十年前,Netfliex 发起了 Netflix 奖公开竞赛,目标在于设计最新的算法来预测电影评级。竞赛历时 3 年,很多研究团队开发了各种不同的预测算法,其中矩阵分解技术因效果突出从众多算法中脱颖而出。
这篇文章有两个目的:
我试图让本文的数学内容通俗易懂,但不会过于简化,同时我也尽量避免枯燥的语句。我希望本文对机器学习初学者有所帮助,对有经验的人而言有所见解。
这篇文章分为四部分。第一部分清楚地定义了将阐述的问题,提出了一些对 PCA 的见解;在第二部分,我们将回顾 SVD,看看它是如何对评级建模的;第三部分展示了如何将 SVD 知识应用于评级预测中,并派生出一个基于矩阵分解的预测算法;在最后一部分,我们将调用 Surprise 库,用 Python 代码实现一个矩阵分解算法。
在这里,我们将谈论的问题是评级预测问题。我们的数据是评级历史数据,即用户对项目的评级,值区间是 [1,5]。我们可以把数据放在一个稀疏矩阵 R 中:

矩阵的每一行对应一个给定用户,每一列对应一个给定项目。譬如,在上面的矩阵中,Alice 对第一个项目的评级是 1,Charlie 对第三个项目的评级是 4。在我们的问题中,我们将认为项目是电影,在后面会交替使用“项目”和“电影”这两个术语。
矩阵 R 是稀疏的(99% 以上的内容是缺失的),我们的目标是预测那些缺失的内容,即问号处的值。
有很多不同的技术可用于评级预测,在这里我们将分解矩阵 R。该矩阵分解与 SVD(Singular Value Decomposition,奇异值分解)是根本相关的。SVD 是线性代数的亮点之一。它的结果很美丽。如果有人告诉你数学很差劲,你可以向他们展示看看 SVD 能做什么。
这篇文章的目的在于解释如何能将 SVD 用于预测评级。但在我们进入第二部分的 SVD 之前,我们需要回顾一下什么是 PCA。PCA 只稍稍逊色于 SVD,但也仍然很酷。
让我们暂时忘记推荐问题。我们将用到 Olivetti 数据集,它是 40 个人的脸部灰度图像集,一共有 400 个图像。第一组 10 个人的图像如下:

每一个图像的大小是 64 x 64 像素。我们将扁平化每个图像,于是可以得到 400 个向量,每个向量里有 64 x 64 = 4096 个成员。我们可以将数据集表示为一个 400 x 4096 矩阵:

PCA(Principal Component Analysis,主成分分析)算法可以将 400 个这样的人展现为下面的图:

看起来很恐怖吧?
我们将这些人叫做主成分,他们所代表的脸部图像叫做特征脸部。可以用特征脸部做很多有趣的事情,如脸部识别或优化 tinder 匹配。它们之所以被叫做特征脸部,是因为它们实际是 X 的协方差矩阵的特征向量(这里我们不会给出细节,感兴趣的读者可以参看文末的参考文献)。
这里,我们获取了 400 个主成分,因为原始的矩阵 X 有 400 行(更确切的说,是因为 X 有 400 个评级)。你可能已经猜到,每一个主成分实际上是一个向量,与原始的脸部有着相同的维度,即有 64 x 64 = 4096 个像素。
我们会把这些图像叫做“令人毛骨悚然的图像”。现在,关于它们的一个惊人的事情是,它们可以恢复所有的原始面孔。
让我来解释下怎么回事。400 个原始脸部中的每一个(即矩阵的 400 个原始行中的每一行)可以表示为这些令人毛骨悚然的图像的(线性)组合。也就是说,我们可以将第一个原始脸部的像素值表示为第一个图像的一小部分,加上第二个图像的一小部分,再加上第三个图像的一小部分,等等,直到最后一个图像。这一方法对其他原始脸部也适用:它们都能被表示为每一个令人毛骨悚然的图像的一小部分。我们可以将其表示为数学的方式如下:

