本文内容非商业用途可无需授权转载,请务必注明作者及本微信公众号、微博 @唐僧_huangliang,以便更好地与读者互动。
最近几个周末都想写点东西,这次聊聊
GPU/
显卡吧。上面这张图信息量有点大,往下我慢慢跟大家讲
…
昨天看到来自国外的新闻:“
硬件检测工具
AIDA64
的更新日志中出现了一款名为
GeForece RTX T10-8
的显卡,基于
TU102
核心打造。
”
如下图:

记得在
NVIDIA
的几款
RTX Super
加强版显卡推出之前,曾有传言
2080 Ti
也可能会有个
Super
型号,并像
Titan RTX
那样将显存从
11GB
提高到
12GB
(也就是
384-bit
位宽全规格)。后来
NV
辟了谣,不过这一次又有人猜测这个
T10-8
可能是
RTX 2080 Ti Super
啥的。
但我确不这么认为。
2
个简单的理由:第一,“
-8
”有可能是代表
8GB
显存
;第二,“
T10
”并不是个全新的命名,因为之前
Turing
(图灵)架构中已经有个
Tesla T10
。
NV
计算卡的不同定位:
Tesla T4
在
Turing
家族和
RTX
光线追踪
GPU
发布之后,通用型计算的高端卡仍然是
Tesla V100
,在
P100
之后只有
Volta
架构的这款“大核心”支持
FP64
双精度浮点计算。
NV
全面公开发布的
Tesla
新品只有
T4
一款,这肯定有自己的考虑。
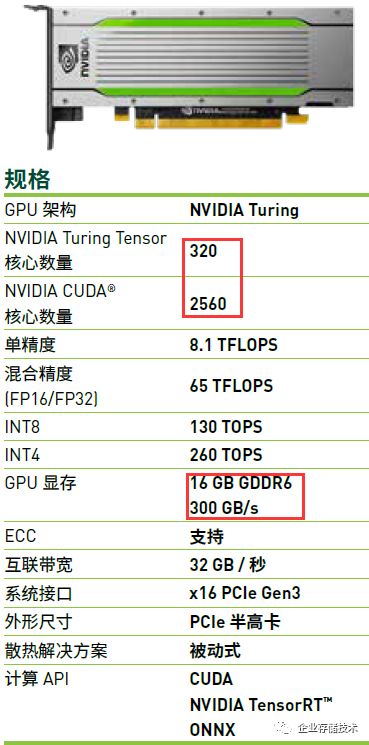
Tesla
基于
TU104
核心,半高小尺寸,功耗只有
70W
。相比之下,它仍然保留了
2560
个
CUDA Core
,并配备高达
16GB
的显存,显然
能耗比相当高
。
与
Tesla V100
更多用于
HPC
不同,
T4
的定位更多是在
AI/
机器学习中的
Inference
(推理),以及
VDI
——
GPU
桌面虚拟化
应用,比如将
16GB
显存切分给
8
个
2GB
的
vGPU
。这里除了单独卖钱的
GRID License
选择之外,
Tesla T4
还提供了
16VF
的
SRIOV
支持。
AI
深度学习计算,特别是
Inference
并不只有
GPU
一种选择,还面临各种不同高效方案的竞争,比如我在《
OCP China Day
:
Nervana
神经网络处理器、
Ruler
还有
500G
?
》里面写的。
NV
最擅长的还是图形显示(包括后端计算的云游戏)
,这方面
ASIC
和
FPGA
可搞不定。
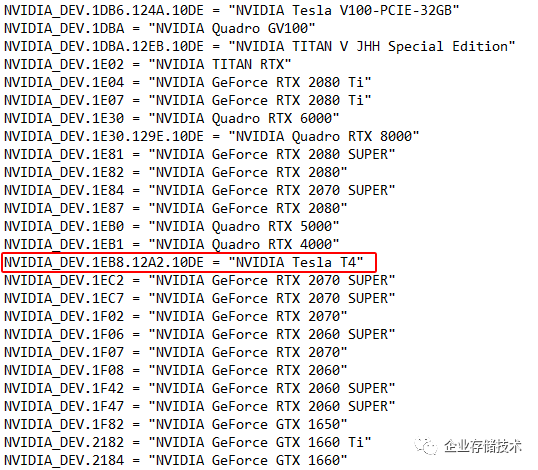
在最新的
NVIDIA
驱动中,
Turing
架构
Tesla
仍然只有一款。我们看到
Tesla
、
Quadro
和
TITAN
的
Device ID
结尾都带有
.10DE
,也就是说只提供原厂卡。
面向云游戏的
Tesla T10
:规格悄然变化

除非您在
NVIDIA
网站上细心浏览过
RTX Server
的页面,否则还真不太容易发现这个
NVIDIA
几乎没有主动宣传过的
Tesla T10
。
Cloud Gaming
——云游戏会不会是下一个增长点呢?
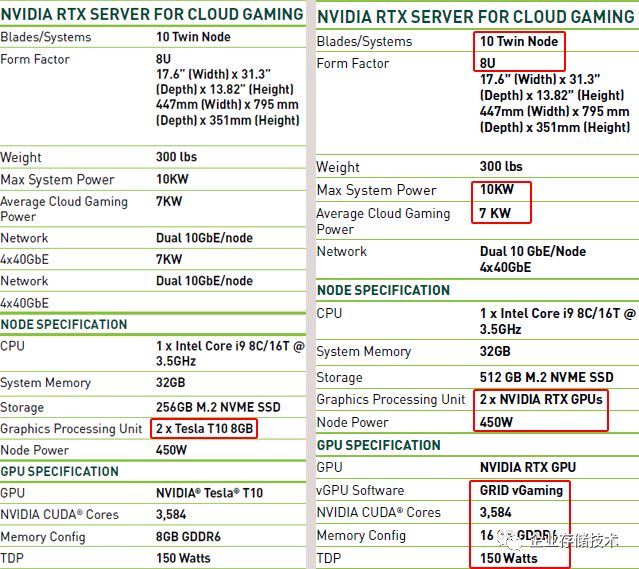
这张图左右两侧截自旧
/
新
2
份资料,大家注意到有什么区别了吗?
NV
这款系统实际上是个
8U
机架的刀片服务器
。每机箱内
10
个双节点刀片
(也就是
20
节点)。
具体到单节点的配置,
CPU
是
1
颗
Intel i9 8
核,
2
颗
Tesla T10 GPU
。不过
NV
最新的资料中
隐去了
RTX
的型号(已经不提
Tesla
了)
,并将显存从
8GB
提高到
16GB
。那么
原来的“
T10-8
”会不会就改成
GeForce
了呢?
在“
Tesla T10 16GB
”显存增大的同时,新版资料中还加入了
vGPU
支持。按照我的理解,在
没有
vGPU
的情况下
,每个双
GPU
节点可能是运行单一
Windows/Linux
系统,
以进程级别隔离在上面运行的“云游戏”
应用;或者
利用
IDV/PCV
这类
PC
虚拟化软件
,在
Linux Hypervisor
底层上
装
2
个虚拟机(很可能是
Win
),把显卡分别以独占方式穿透进去
。
这次
vGPU
(
GRID Gaming
)的引入
,估计就能
把显卡切割给更多的虚拟机
,以达到比进程更好的隔离效果来适配某些游戏。至于“
Tesla T10 16GB
”具体切分为几个
vGPU
使用,我稍后会讲。
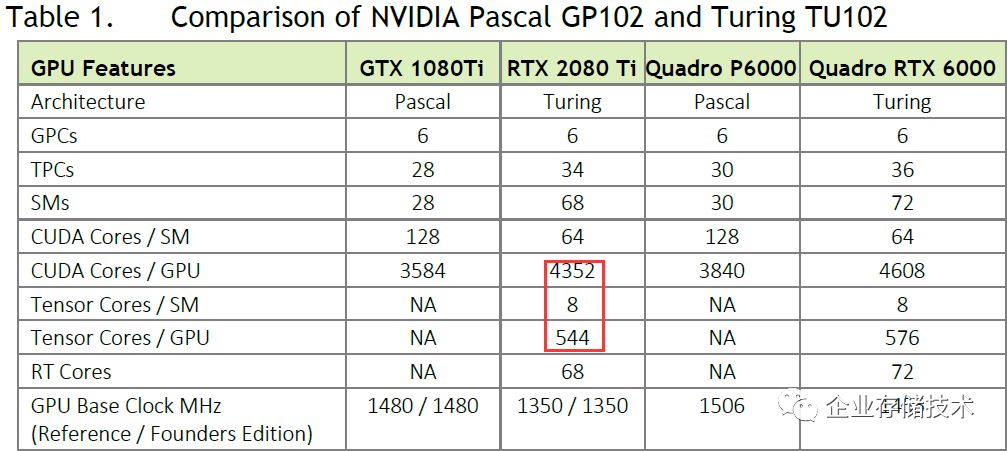
先来看看
Tesla T10 GPU
的规格,
3584
个
CUDA Core
应该属于
TU102
核心
,参考上表,恰好与上一代的
GP102
的
GTX 1080 Ti
数量相同。按照
NV
网站的说法
在游戏中能够达到
GeForce RTX 2080
(属于
TU104
)的水平,而
功耗只有
150W
。这个有点像
Tesla T4
的做法,用相对“大核心”降低频率以实现更好的能耗比,当然
T10
的成本应该比
2080
要高,卖价也会是如此吧?

以前在对比
GPU
服务器时经常会看空间密度,这次的
RTX Server
在
8U
内容纳
40
个
GPU
与传统机型的设计思路不太一样。比如我在《
4U 10
卡机器学习服务器:为什么
PCIe
比
NVLINK
能效比高?
》介绍的
Dell DSS8440
,
8U
内
2
台能放进
20
个
300W
功耗的
Tesla V100
;
1U 4
卡的
PowerEdge C41x0
,
8
节点能达到的密度更高——
32 x 300WGPU
。
云游戏并不需要单卡性能太高,而是更在意能耗比和
CPU
的配比
。
上面这段资料提到
GRID vGaming
软件能让
40
个
GPU
同时运行
160
个
PC
游戏
,如果是每个
CPU
节点启动
8
个虚拟机的话,每个虚机平均能够分配到
4GB
显存的
vGPU
、
1
个
CPU
核心、接近
4GB
内存和
60GB
左右
SSD
容量,运行主流中等负载
3D
游戏差不多够了。
如果在数据中心配置
30
套
RTX Server
,可以服务数千个并发用户
。
挖矿之外,
GeForce
在数据中心允许的另一用途?
无论
RTX Server
中的“
T10 16GB
”是否还叫
Tesla
,包括我和一些同行朋友都认为:如果是传统
NV
对
Tesla
的定价习惯,想在对成本要求苛刻的云游戏市场中广泛应用是有些困难的
。
就像
NV
之前
只允许
GeForce
在数据中心用于区块链计算
(俗称挖矿)那样,商业公司都希望自己的利益最大化。当然
NV
也不傻,他们在
GeForce RTX
上保留
Tensor Core
全部能力的同时,将
显存容量严格限制在上一代的水平
,这将显著影响一些更大规模计算的性能(如渲染)。
没有显存
ECC
支持
也无法充分保证长时间高负荷运行的稳定,规模大些的商业
HPC
用户基本上只能选
Tesla
和
Quadro
。
还有些功能从技术上是难以限制的
,比如一些
VR
应用和
3D
游戏调用同样的
GPU
处理单元,这时
GeForce
就可能和同等硬件规格的
Quadro
专业显卡跑一样快。具体到此类场景,用户肯定会看性价比,而传统制造业对图形工作站的选型则是另一种情况(具体先不展开了)。
举上面这个例子,我是想说明
NV
为云游戏设计了“
Tesla T10
”
+ vGPU
虚拟化的基础设施,但最终市场选择可能会更看重性价比
。因为还有
Intel
的
PC Farm
方案,有些特殊情况
数据中心里也可以放多节点
PC
,
AMD
的
Radeon
游戏显卡也没有限制吧?
至此,我把
GeForece RTX T10-8
相关背景交待差不多了。当然
以上有许多个人推断的内容
,我还想继续猜一下
T10
会长什么样?
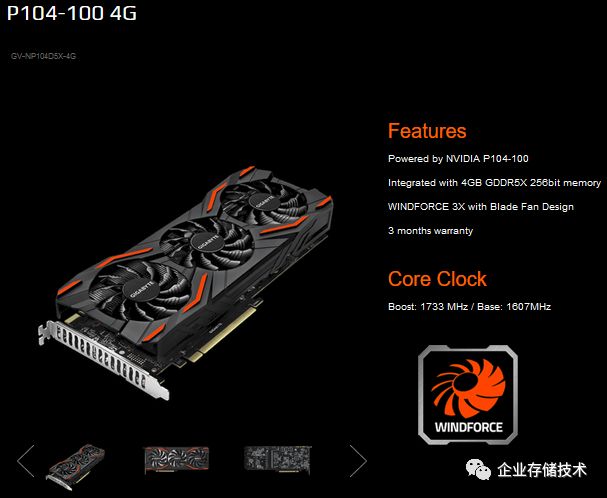
NVIDIA P104
“专用矿卡”,图片引用自技嘉网站。
记得前两年人们用显卡挖矿最多的时候,除了
GeForce 1060
以上全面缺货和涨价之外,这款专用的
P104
也是一卡难求。大家知道普通
GeForce
显卡挖矿损坏是不保修的,
P104
还提供
3
个月质保。
如果
GeForece RTX T10-8
正式名称确实如此,我想它可能也是专为云游戏应用而设计的。具体比
RTX 2080
贵多少我说不准,但也可能会
像
P104
这样去掉显示输出接口?
——因为并不需要本地连接显示器。另外一点:
Tesla
现在都是被动散热,
GeForece RTX T10-8
会采用风扇主动散热吧?
以上也算是我对
云游戏
计算平台的一点小见解
。云游戏
/VR
应用中还涉及远程图形传输协议(视频推流)、针对低延迟网络的
5G
通信等技术,以后有机会再跟大家聊。
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
HL_Storage

长按二维码可直接识别关注
历史文章汇总
:
http://chuansong.me/account/huangliang_storage




