
数据挖掘入门与实战 公众号: datadw
文本分析使用愈来愈广泛,包括对新闻、电视剧、书籍、评论等等方面的文本挖掘并进行分析,可以深入找到表面文字看不到的细节。
介于《人民的名义》这部剧这么火,本人以此为基础,通过对知乎上网友提出的问题进行爬取,并搜集到每一问题的关注、浏览数,进行分析。在未登录的情况下,找到知乎——《人民的名义》主题网页下的等待回答——全部问题(见下图),时间截止到2017年4月15日,地址为:
https://www.zhihu.com/topic/20047590/questions
。
(在登录状态下,可以显示更多信息,但是需要设置知乎登录函数,同时登录之后可能反爬虫机制会严格)。
每一个问题对应一个链接,点击进去会有该问题的关注者、浏览者等相关信息,如果有人回答还会有回答人数等等,如图。
(1)抓取问题信息
基于上述构造,本文编写爬虫函数来爬取这些信息,第一步先通过《人民的名义》主题网页抓取每一个问题的链接,第二步再通过每一个链接,抓取每一个问题的内容、关注者、浏览者信息。
from bs4 import BeautifulSoup
import urllib.request
import time,re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import socket
socket.setdefaulttimeout(20) #对整个socket层设置超时时间。
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0')
page = urllib.request.urlopen(req) # 模仿浏览器登录
txt = page.read().decode('utf-8')
soup = BeautifulSoup(txt, 'lxml')
return soup
#封装问题的链接
page_url =[]
for num in range(1,45):
url = 'https://www.zhihu.com/topic/20047590/questions?page={}'.format(num)
soup = url_open(url)
urllist = soup.find_all(attrs={'class': 'question-item-title'})
time.sleep(10)
for i in urllist:
page =i.a['href']
page_url.append('https://www.zhihu.com' + page)
def get_info(page_url):
soup = url_open(page_url)
titles= soup.find_all(attrs= {'class':'QuestionHeader-title'})[0].get_text()
focus = soup.select('div.NumberBoard-value')[0].get_text()
reviews = soup.select('div.NumberBoard-value')[1].get_text()
frame = pd.DataFrame([titles, focus, reviews],
index=['titles', 'focus', 'reviews']) # 转入数据列表
frame = frame.T
return frame
(2)将信息转入dataframe数据结构,并进行统计分析
在构建get_info(page_url)的基础上,采用map抓取信息,并装入dataframe数据结构中。
socket.setdefaulttimeout(20)
frame_list = list(map(get_info,page_url))
time.sleep(10)
i, j, k,= [], [], [],
[(i.extend(x['titles'])) for x in frame_list]
[(j.extend(x['focus'])) for x in frame_list]
[(k.extend(x['reviews'])) for x in frame_list]
df = pd.DataFrame([i, j, k, l], index=['titles', 'focus', 'reviews'])
df1 = df.T
print(df1)
最终抓取到了800多条问题,首先对df1数据按照关注者的数量“focus”进行排序,并筛选出关注者最高的前10个问题。
df1['focus'] = df1['focus'].astype('int')
df1['reviews'] = df1['reviews'].astype('int')
df2 = df1.sort(columns='focus',ascending=False)
df3=df2.iloc[0:10,0:2] #loc通过标签选择数据,iloc通过位置选择数据
df3
得到结果为:
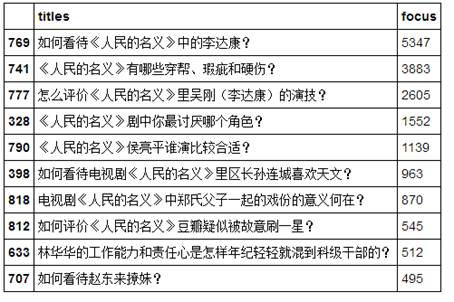
可以看到,知乎网友关注较多的还是剧中的角色,特别是达康书记——该剧目前最火也最有话题性的人物,其次该剧一些争议性的话题,包括穿帮与硬伤等,对陆毅扮演侯亮平的演技,以及比较令人讨厌的角色(郑氏父子、林华华等)的讨论,赵东来撩妹作为近期比较火的一个话题也上了top10.
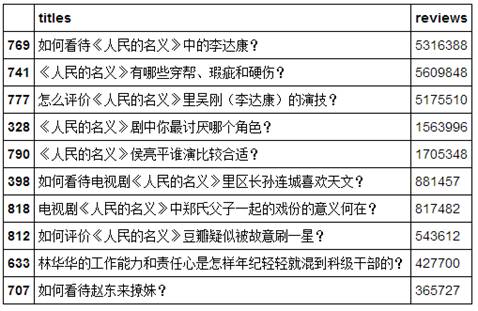
(3)浏览者最多的问题
对df1数据按照浏览者的数量“reviews”进行排序,并筛选出关注者最高的前10个问题。
df4 = df1.sort(columns='reviews',ascending=False)
df5=df2.iloc[0:10,[0,2]]
df5
可以看到浏览者的top10与关注者基本一致。
Paste_Image.png
(4)对问题的文本分析
对这800多个问题进行分本分析与挖掘,以便深入分析网友提问的关注角度。
titles=list(df1['titles']) #将titles列专门提取出来,并转化为列表形式
titles1=''.join(titles) #将列表形式转化为文本
import jieba #使用jieba进行分词
blacklist = [u'如何', u'评价', u'人民的名义', u'应',u'是', u'也', u'上', u'后', u'前', u'为什么', u'再', u',',
u'以及', u'因为', u'从而', u'但', u'像',u'更', u'用', u'“', u'这', u'有', u'在', u'什么', u'都',u'是否',u'一个',u'是不是',
u'”', u'还', u'使', u',', u'把', u'向',u'中', u'新', u'对', u' ', u' ', u')', u'、', u'。', u';',
u'%', u':', u'?', u'(', u'的',u'和', u'了', u'湖南卫视', u'将', u'到', u'',u'人民',u'名义',u'电视剧',u'怎么',
u'从', u'年', u'今天', u'要', u'并', u'n', u'《', u'为', u'月', u'号', u'日', u'大',u'如果',u'哪些',
u'看待', u'怎样', u'还是', u'应该',u'这个', u'这么',u'没有',u'这部',u'哪个', u'可以',u'有没有']
#设置blacklist黑名单过滤无关词语
hist = {} #将词语转入字典
for word in jieba.cut(titles1): #jieba分词
if word in blacklist: #采用黑名单过滤
continue
if len(word) continue
hist[word] = hist.get(word, 0) + 1 #相同词语进行汇总统计
hist
根据分词结果,排序找到知乎网友提问问题中使用较多的词,这是从另一个角度分析知乎网友对《人民的名义》关注的相关点。
zhfont = matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttf')#载入字体
# 对词频排序
hist_sorted = sorted(hist.items(), key=lambda d: d[1], reverse=True)
# 取频率最高10个词绘制曲线图
x = range(15)
y = [hist_sorted[i][1] for i in range(15)]
plt.bar(x, y, width = 0.35,align='center',color = 'c',alpha=0.8)
plt.xticks(x, [hist_sorted[i][0] for i in range(15)],fontproperties=zhfont,size='small',rotation=30)
for a,b in zip(x,y):
plt.text(a, b+0.05, '%.0f' % b, ha='center', va= 'bottom',fontsize=10)
plt.title(u"《人民的名义》词频分析",fontproperties=zhfont)
plt.ylim(0,70)
plt.xlim(0.5,14.5)
plt.grid() #网格线
plt.show()
得到图形:
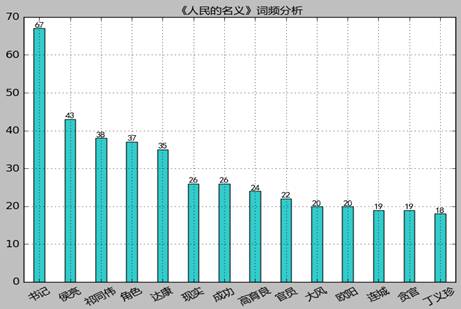
Paste_Image.png
从上图来看,书记、达康这个最火的话题仍然是提问者比较关注的,但与前边关注者统计不同的是,提问者对祁同伟的关注度较高,其次蔡成功(成功)、高育良、欧阳菁、丁义珍等人也有一定的关注度,大风集团也有一定的关注度。
另外,问题中提到“现实”这个词语的有这样一些:
现实中有像易学习这样的领导干部吗?
现实里有几个人可以做到像李达康一样不为自己人谋福利?
现实中有没有像易学习一样的基层干部?
现实之中真的有像李达康这样的书记吗?
现实中李达康这样的领导是否值得追随?
如何看待最高检拍摄取得巨大得成功?现实情况如确实如此,是否应该怒其不争?
侯亮平如果在现实官场中,际遇会如何?
……
基本上都是将剧中人物、事件与现实对照,探究该剧现实的可能性。
在过滤无关词语的基础上,
text = []for word in jieba.cut(titles1):
if word in blacklist: continue
text.append(word)
text1=''.join(text)
text1wordcloud = WordCloud(font_path="C:/Windows/Fonts/msyh.ttf",
background_color="black").generate(text1)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
绘制词云图如下:

可以看到,侯亮平、李达康等关注度较高,其次对拍摄方面有一些关注,比如镜头、手法、拍摄、好看,对受贿、贪官、行贿、利益等腐败问题关注度也比较高。另外,由于送审样片的流出,对送审的关注度也较高。
(5)总结
综合看来,从知乎问题关注者、浏览者的角度来看,所关注的问题基本上是目前网友也比较关心的问题,比如达康书记、陆毅的演技、讨厌的角色(郑氏父子、林华华)、赵东来撩妹、豆瓣刷一星等等。
从提问者关注的角度来看,对更多的角色有所关注,比如祁同伟、高育良、蔡成功等等,另外还关注拍摄技巧、腐败问题、与现实的对照性等等。无论是关注者的角度还是提问者的角度,达康书记是最高的关注点。
同时,从上述文本分析来看,由于jieba分词的精确性,在初步的文本挖掘中,还是存在着欠缺的地方,比如部分词语不完整或遗漏,这需要更精确的文本挖掘方式,比如设置《人民的名义》词库,或者采用机器学习算法来智能地深入分析
。http://www.jianshu.com/p/817c4829fdc5
数据挖掘入门与实战
搜索添加微信公众号:datadw










