去年,
AlphaGo
读遍人间所有的围棋棋谱,击败世界冠军李世石,成为人工智能时代到来的标志事件。而现在,
AlphaGo
Zero
横空出世:TA
没看过任何棋谱,也没有一个人指点,从零开始,左右互搏,就能以100-0打败
AlphaGo
,再次让世界瞩目。TA是怎么做到的呢?
(请在wifi环境下收看,来源:澎湃新闻)
今年5月,以3:0的比分赢下中国棋手柯洁后,AlphaGo宣布退役,但DeepMind公司并没有停下研究的脚步。伦敦当地时间10月18日,DeepMind团队公布了代号
AlphaGo Zero
的最新版本。它的独门秘籍,是“自学成才”。而且,是从一张白纸开始,零基础学习。
团队称,AlphaGo Zero现在的水平已经超过之前所有版本的AlphaGo。在对阵曾赢下韩国棋手李世石那版AlphaGo时,AlphaGo Zero取得了100:0的压倒性战绩。DeepMind团队将关于AlphaGo Zero的相关研究以论文的形式,刊发在了10月18日的《自然》杂志上。
AlphaGo此前的版本,结合了数百万人类围棋专家的棋谱,以及强化学习的监督学习进行了自我训练。
在战胜人类围棋职业高手之前,它经过了好几个月的训练,依靠的是多台机器和48个TPU(
谷歌专为加速深层神经网络运算能力而研发的芯片
)。
AlphaGo Zero的能力则在这个基础上有了质的提升。最大的区别是,它不再需要人类数据。也就是说,它一开始就没有接触过人类棋谱。研发团队只是让它自由随意地在棋盘上下棋,然后进行自我博弈。值得一提的是,AlphaGo Zero还非常“低碳”,只用到了一台机器和4个TPU,极大地节省了资源。
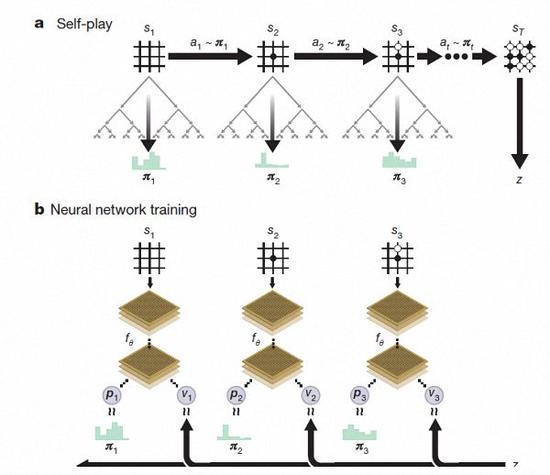 AlphaGo Zero强化学习下的自我对弈
AlphaGo Zero强化学习下的自我对弈
经过几天的训练,AlphaGo Zero完成了近5百万盘的自我博弈后,已经可以超越人类,并击败了此前所有版本的AlphaGo。DeepMind团队在官方博客上称,Zero用更新后的神经网络和搜索算法重组,随着训练地加深,系统的表现一点一点地在进步。自我博弈的成绩也越来越好,同时,神经网络也变得更准确。
 AlphaGo Zero习得知识的过程
AlphaGo Zero习得知识的过程
“这些技术细节强于此前版本的原因是,我们不再受到人类知识的限制,它可以向围棋领域里最高的选手——AlphaGo自身学习。” AlphaGo团队负责人大卫·席尔瓦(Dave Sliver)说。
据大卫·席尔瓦介绍,AlphaGo Zero使用新的
强化学习
方法
,让自己变成了老师。
系统一开始甚至并不知道什么是围棋,只是从单一神经网络开始,通过神经网络强大的搜索算法,进行了自我对弈。
随着自我博弈的增加,神经网络逐渐调整,提升预测下一步的能力,最终赢得比赛。更为厉害的是,随着训练的深入,DeepMind团队发现,AlphaGo Zero还独立发现了游戏规则,并走出了新策略,为围棋这项古老游戏带来了新的见解。
自学3天就打败旧版AlphaGo,“强化学习”令人瞩目
除了上述的区别之外,AlphaGo Zero还在三个方面与此前版本有明显差别。
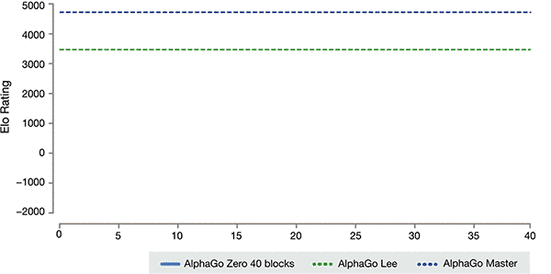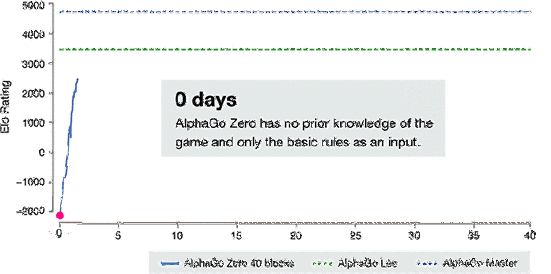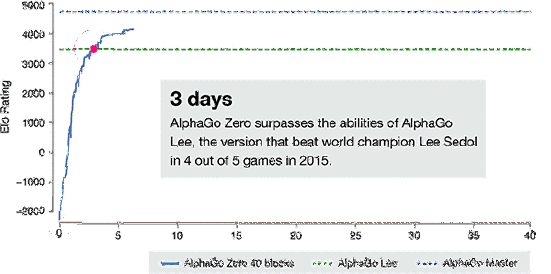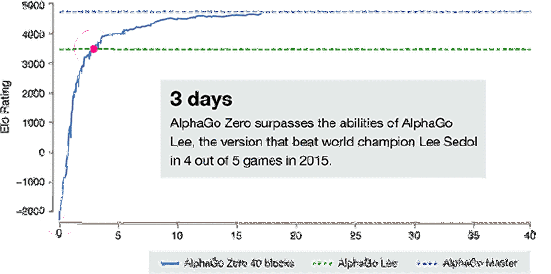 AlphaGo-Zero的训练时间轴
AlphaGo-Zero的训练时间轴
首先,AlphaGo Zero仅用棋盘上的黑白子作为输入,而前代则包括了小部分人工设计的特征输入。
其次,AlphaGo Zero仅用了单一的神经网络。在此前的版本中,AlphaGo用到了“策略网络”来选择下一步棋的走法,以及使用“价值网络”来预测每一步棋后的赢家。而在新的版本中,这两个神经网络合二为一,从而让它能得到更高效的训练和评估。
第三,AlphaGo Zero并不使用快速、随机的走子方法。在此前的版本中,AlphaGo用的是快速走子方法,来预测哪个玩家会从当前的局面中赢得比赛。相反,新版本依靠地是其高质量的神经网络来评估下棋的局势。
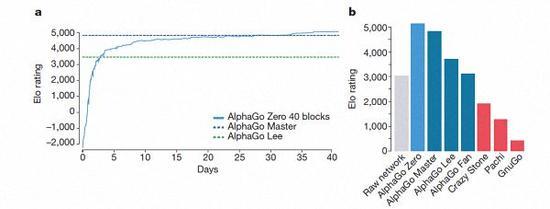 AlphaGo几个版本的排名情况
AlphaGo几个版本的排名情况
据哈萨比斯和席尔瓦介绍,以上这些不同帮助新版AlphaGo在系统上有了提升,而算法的改变让系统变得更强更有效。
经过短短3天的自我训练,AlphaGo Zero就强势打败了此前战胜李世石的旧版AlphaGo,战绩达到惊人的100:0。经过40天的自我训练,AlphaGo Zero又打败了AlphaGo Master版本。“Master”之前击败过世界顶尖的围棋选手,甚至包括世界排名第一的柯洁。
在《自然》杂志上为DeepMind论文撰写的评论中,密歇根大学计算机科学和工程学院教授Satinder Singh写道,这是强化学习(
reinforcement learning
)转化为应用领域里取得的最大进步之一。
在训练过程中,AlphaGo Zero每下一步需要思考的时间是0.4秒。但正是通过对围棋游戏的模拟和训练,神经网络变得越来越好。值得一提的是,AlphaGo Zero相比之前的版本,仅使用了单一的神经网络。
这一切的意义在哪里?AlphaGo的诞生惊艳了世人,现在AlphaGo Zero又将机器能做到的极限往后推了几个量级。Satinder Singh认为,AlphaGo和AlphaGo Zero在一年多时间里取得的进步已经证明,基于强化学习的人工智能比基于人类知识经验的人工智能表现得更好。









