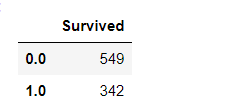正文
一.简介
发展由来:
简要说明
二.各图运用
安装
:
pip install plotly
下面均在Jupyter Notebook中运行
数据源
:
import plotly
import plotly. express as px
import plotly. graph_objects as go
import plotly. io as pio
import pandas as pd
import numpy as np
df= px. data. gapminder( )
df. head( )
运行结果:
1.柱状图
df_country= df[ df[ 'country' ] == 'China' ]
fig= px. bar( df_country,
x= 'year' ,
y= 'pop' ,
text= 'pop' ,
color= 'lifeExp' ,
hover_name= 'year' ,
)
fig
运行结果:
fig. update_layout( title_text= '中国人口变迁史' ,
title_x= .5 ,
font= dict ( family= 'simsun' ,
size= 14 ,
color= '#1d39c4' )
)
fig. update_layout( xaxis_title= '年份' ,
yaxis_title= '人口数量' )
fig
运行结果:
fig. update_traces(
textposition= 'outside' ,
texttemplate= '%{text:,.2s}' )
fig
运行结果:
fig. update_traces( customdata= df[ [ 'lifeExp' , 'gdpPercap' ] ] )
fig. update_traces( hovertemplate= 'Year: %{x}<br><br> Population: %{y}<br> Life Expectation: %{customdata[0]:,.2f}<br>GDP per capital: %{customdata[1]:,.2f}' )
fig. update_xaxes( tickangle= - 45 , tickfont= dict ( family= 'arial' , size= 12 ) )
fig
运行结果:
fig. update_layout( bargap= .4 ,
uniformtext_minsize= 8 ,
uniformtext_mode= 'show' )
fig. add_annotation( x= '1982' ,
y= 1000281000 ,
text= '突破10亿' ,
font= dict ( color= 'red' ) )
fig. update_annotations( dict ( xref= 'x' ,
yref= 'y' ,
showarrow= True ) ,
arrowcolor= 'red' ,
arrowhead= 4 )
fig. show( )
运行结果:
2.散点图
df_2007 = df[ df[ "year" ] == 2007 ]
df_2007
运行结果:
px. scatter( df_2007,
x= "gdpPercap" ,
y= "lifeExp" ,
color= "continent"
)
运行结果:
3.冒泡散点图
px. scatter( df_2007,
x= "gdpPercap" ,
y= "lifeExp" ,
color= "continent" ,
size= "pop" ,
size_max= 60 ,
hover_name= "country"
)
运行结果:
4.旭日图
px. sunburst( df_2007,
path= [ 'continent' , 'country' ] ,
values= 'pop' ,
color= 'lifeExp' ,
hover_data= [ 'iso_alpha' ]
)
运行结果:
5.地图图形
px. choropleth(
df,
locations= "iso_alpha" ,
color= "lifeExp" ,
hover_name= "country" ,
animation_frame= "year" ,
color_continuous_scale= px. colors. sequential. Plasma,
projection= "natural earth"
)
运行结果:
三.实战案例
使用泰坦里克号生存为例
import plotly
import plotly. express as px
import plotly. graph_objects as go
import plotly. io as pio
import pandas as pd
import numpy as np
path1= './dataSet/test.csv'
path2= './dataSet/train.csv'
test= pd. read_csv( path1)
train= pd. read_csv( path2)
data= pd. concat( [ test, train] )
运行结果:
df1= pd. DataFrame( data= data[ 'Survived' ] . value_counts( ) )
df1
运行结果:
fig1= px. bar( df1, y= 'Survived' , text= 'Survived' , color_discrete_sequence= [ [ '#B4C7EC' , '#14A577' ] ] )
fig1. update_layout( title= 'Survival Status in Titanic' ,
title_x= .5 ,
xaxis_title= 'Passenger survival status' ,
yaxis_title= 'Numbers' ,
font= dict ( family= 'arial' , color= '#000000' , size= 12 ) ,
bargap= .5 )
fig1. update_xaxes( tick0= 0 ,
dtick= 1 ,
tickvals= [ 0 , 1 ] ,
ticktext= [ 'Drowned' , 'Suvived' ] ,
tickfont= dict ( family= 'arial' , color= '#000000' , size= 14 ) )
fig1. update_yaxes( range = [ 0 , 650 ] )
fig1. update_traces( textposition= 'outside' ,
textfont_size= 16 ,
