都引用了这个基准测试,但少有文章能够清晰的解释这个测试结果。
这是一个限制了 100 个活跃连接的基准测试,每个连接发生 1000 次读写操作为止。纵轴是请求的响应时间,横轴是持有的 socket 句柄数量。
随着句柄数量的增加,epoll 和 kqueue 响应时间几乎无变化,而 poll 和 select 的响应时间却增长了非常多。
可以看出来,epoll 性能是很高的,并且随着监听的文件描述符的增加,epoll 的优势更加明显。
不过,这里限制的 100 个连接很重要。epoll 在应对大量网络连接时,只有活跃连接很少的情况下才能表现的性能优异。
换句话说,epoll 在处理大量非活跃的连接时性能才会表现的优异。如果15000个 socket 都是活跃的,epoll 和 select 其实差不了太多。
为什么 epoll 的高性能有这样的局限性?问题好像越来越多了,看来我们需要更深入的研究了。
①为什么阻塞
我们以网卡接收数据举例,回顾一下之前我分享过的网卡接收数据的过程。
为了方便理解,我尽量简化技术细节,可以把接收数据的过程分为四步:
-
NIC(网卡)接收到数据,通过 DMA 方式写入内存(Ring Buffer 和 sk_buff)。
-
NIC 发出中断请求(IRQ),告诉内核有新的数据过来了。
-
Linux 内核响应中断,系统切换为内核态,处理 Interrupt Handler,从RingBuffer 拿出一个 Packet, 并处理协议栈,填充 Socket 并交给用户进程。
-
系统切换为用户态,用户进程处理数据内容。
网卡何时接收到数据是依赖发送方和传输路径的,这个延迟通常都很高,是毫秒(ms)级别的。而应用程序处理数据是纳秒(ns)级别的。
也就是说整个过程中,内核态等待数据,处理协议栈是个相对很慢的过程。这么长的时间里,用户态的进程是无事可做的,因此用到了“阻塞(挂起)”。
②阻塞不占用 CPU
阻塞是进程调度的关键一环,指的是进程在等待某事件发生之前的等待状态。
请看下表,在 Linux 中,进程状态大致有 7 种(在 include/linux/sched.h 中有更多状态):
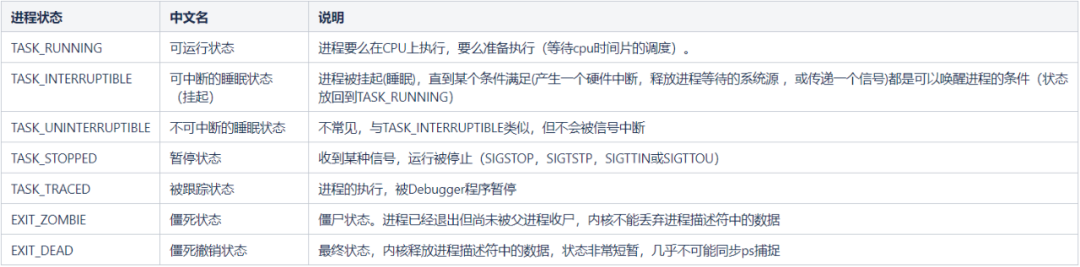
从说明中其实就可以发现,“可运行状态”会占用 CPU 资源,另外创建和销毁进程也需要占用 CPU 资源(内核)。重点是,当进程被"阻塞/挂起"时,是不会占用 CPU 资源的。
换个角度来讲。为了支持多任务,Linux 实现了进程调度的功能(CPU 时间片的调度)。
而这个时间片的切换,只会在“可运行状态”的进程间进行。因此“阻塞/挂起”的进程是不占用 CPU 资源的。
另外讲个知识点,为了方便时间片的调度,所有“可运行状态”状态的进程,会组成一个队列,就叫“工作队列”。
③阻塞的恢复
内核当然可以很容易的修改一个进程的状态,问题是网络 IO 中,内核该修改那个进程的状态。
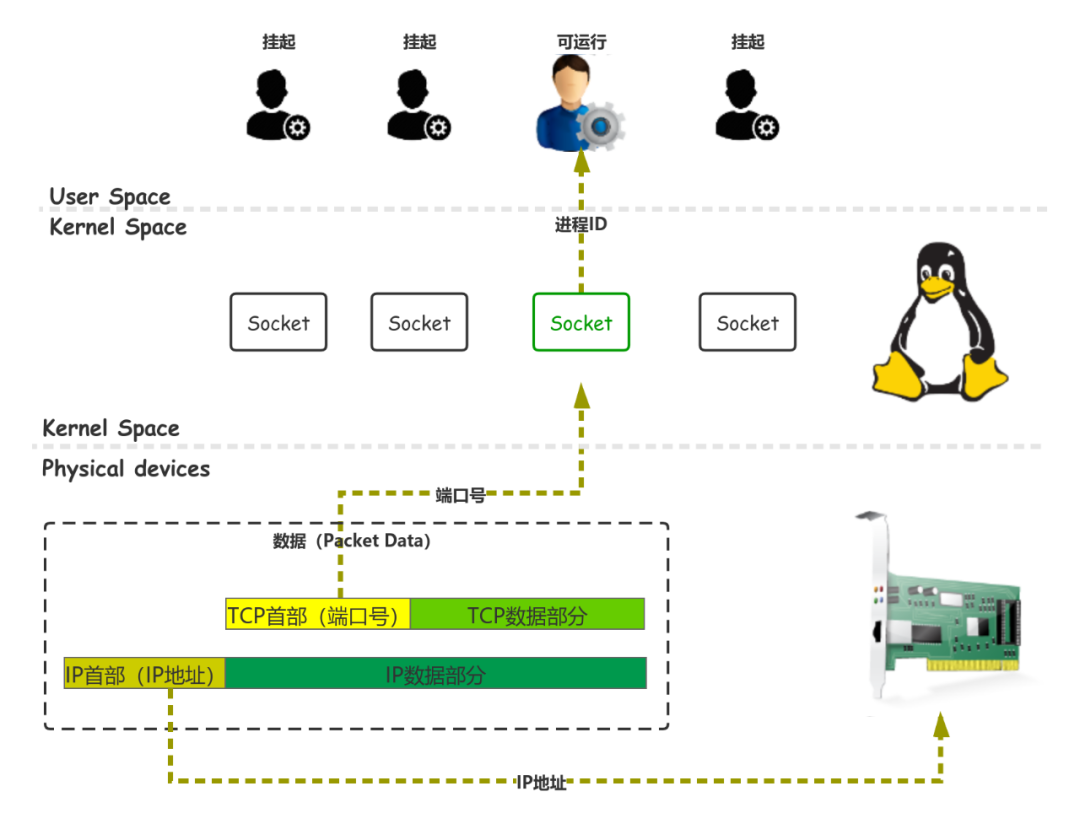
socket 结构体,包含了两个重要数据:进程 ID 和端口号。进程 ID 存放的就是执行 connect,send,read 函数,被挂起的进程。
在 socket 创建之初,端口号就被确定了下来,操作系统会维护一个端口号到 socket 的数据结构。
当网卡接收到数据时,数据中一定会带着端口号,内核就可以找到对应的 socket,并从中取得“挂起”进程的 ID。
将进程的状态修改为“可运行状态”(加入到工作队列)。此时内核代码执行完毕,将控制权交还给用户态。通过正常的“CPU 时间片的调度”,用户进程得以处理数据。
④进程模型
上面介绍的整个过程,基本就是 BIO(阻塞 IO)的基本原理了。用户进程都是独立的处理自己的业务,这其实是一种符合进程模型的处理方式。
上面介绍的过程中,有两个地方会造成频繁的上下文切换,效率可能会很低:
-
如果频繁的收到数据包,NIC 可能频繁发出中断请求(IRQ)。CPU 也许在用户态,也许在内核态,也许还在处理上一条数据的协议栈。但无论如何,CPU 都要尽快的响应中断。这么做实际上非常低效,造成了大量的上下文切换,也可能导致用户进程长时间无法获得数据。(即使是多核,每次协议栈都没有处理完,自然无法交给用户进程)
-
每个 Packet 对应一个 socket,每个 socket 对应一个用户态的进程。这些用户态进程转为“可运行状态”,必然要引起进程间的上下文切换。
①网卡驱动的 NAPI 机制
在 NIC 上,解决频繁 IRQ 的技术叫做 New API(NAPI)。
原理其实特别简单,把 Interrupt Handler 分为两部分:
所以使用了 NAPI 的驱动,接收数据过程可以简化描述为:
-
NIC 接收到数据,通过 DMA 方式写入内存(Ring Buffer 和 sk_buff)。
-
NIC 发出中断请求(IRQ),告诉内核有新的数据过来了。
-
driver 的 napi_schedule 函数响应 IRQ,并在合适的时机发出软中断(NET_RX_SOFTIRQ)。
-
driver 的 net_rx_action 函数响应软中断,从 Ring Buffer 中批量拉取收到的数据。并处理协议栈,填充 Socket 并交给用户进程。
-
系统切换为用户态,多个用户进程切换为“可运行状态”,按 CPU 时间片调度,处理数据内容。
一句话概括就是:等着收到一批数据,再一次批量的处理数据。
②单线程的 IO 多路复用
内核优化“进程间上下文切换”的技术叫的“IO 多路复用”,思路和 NAPI 是很接近的。
每个 socket 不再阻塞读写它的进程,而是用一个专门的线程,批量的处理用户态数据,这样就减少了线程间的上下文切换。
作为 IO 多路复用的一个实现,select 的原理也很简单。所有的 socket 统一保存执行 select 函数的(监视进程)进程 ID。





