今天这篇跟大家分享我的R VS Pyhton学习笔记系列5——数据索引与切片。
我之前分享过的所有学习笔记都不是从完全零基础开始的,因为没有包含任何的数据结构与变量类型等知识点。
因为一直觉得一门编程语言的对象解释,特别是数据结构与变量类型,作为语言的核心底层概念,看似简单,实则贯穿着整门语言的核心思想精髓,所以一直不敢随便乱讲,害怕误人子弟。还是建议每一个初学者(无论是R语言还是Python,都应该用一门权威的入门书好好学习其中最为基础的数据结构、变量类型以及基础语法函数)。
今天我要分享的内容涉及到R语言与Pyhton中所有的索引与切片方法,包含低级方法和高级方法。
R语言:
-
数据框索引:
-
基于数据框本身提取
-
subset函数
-
filter+select函数
Python:
-
数据框自身的方法
-
ix方法
-
loc方法
-
iloc方法
-
query方法
----------------
R语言:
------------------
library(ggplot2)
我使用ggplot2内置的mpg数据集来进行案例演示,数据框可以通过方括号传入行列下标的方式筛选各种符合条件的取值范围。
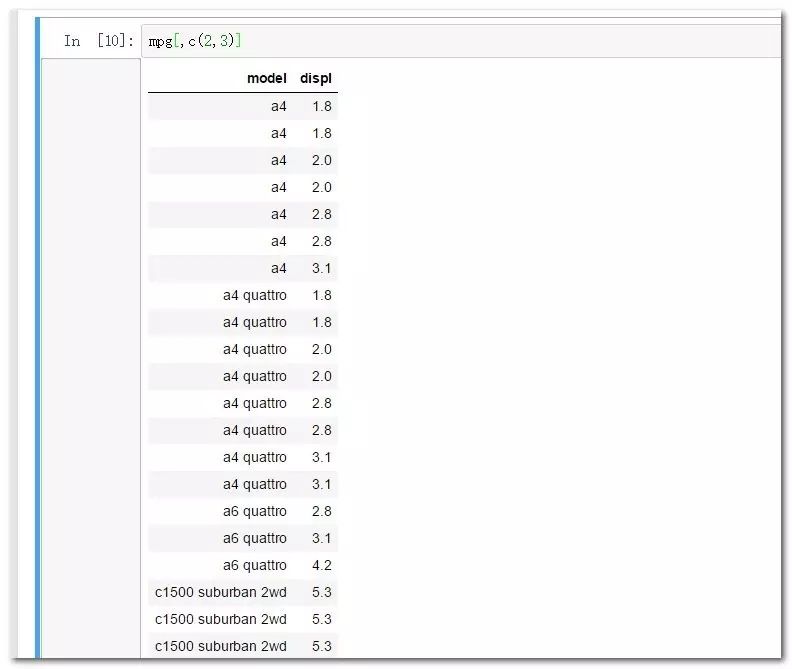
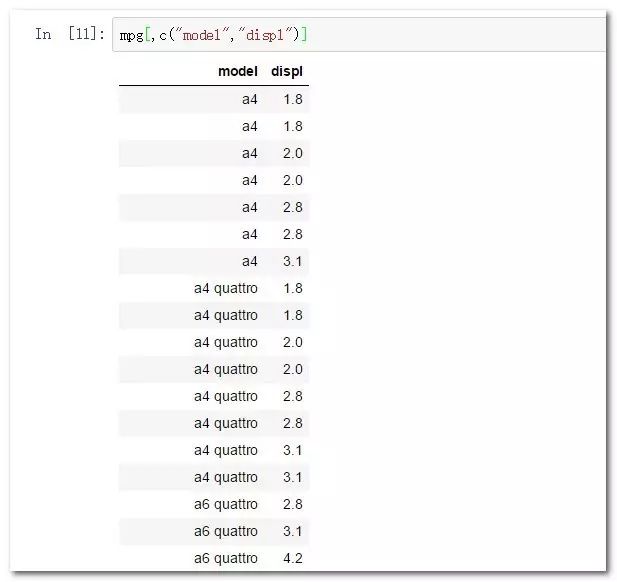
取列可以直接使用列号,或者使用列名:
mpg[,c(2,3)]
mpg[,c("model","displ")]
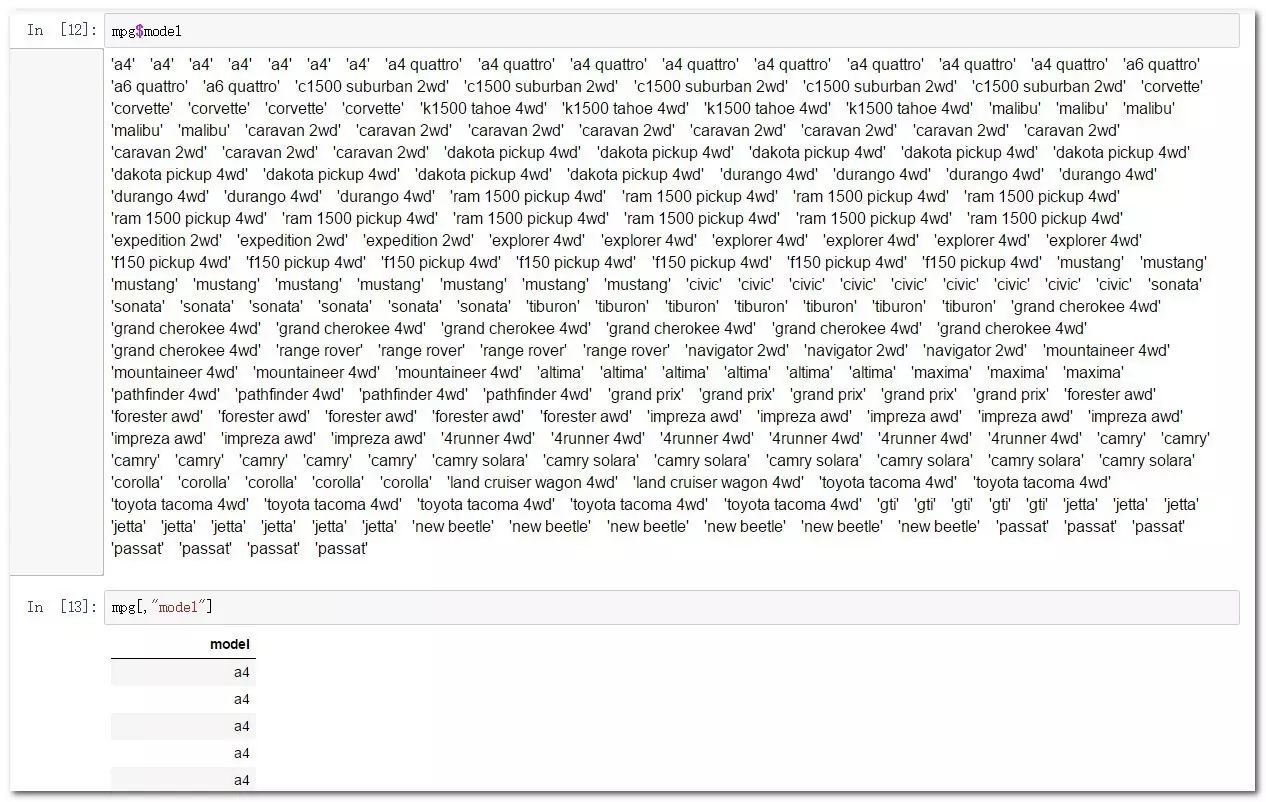
mpg$model 等价于 mpg[,"model"] #取单列时两种方法等价,但是第二种方法会自动降维(编程一个向量)。
行切片:(
行切片同样可以使用行号:
)
mpg[1:10,]
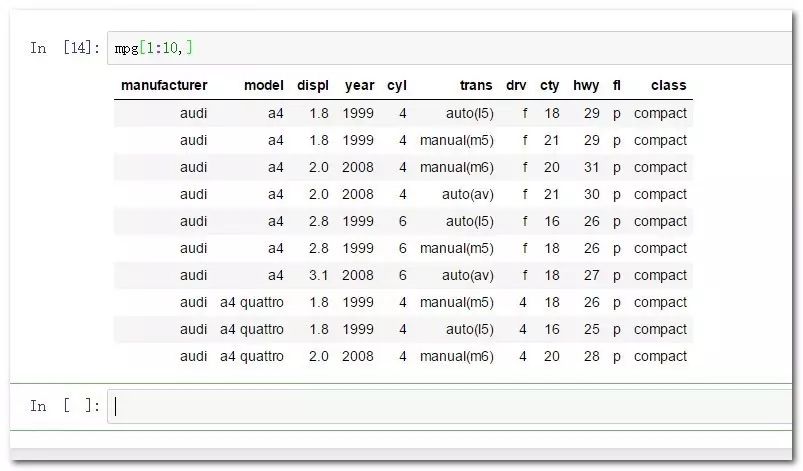
通常情况下这种取值是没有任何意义的,行索引最常用的场景是用于条件索引,来基于分类字段筛选数据子集。
基于数据框本身的条件索引:
mpg[mpg$model=="audi" | mpg$manufacturer=="mercury",] #或条件
mpg[mpg$model=="a4" & mpg$manufacturer=="audi",] #且条件
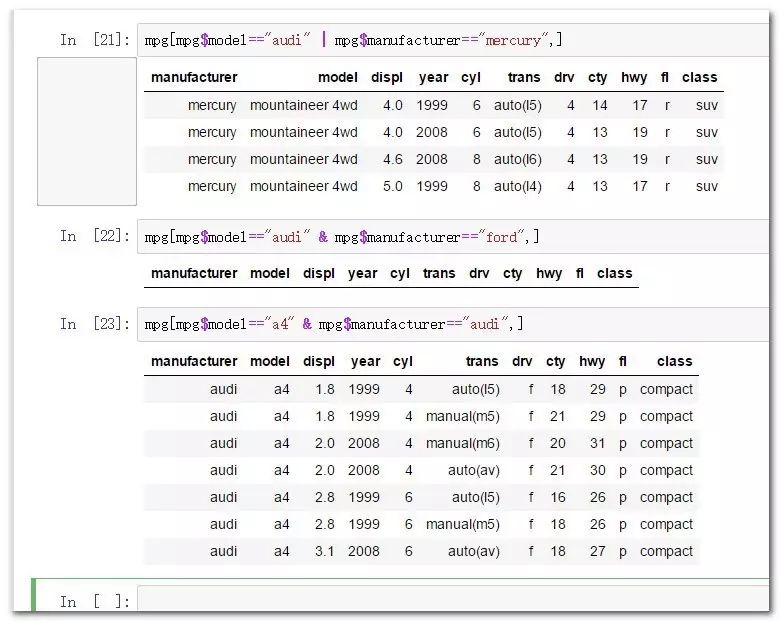
以上索引是在没有借助任何外部函数的基础上,通过数据框自身的规则完成的,很不优雅,因为写了很多重复的名称。
一种更优雅的方式是使用subset函数进行行列筛选。
subset(mpg,model=="audi"| manufacturer=="mercury",select=c("model","manufacturer","year"))
subset(mpg,model=="a4" & manufacturer=="audi",select=c("model","manufacturer","year"))
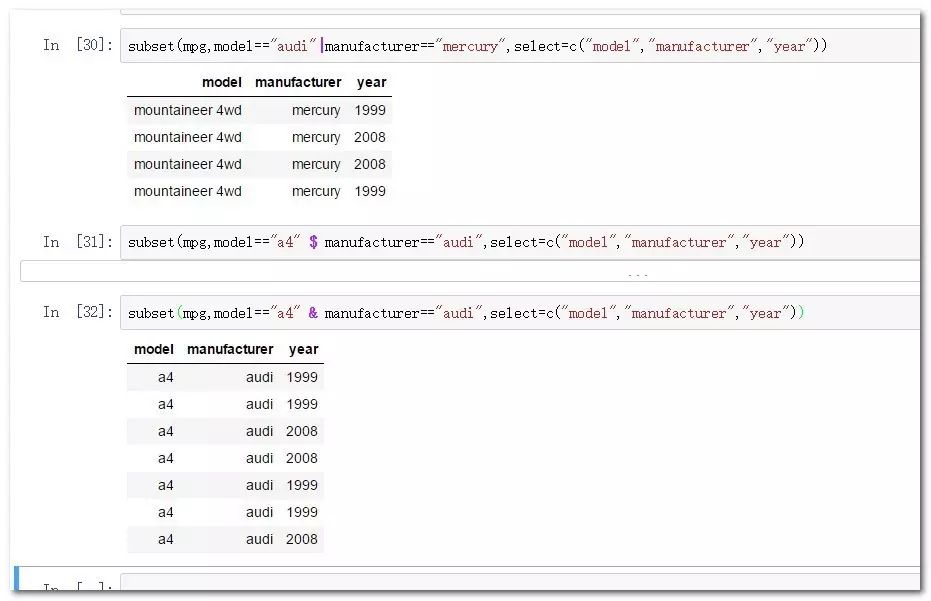
subset函数主要接受三个参数,数据框名称,筛选行,select筛选列。或与且得逻辑表达与上述案例一致。
还有一种更加高级优雅得方式是使用dplyr包中的select和filter函数进行行列索引与切片。
library(dplyr)
mpg%>%filter(model=="audi"| manufacturer=="mercury")%>%select(model,manufacturer,year)
mpg%>%filter(model=="a4" & manufacturer=="audi")%>%select(model,manufacturer,year)

再高级一点儿的切片与索引方法有木有呢,当然有了,datatable包把所有的数据框索引与切片功能参数全都封装到了数据框内部,不过鉴于datatable语法对于初学者会引起不适,而且我平时使用的也比较少,只懂一些皮毛,感性的话,可以自行扩展学习,以上切片与索引方式最足够你完成数据分析工作中的所有切片索引需求。
--------------
Python:
--------------
为了保持与R语言的案例数据演示一致,我把刚才在R语言中使用的数据复制一份导入Python中。
write.table (mpg,"C:/Users/RAINDU/Desktop/mydata.csv",sep=",",row.names=FALSE) #R代码
import os
import pandas as pd
import numpy as np
os.chdir("C:/Users/RAINDU/Desktop/")
mydata = pd.read_csv("mydata.csv",sep = ",",encoding = "utf-8")
#数据预览与描述:
mydata.head()
mydata.describe()
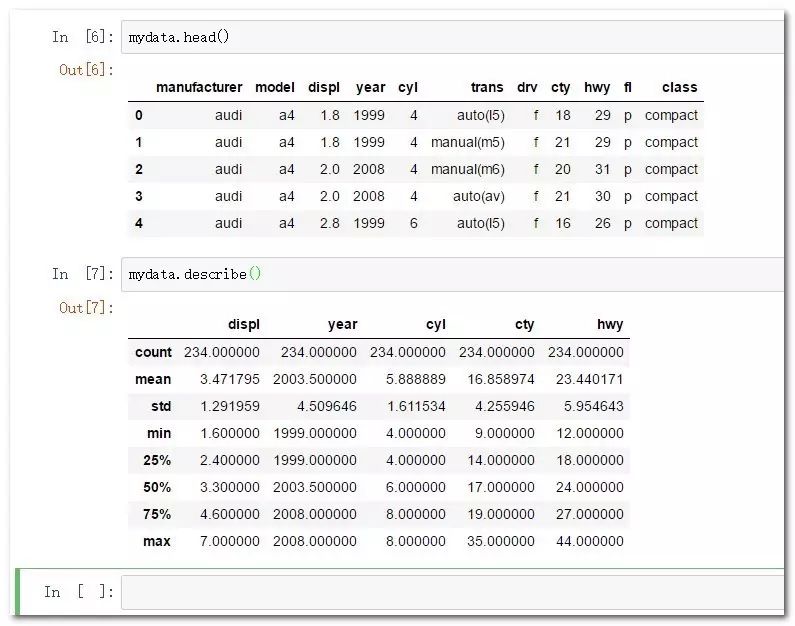
Python中提取列的规则与R语言中极其相似:
提取单行的两种等价方式:
mydata.model #在R语言中应该写mydata$model
mydata["model"] #在R语言中应该写mydata[,"model"]或者mydata["model"]

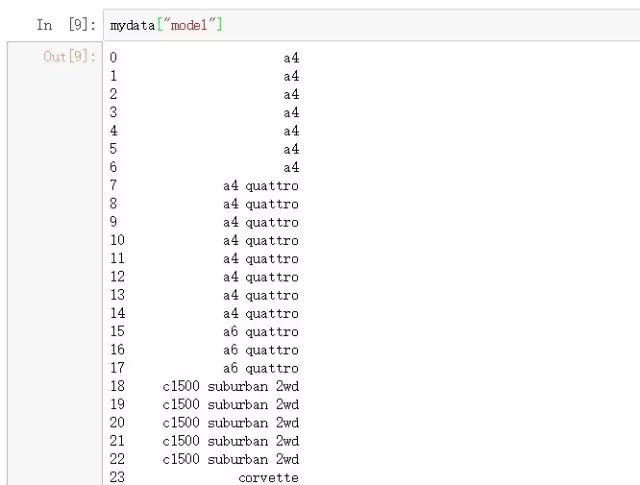
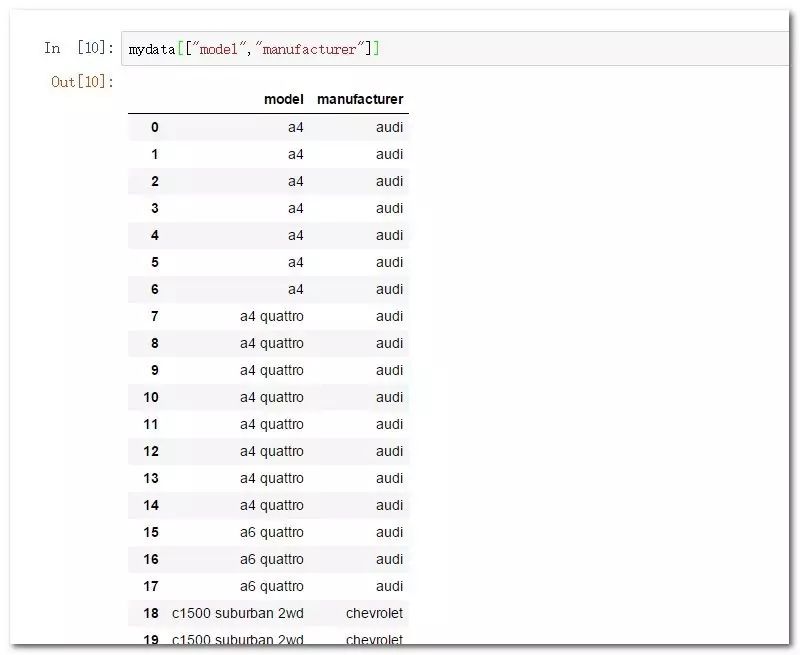
如果是多列则中括号内指定列名组成的列表:
mydata[["model","manufacturer"]]
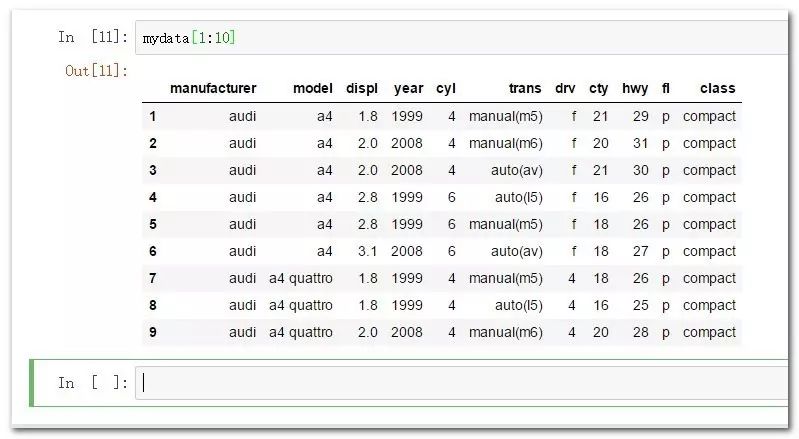
通过指定序号范围来提取行:
mydata[1:10] #默认情况下序列范围是针对行切片(字符串默认则是针对列索引)
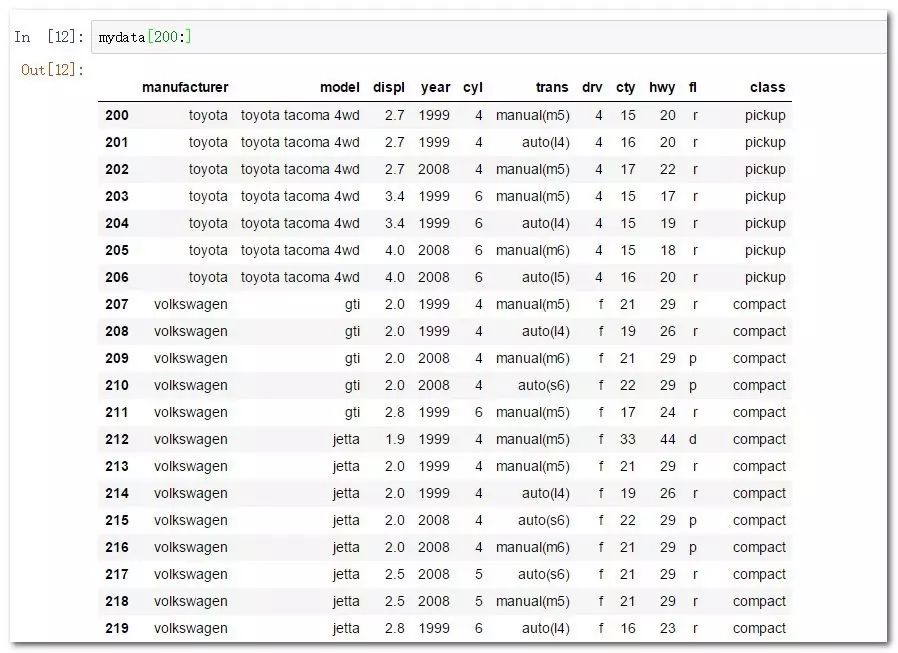
mydata[200:] #切出201个之后的所有记录(Python的数据类型默认从0开始编号)
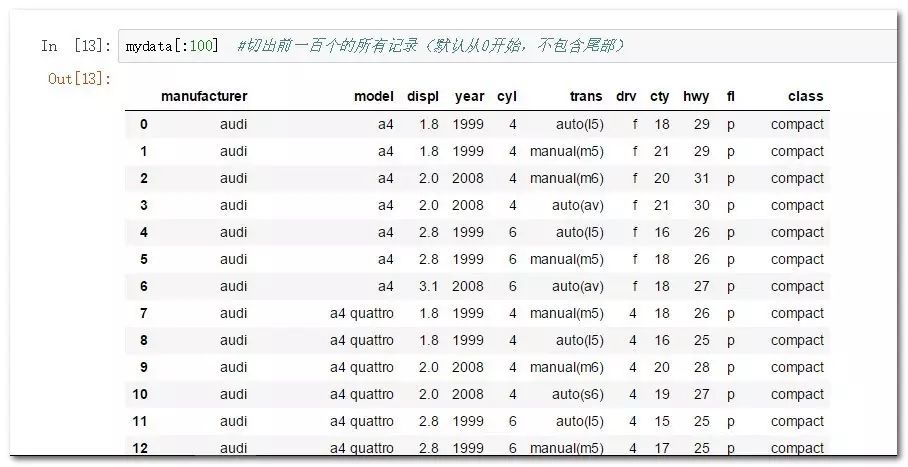
mydata[:100] #切出前一百个的所有记录(默认从0开始,不包含尾部)
mydata[:] #默认提取所有的数据记录
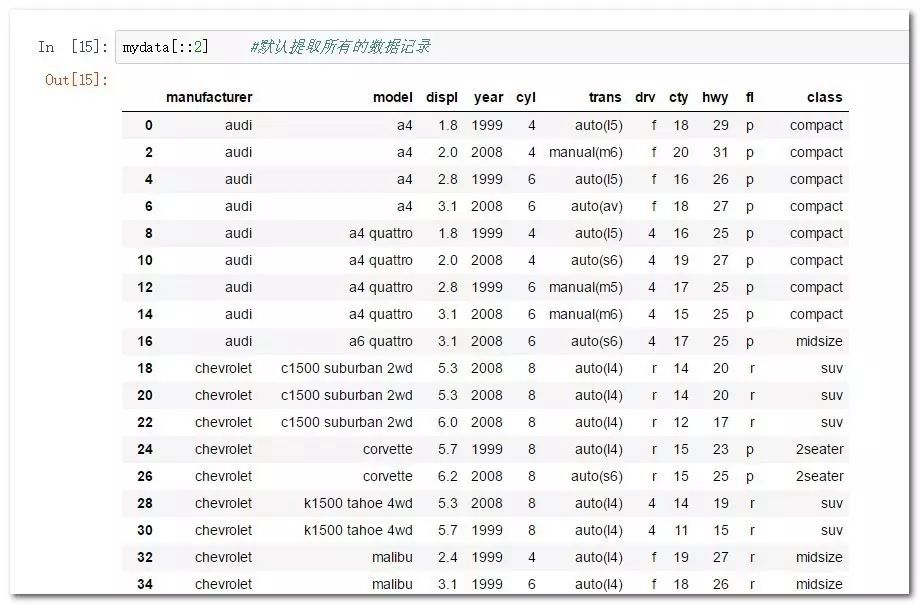
mydata[::2] #默认隔几个单位取一次值
数据框可以同时叠加行列索引与切片:
mydata[1:10][["model","manufacturer"]]
mydata[["model","manufacturer"]][1:10]
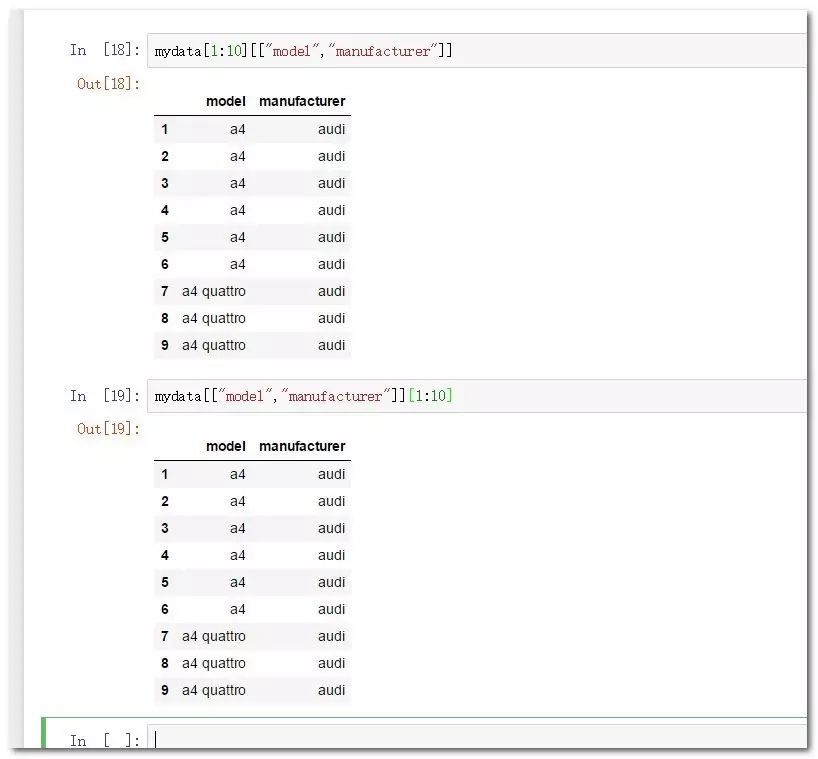
至于行切片与列索引的先后顺序其实是无关紧要的。
除了基于数据框本身的这种简单筛选之外,Python的数据框还提供很灵活的索引方式:
#标签索引:(针对数据框的索引字段)
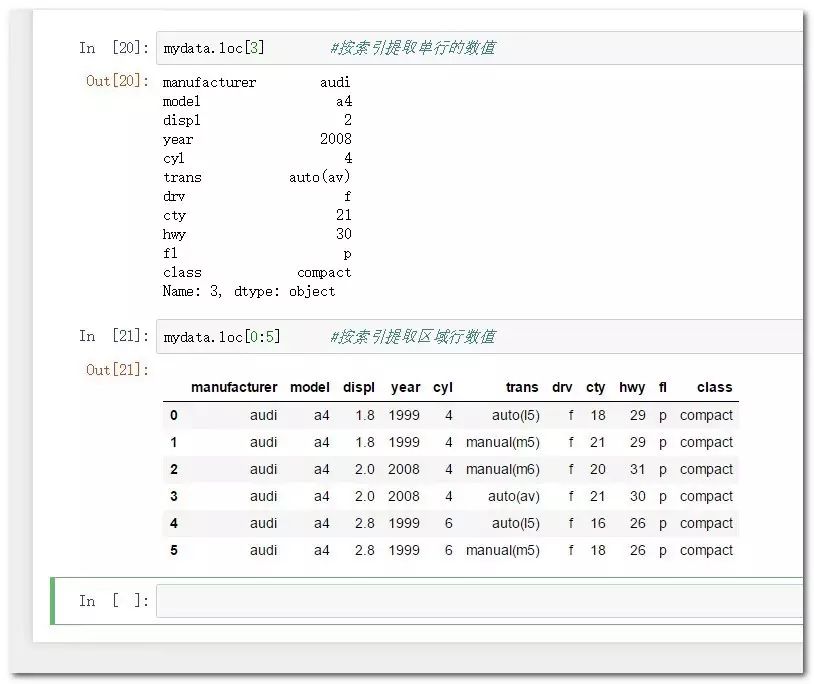
mydata.loc[3] #按索引提取单行的数值
mydata.loc[0:5] #按索引提取区域行数值
mydata.loc[1:10,["model","manufacturer"]] #行列同时索引
如果标签列是字符串或者日期,则使用同样的规则,文本需要 添加单引号 或者双引号。
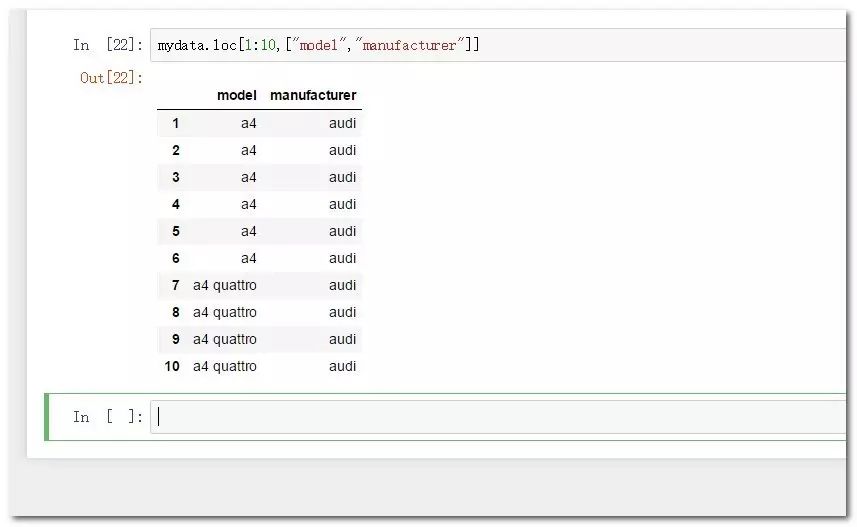
#位置索引:(只针对行列位置对应的序号)
mydata.iloc[[0,2]] 等价于mydata.iloc[[0,2],:]
mydata.iloc[1:] 等价于mydata.iloc[1:,:]
mydata.iloc[1,[0,1]]
mydata.iloc[:3,:2]
mydata.iloc[[0,2,5],[4,5]]
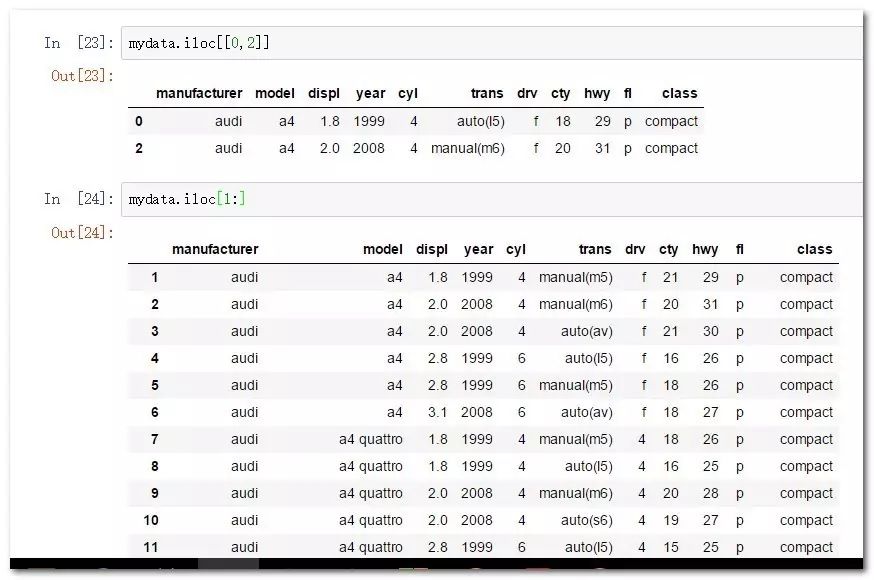
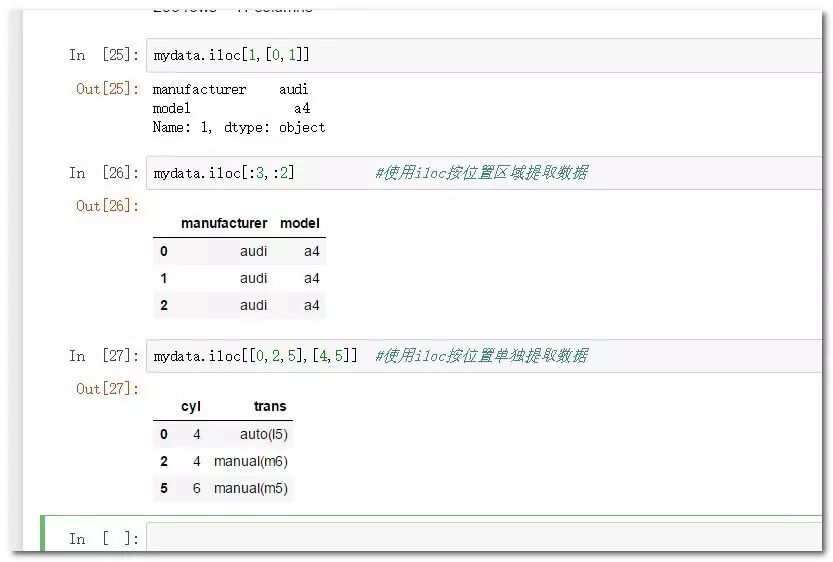
#iloc索引的位置,平时使用是意义不大,只是需要理解其数字和字符串的指定规则,如果只需要提取行的话,列位置可以忽略或者使用
“:”
占位,如果仅仅是提取列规则,保留所有行的话,则行位置必须提供占位,否则会被当做行索引。
位置与标签混合索引(ix函数):