textfont_color= [ '#8C1004' , '#007046' ] )
fig1. show( )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
运行结果:
df_sex= pd. DataFrame( data= data. groupby( [ 'Survived' , 'Sex' ] ) [ 'PassengerId' ] . count( ) )
df_sex= df_sex. reset_index( )
df_sex
运行结果:
fig_sex1= px. bar( df_sex, x= 'Survived' , y= 'PassengerId' , color= 'Sex' , barmode= 'group' , text= 'PassengerId' ,
color_discrete_map= { 'female' : '#F17F0B' , 'male' : '#0072E5' } )
fig_sex1. update_traces( textposition= 'outside' ,
textfont_size= 14 ,
textfont_color= [ '#8C1004' , '#007046' ] )
fig_sex1. update_xaxes(
tickvals= [ 0 , 1 ] ,
ticktext= [ 'Drowned' , 'Suvived' ] ,
tickfont= dict ( family= 'arial' ,
color= '#000000' ,
size= 14 ) )
fig_sex1. update_layout( title= 'Overall Suvival in terms of Sex' ,
title_x= .5 ,
bargap= .35 ,
xaxis_title= '' ,
yaxis_title= 'Numbers of Passengers' ,
font= dict ( family= 'arial' ,
color= '#000000' ,
size= 13 ) )
fig_sex1. update_yaxes( range = [ 0 , 500 ] ,
dtick= 100 )
fig_sex1. show( )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
运行结果:
fig_sex2= px. bar( df_sex, x= 'Sex' , y= 'PassengerId' , facet_col= 'Survived' , text= 'PassengerId' ,
color_discrete_sequence= [ [ '#F17F0B' , '#0072E5' ] ] )
fig_sex2. update_traces( textposition= 'outside' ,
textfont_size= 14 , )
fig_sex2. update_layout( title= 'Overall Suvival in terms of Sex' ,
title_x= .5 ,
bargap= .35 ,
yaxis_title= 'Numbers of Passengers' ,
font= dict ( family= 'arial' ,
color= '#000000' ,
size= 13 ) ,
)
fig_sex2. update_layout( xaxis= dict ( title= '' ) ,
xaxis2= dict ( title= '' ) )
fig_sex2. update_yaxes( range = [ 0 , 500 ] ,
dtick= 100 )
fig_sex2. for_each_annotation( lambda a: a. update( text= a. text. replace( 'Survived=0.0' , 'Drowned' ) ) )
fig_sex2. for_each_annotation( lambda a: a. update( text= a. text. replace( 'Survived=1.0' , 'Suvived' ) ) )
fig_sex2. update_layout( annotations= [ dict ( font= dict ( size= 16 ,
color= '#002CB2' ) ) ] )
fig_sex2. show( )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
运行结果:
df_pclass= pd. DataFrame( data= data. groupby( [ 'Survived' , 'Pclass' ] ) [ 'PassengerId' ] . count( ) )
df_pclass= df_pclass. reset_index( )
df_pclass
运行结果:
fig_sex1= px. bar( df_pclass, x= 'Survived' , y= 'PassengerId' , color= 'Pclass' , barmode= 'group' , text= 'PassengerId' ,
color_discrete_map= { '1' : '#F17F0B' , '2' : '#0072E5' , '3' : '#8C1004' } )
fig_sex1. update_traces( textposition= 'outside' ,
textfont_size= 14 ,
textfont_color= [ '#8C1004' , '#007046' ] )
fig_sex1. update_xaxes(
tickvals= [ 0 , 1 ] ,
ticktext= [ 'Drowned' , 'Suvived' ] ,
tickfont= dict ( family= 'arial' ,
color= '#000000' ,
size= 14 ) )
fig_sex1. update_layout( title= 'Overall Suvival in terms of Pclass' ,
title_x= .5 ,
bargap= .35 ,
xaxis_title= '' ,
yaxis_title= 'Numbers of Passengers' ,
font= dict ( family= 'arial' ,
color= '#000000' ,
size= 13 ) )
fig_sex1. update_yaxes( range = [ 0 , 500 ] ,
dtick= 100 )
fig_sex1. show( )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
运行结果: