若朴 发自 凹非寺
量子位·QbitAI 报道

△
这张票有点抢手
早就没票了。
今天下午,Facebook人工智能研究院院长Yann LeCun,将在清华大礼堂主讲一场两个小时的讲座,题目是《深度学习与人工智能的未来》。
如何优雅的听好LeCun的分享?
当然是提前预习。还能预习?当然,其实可以把LeCun的演讲当成一个巡演。很少有明星在巡演的过程中发表全新的主打歌,这放在人工智能领域也一样。
同理,LeCun这次不可能在清华发表一次全新的分享。所以,如果能事先预习一下,对于在现场理解和学习肯定是大大的加成。
去哪儿找预习的内容?
别担心,量子位都给你准备好了。我们不单给你找到了LeCun此前同题分享的视频,而且还找到了一份高质量的学习笔记……贴心不?
这个笔记的作者Valerian Saliou,是Crisp公司的CTO,也是一个全栈工程师。这份《听LeCun分享后有感》的笔记,发布于去年10月27日。
哪怕你没搞到票,现在也不用着急了。因为LeCun要讲的主体思想(为什么感觉这个词怪怪的)是一致的。视频和笔记,这里都齐了。
当然能去现场最好,有票不去的同学,可以把票转给量子位……
视频
好吧,先把视频放出来。我们顺便也把YouTube自动配的英文字幕下载了,有需要的同学,可以在量子位微信公众号( ID:QbitAI )对话界面,回复“字幕”两个字即可获得。
笔记
然后,笔记的环节来了。再次感谢Valerian Saliou。

感知器:第一个学习机器
■ 我们今天使用的机器学习算法是感知器的后代
■
加权总和,误差校正
· 如果输出太低,增加所有输入为正的权重,并减少所有输入为负的权重
· 如果输出太大,那就反过来做
■
监督学习
· 一个训练集
· 一些例子,如果机器出错(或正确),你得调整权重
· 模式识别的标准模型,从50年代至今都是“the only model in town”
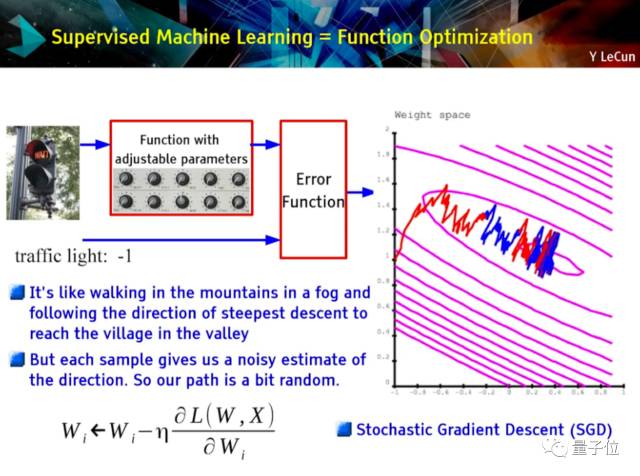
· 监督机器学习=功能优化
· 随机梯度下降,意即针对某一案例,给予机器期望的答案并调整超参数,使得误差减小
· 如何构建复杂的机器?如何推而广之,例如图像识别

■
深度学习系统
· 有数以亿计的“旋钮”
· 每个识别需要数十亿次操作(输入到输出),所以使用GPU,而不是CPU
· 搭建深度学习系统,不是单一模块,而是级联的模块
1、特征提取器
2、中级特征
3、高级特征
4、可训练分类器
· 所有层(即模块)均可训练
· 深度学习中深度的意思是有很多层
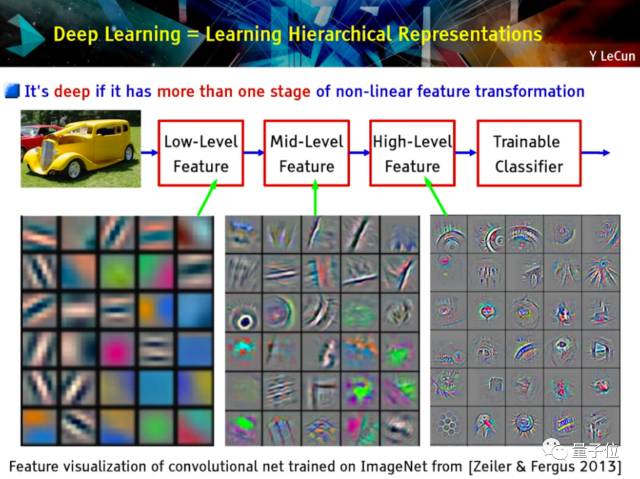
· 图像由图案/对象组成,继续分解为各个部分,继续分解为像素
· 低级特征探测像素
· 中级特征探测部分
· 高级特征探测图案/对象
· 不仅对图像有效,还能用于文本、语音等。让世界变得可理解
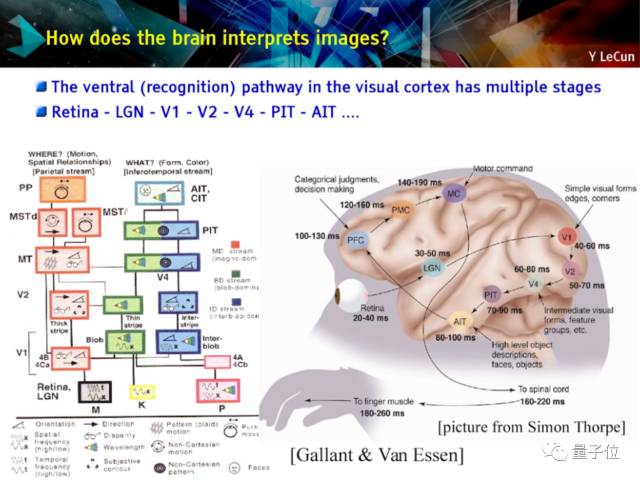
· 大脑的新皮层也是分层的
· 中脑腹侧/识别路径也有很多层
· 非常快(识别对象的过程需要不到100ms)
· 反馈和推理对解释日常对象的影响非常小
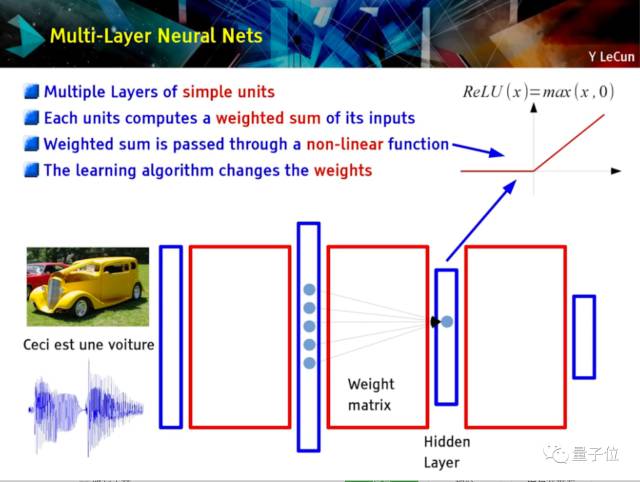
多层神经网络