我们做了一个动态图,正是对这些数学公式的翻译:gif 的第一帧是第一个令人毛骨悚然的图像的贡献,第二帧是第二个令人毛骨悚然的图像的贡献,等等,直到最后一个。
如果你想尝试重现这些动态图,我写了一个 Python notebook(
http://nbviewer.jupyter.org/github/NicolasHug/nicolashug.github.io/blob/master/assets/mf_post/creepy_guys.ipynb
)。
注意:用那些令人毛骨悚然的图像来表示原始脸部,这一点并没有什么特别的。我们可以随机选取 400 个独立的向量(每个向量是 64 x 64 = 4096 像素),仍然能够重现这些脸部。降低维度是让这些令人毛骨悚然的图像在 PCA 中变得特别的原因,我们将在第三部分讨论这个问题。
实际上,我们对这些令人毛骨悚然的图像有些过于严厉了。它们其实并不恐怖,反而很典型。PCA 的目标就在于揭示典型的向量,每一个图像代表着隐藏在数据下的一个特征。理想情况下,第一个图像将代表譬如一个典型的年长一些的人,第二个图像将代表一个典型的滑头滑脑的人,而其他图像可以代表一些如喜欢微笑的人、表情悲伤的人、有着大鼻子的人等等概念。有了这些概念,我们可以将脸部定义为或多或少年长、或多或少滑头滑脑、或多或少微笑,等等。实际上,PCA 所揭示的概念并没有那么清晰,没有一个清楚的语义能让我们像在这里一样把任何令人毛骨悚然的图像或典型图像相关联起来。但是,有一个重要的事实是,每一个图像捕获了数据的某一个特征。我们把这些特征叫做
潜在因子
(潜在,是因为它们一直在那里,我们只需要用 PCA 来揭示它们)。即每个主成分(令人毛骨悚然的或典型的图像)捕获一个特定的潜在因子。
到目前为止还是挺有趣的,但是我们其实是对用矩阵分解进行推荐感兴趣,对吧?那么我们的矩阵分解在哪里,它与推荐有什么关系? PCA 实际上是即插即用的方法,它适用于任何矩阵。如果矩阵包含图像,它将显示一些典型的图像,从而构建出所有原始图像。如果矩阵包含土豆,PCA 将显示一些可以恢复所有原始土豆的典型土豆。如果你的矩阵包含评分,那么接下来我们来看看怎么做到。
除非另有说明,我们的评级矩阵 R 是完全密集的,即没有缺失的内容。所有评分都是已知的。这当然不是实际推荐问题中的场景,但请先按这样假设。
我们的评级矩阵如下所示,行代表用户,列代表电影:
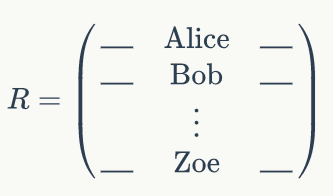
看起来是不是很熟悉? 我们没有用像素来表示每一行的脸部,相反,现在我们用评级来表示用户。就像之前 PCA 给出一些典型的图像,现在它将给我们一些典型的用户,或者一些典型的评价者。
在理想情况下,与典型用户相关的概念将具有明确的语义含义:我们将获得典型的动作电影迷、典型的浪漫电影迷、典型的喜剧迷,等等。实际上,典型用户背后的语义并没有被明确定义,但为了简单起见,我们假设它们如此(这不会改变任何东西,只是为了便于解释)。
于是,我们的每个初始用户(Alice,Bob 等)可以表示为典型用户的组合。例如,Alice 可以被定义为动作电影迷的一小部分、喜剧电影迷的一小部分、浪漫电影迷的一大部分,等等。至于 Bob,他可以更加热衷于动作电影:

该表示方法对所有用户都适用。(实际上,系数不一定是百分比,但表示成百分比更方便我们思考)。
如果我们对评级矩阵进行转置会发生什么?我们没有把用户当成行,而是把电影当作行,由评级定义如下:
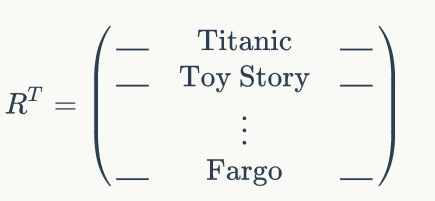
在这种情况下,PCA 不会显示典型的人脸或典型的用户,而是显示典型的电影。再次,我们将把典型的电影背后的语义意义相结合,这些典型的电影可以构造我们所有的原始电影。对所有其他电影也是如此。
我们来回顾一下第一部分的内容:
SVD 能为我们做什么呢?简而言之,SVD 是 R 和 R
T
上的 PCA。
SVD 能同时给出矩阵 U 和 M。你能同时拿到典型的用户和典型的电影。通过将 R 分解为三部分,SVD 给出 U 和 M。下面是矩阵分解表达式:
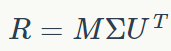
SVD 算法以矩阵 R 为输入,输出 M、Σ和 U,使得:
-
R 等于 MΣU
T
。
-
M 的列能重造 R 的所有列(我们已经知道了这一点)。
-
U 的列能重造 R 的所有行(我们已经知道了这一点)。
-
M 的列是正交的,U 的列也是正交的。主成分都是正交的。这实际上是 PCA(和 SVD)的一个及其重要的特征,但对于推荐而言我们并不关心(之后会讲到这点)。
-
Σ是一个对角矩阵(之后会讲到这点)。
我们可以基本总结上述所有这些点为:M 的列是跨越 R 的列空间的正交基,U 的列是跨越 R 的行空间的正交基。
当我们计算和使用评级矩阵 R 的 SVD 时,实际上,我们是在对评级进行特别的、有意义的建模。我们将在这里描述该建模。
简单起见,我们先忘记矩阵Σ:它是一个对角矩阵,所以它仅仅是充当 M 或 U
T
的标量。因此,我们将假装我们已经将其合并到其中的一个矩阵上了。我们的矩阵分解是:
现在,用这种分解,让我们来看看用户 u 对项目 i 的评级,我们将其表示为 r
ui
:
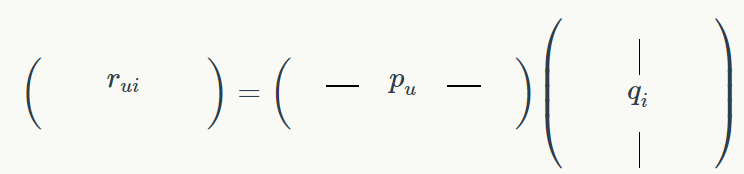
由于定义矩阵乘法的定义方式,r
ui
的值是两个向量的点积的结果:向量 p
u
,它是 M 的一行,特定于用户 u;向量 q
i
,它是 U
T
的列,特定于项目 i:
r
ui
=p
u
⋅q
i
,
其中⋅表示点积。是否还记得我们是如何定义用户和项目的?

那么,向量 p
u
和 q
i
的值恰好对应于我们分配给每个潜在因子的系数:
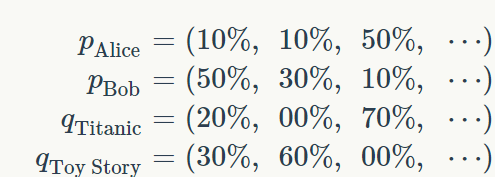
向量 p
u
表示用户 u 对每个潜在因素的亲和度。类似地,向量 q
i
表示项目 i 对潜在因素的亲和度。Alice 被表示为(10%,10%,50%,...),这意味着她对动作片和喜剧片兴趣不大,但她似乎喜欢浪漫片。对于 Bob,他似乎更喜欢动作电影超过其他任何电影。我们还可以看到,Titanic 主要是一部浪漫电影,绝对没有半点喜剧的元素。
所以,当我们使用 R 的 SVD 时,我们将用户 u 对项目 i 的评级建模如下:










