选自The Next Platform
作者:Paul Teich
机器之心编译
参与:Nurhachu Null、黄小天
在最近的
2017 Google I/O 大会上
,谷歌发布了 TPU2(第二代 TensorFlow 处理单元);近日,TIRIAS Research 的一位顶尖技术专家和首席分析师 Paul Teich 在 Nextplatform 发表文章,对 TPU2 机器学习集群做了深度揭秘,提出了一些不同观点,比如他认为 TPU2 是内部专属产品,Google 不太可能出售基于 TPU 的芯片、主板或者服务器。机器之心对该文进行了编译,原文链接请见文末。
正如我们之前报道的,谷歌在不久之前的 Google I/O 大会上发布了它的第二代 TensorFlow 处理单元 (TPU2)。谷歌将其称为新一代的「谷歌云 TensorFlow 处理单元」,但是除了几张彩色图片之外,并没有提供多少关于 TPU2 芯片以及使用 TPU2 的系统性信息。一图胜千言,所以在这篇文章中我们将深入地挖掘这些图片,并且基于图片以及 Google 提供的一些少量细节来给出我们的想法。
首先,Google 不太可能出售基于 TPU 的芯片、主板或者服务器——TPU2 是 Google 内部专属的产品。Google 仅仅会提供通过 TensorFlow 研究云 (TRC) 来提供对 TPU2 硬件的直接访问,TRC 是一个「高度选择性」的计划,被设计来让研究者通过 Google 计算引擎云 TPU Alpha 计划来共享他们在 TPU2 可以加速的代码类型上的新发现,我们猜测 Google 计算引擎云 TPU Alpha 计划也是具有高度选择性的,因为两者共享同一个注册主页。
谷歌设计 TPU2 来专门加速其面向消费者的软件背后的深度学习负载,例如搜索、地图、语音识别以及自动驾驶训练之类的研究项目。我们关于 Google 对 TRC 的目标的粗略解读是:谷歌希望募集一个研究社区来发掘可以在 TPU2 超级网格上进行扩展的负载。谷歌表示,TRC 计划开始的时候规模会比较小,但是会随着时间的推移而扩大。我们其他人 (上述研究社区之外的人) 将无法直接访问 TPU2,直到谷歌的研究推广发现更多通用的应用,并且 Google 将 TensorFlow 硬件实例作为谷歌云平台公共云中的基础设施。
Google 设计了新颖的用于深度学习推理和分类任务的 TPU——运行早已在 GPU 上训练好的模型。TPU 是通过两个 PCIe 3.0 x8 的边缘连接器连接到主板上的协处理器 (如下图 A、B 中左下角所示),总共有 16GB/s 的双向带宽。TPU 的功耗达到了 40 瓦,在 PCIe 电源规格之内,并为 8 位整数操作提供每秒 92 次 tera 操作 (TOPS),为 16 位整数提供每秒 23 次 teraflops。为了进行比较,Google 表明 TPU2 大概在 16 位浮点数上能够提供峰值为 45 tera 浮点操作的性能。
TPU 并没有内置的调度功能,也不能被虚拟化。它是一个直接连在服务器主板上的简单矩阵协处理器。

图:谷歌的第一代 TPU 卡:A,没有散热片;B,有散热片。
Google 从没有说过把多少块 TPU 连接到主板上会导致主板的处理能力或者 PCIe 的吞吐量过载。协处理器需要主机以任务设置、拆分以及管理数据传入和传出 TPU 的带宽形式给予大量关照。协处理器仅做一件事,但是它们被设计得将那一件事做得很好。
Google 已将其投入使用的 TPU2 设计成四机架机柜,Google 称其为 pod。机柜是对于一组相关联的工作负载的标准机架配置(从半机架到多机架)。机柜有助于大型数据中心的拥有者更容易、更经济地进行购买、安装以及部署。例如,微软的 Azure Stack 标准半机架将会是一个机柜。
四机架机柜大小主要取决于 Google 正在使用的电缆类型和全速运行的最大铜线运行长度。下图显示了机柜的高层次组织。
我们首先注意到的是,Google 通过两根电缆将每个 TPU2 板连接到一个服务器处理器板。有可能 Google 将每个 TPU2 板连接到两个不同的处理器板,但是 Google 又不像也不希望使这个拓扑的安装、编程和调度变得混乱不堪。如果在服务器主板和 TPU2 板之间存在一对一的连接,那么就会简单很多。
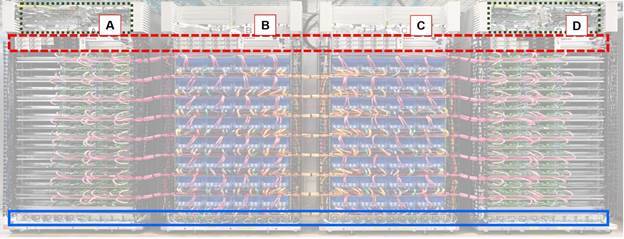
Google TPU2 的机柜 :A 是 CPU 机架,B 是 TPU2 机架,C 是 TPU2 机架,D 是 CPU 机架; 实线方框(蓝色):机架不间断电源(UPS); 虚线框(红色)是电源;;和点线框(绿色):机架式网络交换机和机架式交换机的顶部
Google 展示了 3 张不同的 TPU2 的机柜的照片,所有三张照片的配置和布线看起来都一样。TPU2 布线的炫目的颜色组织有助于进行这一比较。

三个 Google TPU2 机柜
Google 公布了 TPU2 板的顶部视图,以及该板的前面板连接器的特写。TPU2 的四个板象限中共享板上配电系统。我们认为四个 TPU2 板象限也通过一个简单的网络交换机共享网络连接。每个板象限看起来像是一个独立的子系统,并且这四个子系统在电路板上没有彼此连接。

TPU2 板的顶视图:A 是四个带有散热片的 TPU2 芯片;B 是每个 TPU2 的两根 25GB/s 的 BlueLink 电缆;C 是每个板的两条全向路径架构(OPA)电缆;;D 是电源连接器的背面,E 最有可能是网络交换机
前面板连接看起来像一个 QSFP 网络连接器,它的两侧有四个正方形的连接器,这是我以前没有看到的。IBM BlueLink 规范为最小吞吐率为 25 GB/s 的配置 (「子链路」) 中的每个方向 (总共 16 个通道) 定义了 8 个 200 Gb /s 的信号通道。Google 是 OpenCAPI 的成员,也是 OpenPowerFoundation 的创始成员,所以 BlueLink 是行得通的。

TPU2 前面板的连接
电路板正面中心的两个连接器看起来像带有铜双绞线的 QSFP 式连接器,而不是光纤。这就提供了两个选择——10 Gb/s 的以太网或 100 Gb/s 的英特尔全向路径架构(OPA)。两个 100 Gbps 的 OPA 链路可以组合成一个 25 GB/s 的聚合双向带宽,这与 BlueLink 速度是相匹配的,所以我们认为它是全向路径。
这些铜缆、BlueLink 或 OPA 都不能在最大信号速率下运行超过 3 米或 10 英尺。它以 3 米的物理跨距将 CPU 和 TPU2 板之间的互连拓扑结合在一起。Google 使用彩色电缆;而我的猜测是,这使组装更容易,而且没有布线错误。请参见上图中最前面连接器下方的电缆颜色的贴纸。我们觉得,颜色编码是 Google 打算大规模部署这些 TPU2 机柜的标志。
白色电缆很有可能是 1 Gb /秒以太网系统管理网络。我们没有看到 Google 可以将管理网络连接到照片中的 TPU2 板。但是,基于白色电缆的路由,我们可以假设 Google 从后端把管理网络连接到处理器板。也许处理器板通过 OPA 连接来管理和评估 TPU2 板的健康状况。
Google 的 TPU2 机架机柜具有双边对称性。在下图中,我们翻转了处理器机架 D 以将它与处理器机架 A 进行比较。这两个机架相同但又互为镜像。之后的图,很明显,机架 B 和 C 也是互为镜像的。

将两个 CPU 机架与翻转的机架 D 进行比较

将两个 TPU 机架与翻转的机架 C 进行比较
Google 的照片中没有足够可见的连线来确定精确的互连拓扑,但它看起来确实像某一种超网格互连(hyper-mesh interconnect)。
我们相信,CPU 板是标配英特尔 Xeon 双插槽主板,适合 Google 1.5 英寸服务器的外形尺寸。它们是当前一代主板设计,考虑到它们有 OPA,它们可能是 Skylake 板 (参见下面的功耗讨论)。我们相信它们是双插座主板,仅仅是因为我还没有听说过多少单插座主板是通过英特尔供应链的任何一部分供应的。但是随着新的市场进入者,例如如具有「Naples」Epyc X86 服务器芯片的 AMD,和具有 Centriq ARM 服务器芯片的 Qualcomm 使用的正是单插座配置,这种情况可能会有所改变。
我们认为 Google 将每个 CPU 板连接到一个 TPU2 板上,使用两条 OPA 电缆实现了 25 GB/s 的总带宽。这种一对一的连接解决了 TPU2 的一个关键问题——Google 以 TPU2 芯片与 Xeon 插座的比例为 2:1 的方式设计了 TPU2 机柜。也就是说,每个双插槽 Xeon 服务器都有四个 TPU2 芯片。
TPU2 加速器与处理器的这种紧密耦合与深度学习训练任务中 GPU 加速器的 4:1 至 6:1 的典型比例大不相同。低 2:1 的比例表明,Google 保留了原始 TPU 中使用的设计理念:「与 GPU 相比,TPU 在理念上更接近于 FPU(浮点单元) 的协处理器。」处理器在 Google 的 TPU2 架构中仍然有很多工作要完成,但它正在将所有的矩阵数学卸载到 TPU2 上去。
我们看不到 TPU2 机柜中的任何存储。大概这是在下图中大束蓝色光缆存在的原因。数据中心网络连接到 CPU 板,但是并没有光纤电缆连接到机架 B 和 C 上,同样,TPU2 板上没有网络连接。

很多光纤带宽连接到 Google 数据中心的其余部分
每个机架有 32 个计算单位,无论是 TPU2 还是 CPU 都是如此。因此,每个机柜中有 64 个 CPU 板和 64 个 TPU 板,共有 128 个 CPU 芯片和 256 个 TPU2 芯片。
谷歌表示,其 TRC 包含 1000 个 TPU2 芯片,但是这一数字略有下降。四个机柜包含 1024 个 TPU2 芯片。因此,四个机柜是 Google 已部署的 TPU2 芯片数量的下限。从 Google I / O 大会期间发布的照片中可以看到三个(也可能是四个)机柜。
不清楚处理器和 TPU2 芯片是如何通过一个机柜进行联合,以便 TPU2 芯片可以在超网格中跨链接有效地共享数据的。但我们几乎可以肯定,TRC 不能跨越四个机柜(256 个 TPU2 芯片)中的一个以上的单个任务。原始 TPU 是一个简单的协处理器,因此处理器处理所有数据流量。在这种架构中,处理器通过数据中心网络从远程存储器访问数据。
关于机柜模型也没有很多的描述。TPU2 芯片可以在 OPA 上使用远程直接存储器访问(RDMA)从处理器板上的内存中加载自己的数据吗?这好像是可以的。处理器板似乎也可能在机柜上执行相同操作,创建大型共享内存池。该共享内存池不会像 Hewlett Packard Enterprise 的机器共享内存系统原型中的内存池那么快,但是使用 25 GB / s 的链接,它的速度也不会太慢,内存依旧很大,这是在两位 tb(digit terabyte)范围内的(每个 DIMM 16 GB,每个处理器有八个 DIMM,每个板有两个处理器,64 个板产生 16 TB 的内存)。
我们推测,在一个机柜上安排一个需要多个 TPU2 的任务看起来像这样:
-
处理器池应该有一个机柜的超网格拓扑图,其中 TPU2 芯片可用于运行任务。
-
处理器组可能联合编程每个 TPU2 以明确地连接位于两个相连接的 TPU2 芯片之间的网格。
-
每个处理器板将数据和指令加载到其配对的 TPU2 板上的四个 TPU2 芯片上,包括网状互连的流量控制。
-
处理器在互连的 TPU2 芯片之间同步引导任务。
-
当任务完成时,处理器从 TPU2 芯片收集所得到的数据(该数据可能已经通过 RDMA 存储在全局存储器池中),并将 TPU2 芯片标记为可用于另一任务。
这种方法有一个优点,那就是:TPU2 芯片不需要理解多任务、虚拟化或多租户——处理器将所有的这些任务都跨机柜解决了。
这也意味着如果 Google 曾经提供 Cloud TPU 实例作为其谷歌云平台自定义机器类型 IaaS 的一部分,该实例将必须包括处理器和 TPU2 芯片。
还不清楚的是,工作负载能否可以跨机柜进行缩放,并保留超级网格的低延迟和高吞吐量。虽然研究人员可能可以通过 TRC 访问 1024 个 TPU2 芯片中的一些,但跨机柜进行扩展工作负载看起来仍是一个挑战。研究人员可能有能力连接多达 256 个 TPU2 芯片的集群,这足以令人印象深刻,因为云 GPU 连接目前正在扩展到 32 个互连设备(通过 Microsoft 的 Olympus HGX-1 设计)。
Google 的第一代 TPU 在负载下消耗 40 瓦特,同时以 23 TOPS 的速率执行 16 位整数矩阵乘法。Google 将 TPU2 的运行速度提高到 45 TFLOPS,同时通过升级到 16 位浮点运算来提高计算复杂度。根据一个粗略的经验法则来看的话,这至少是两倍的功耗——如果除了将速度提高两倍以及转移到 FP16 之外,什么也不做的话,TPU2 必须消耗至少 160 瓦。散热器尺寸显示出更高的功耗,某处甚至高于 200 瓦特。
TPU2 板具有位于 TPU2 芯片顶部的巨大散热片。它们是多年来我看到的最高的风冷散热片。它们具有内部密封环液体循环。在下图中,我们将 TPU2 散热片与过去几个月看到的最大的可比散热片进行相比较。

散热片遍历:A 是四路 TPU2 主板侧面视图,B 为双 IBM Power9「Zaius」主板,C 为双 IBM Power8「Minsky」主板,D 为双英特尔 Xeon Facebook「Yosemite」主板,E 为 Nvidia P100 SMX2 模块与散热片和 Facebook「Big Basin」主板
这些散热片的尺寸大多「每个超过 200W」。很容易看出,它们比原始 TPU 上的 40 瓦散热片大得多。这些散热片填补了两个 Google 垂直的 1.5 英寸外形尺寸单元的空缺,因此它们几乎高达三英寸。(Google 机架单元高度为 1.5 英寸,比行业标准 1.75 英寸 U 型高型号矮一点)。
这是一个很好的选择,每个 TPU2 芯片还有更多的内存,这有助于提高吞吐量并增加功耗。
此外,Google 从单芯片 TPU 芯片(PCI-Express 插槽向 TPU 卡供电)转移到四路 TPU2 板设计共享双 OPA 端口和交换机,以及为每个 TPU2 芯片提供两个专用的 BlueLink 端口。OPA 和 BlueLink 都增加了 TPU2 板级功耗。
Google 的开放计算项目机架规格设备显示 6 千瓦、12 千瓦和 20 千瓦的电力输送配置文件; 20 千瓦的功率分配可以实现 90 瓦的 CPU 处理器插座。我们猜测,使用 Skylake 代 Xeon 处理器和处理大部分计算负载的 TPU2 芯片,机架 A 和 D 可能使用 20 千瓦电源。
而机架 B 和 C 就是另一个不同的故事了。功率输送为 30 千瓦,能够为每个 TPU2 插座提供 200 瓦的功率输送;每个机架 36 千瓦将为每个 TPU2 插座提供 250 瓦的功率输送。36 千瓦是一种常见的高性能计算能力传输规范。我们认为,每个芯片 250 瓦功耗也是 Google 愿意为上述巨大的 TPU2 散热片支付的唯一原因。因此,单个 TPU2 机柜的功率传输可能在 100 千瓦至 112 千瓦范围内,并且可能更接近较高数量。
这意味着 TRC 在满负荷运行时消耗将近 100 兆瓦的功率。虽然部署 4 个机柜成本昂贵,但却是一次性的费用,并不占用大量的数据中心空间。然而,半数兆瓦的电力是大量经营费用,持续资助学术研究,即使是一家 Google 规模的公司。如果 TRC 在一年内仍然运行,这表明 Google 正在认真研究其 TPU2 的新用例。
TPU2 机柜包含 256 个 TPU2 芯片。每个 TPU2 芯片的性能为 45 teraflops,每个机柜产生总共 11.5 petaflops 的深度学习加速器的性能。这是令人印象深刻的,即使它确实是 FP16 的高峰表现。深度学习训练通常需要更高的精度,因此 FP32 矩阵乘法性能可能是 FP16 性能的四分之一,或者每个机柜约为 2.9 petaflops,整个 TRC 为 11.5 FP32 petaflops。
在峰值性能方面,这意味着在整个机柜上的 FP16 操作(不包括 CPU 性能贡献或位于机柜之外的存储),每瓦跳跃到 100 到 115 gigaflops。
英特尔公布了双插槽 Skylake 代 Xeon 核心计数和功耗配置后,可以计算 Xeon 处理器的 FP16 和 FP32 性能,并将其增加到每瓦特的总体性能。
关于 Google 的 TPU2 机柜表现还没有足够可靠的信息将其与像英伟达的「Volta」这样的新一代商业加速器产品进行比较。架构的差别太大了,所以无需对同一任务中的两个架构进行基准测试。比较峰值 FP16 的性能就像将两台具有不同处理器、存储器和只基于处理器频率的图形选项的 PC 的性能进行比较。
也就是说,我们认为真正的竞争不在芯片层面。真正的挑战是将计算加速器比例扩大百亿兆。英伟达公司正在采用 NVLink 作为第一步,以从处理器上获得更大的加速器独立性。英伟达正在将它的软件基础设施和工作负载从单一 GPU 扩展到 GPU 集群。
Google 选择将其原始 TPU 扩展为直接连接到处理器的协处理器。TPU2 还可以进行扩展,作为一个加速比为 2:1 的直接加速器去处理任务。然而,TPU2 的超网格编程模型貌似还没有扩展得很好的工作负载。但是,Google 正在寻求第三方帮助来发掘可以使用 TPU2 架构进行扩展的工作负载。

原文链接:https://www.nextplatform.com/2017/05/22/hood-googles-tpu2-machine-learning-clusters/
更多有关GMIS 2017大会的内容,请点击「阅读原文」查看机器之心官网 GMIS 专题↓↓↓






