选自kdnuggets
作者:Mauricio Vacas
机器之心编译
参与:Quantum Cheese、微胖
在这篇文章中,我们会讨论在模型管理和部署中如何避免糟糕模型情景的方法。
在我们的产业中,很多关注都集中在开发分析模型来解决关键商业问题以及预测消费者行为上。但是,当数据科学家研发完模型,需要部署模型以供更大的组织使用时,会发生什么情况?
没有严格流程就部署模型会引发后患,看一下这个金融服务业的实例就知道了。
拥有自己的高频贸易算法的 Knight 曾是美国最大的股票贸易商,在纽约证券交易所(NYSE)有17.3%的市场份额,在纳斯达克(NASDAQ)有16.9%的市场占有率。但是,2012年由于一次计算机交易的小故障,Knight在不到一小时之内蒙受了4.4亿美元的损失。那年年底,公司被收购。这充分证明:未经适当测试就轻易部署使用分析模型会有很大风险,那些系统漏洞会给公司带来严重后果。
在这篇博文中,我们将谈谈如何通过合理的模型管理和部署流程来避免后患。在部署模型之前,有几个必须解决的问题:
模型结果是如何到达那些会从这一分析中获益的决策者或者应用程序那里的?
这个模型能不出问题的自主运行吗?如何从失败中恢复运行的?
因为训练数据是不再相关的历史数据,模型也因此变得陈旧,会导致什么后果?
在不阻断下游消费者的情况下,如何部署和管理新版模型?
我们可以把数据科学的开发和应用看作是两个不同的流程,但是,这两个过程又是更大的模型生命周期流程的一部分。下面示例图说明了这一过程。
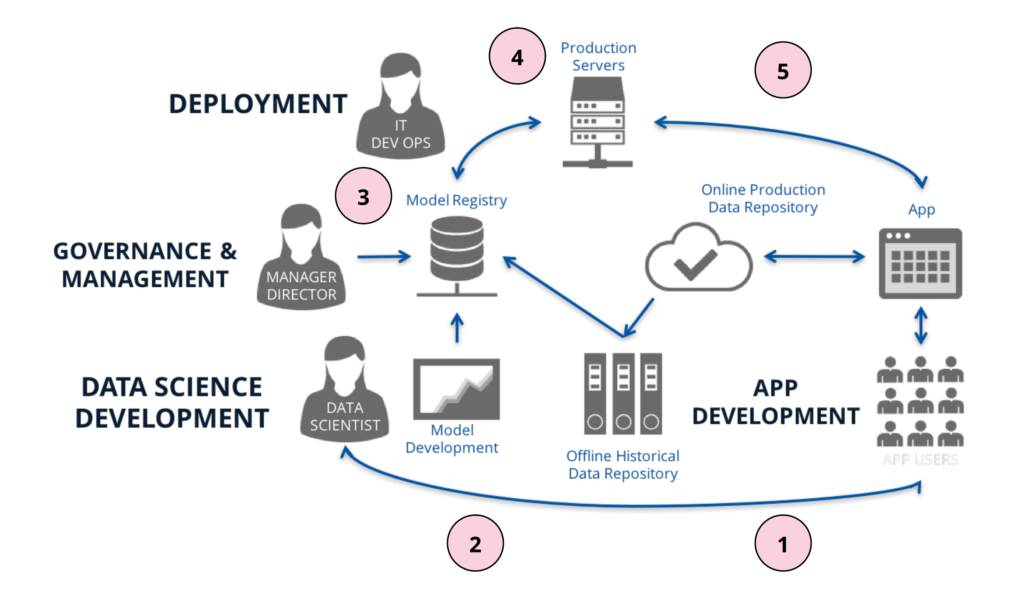
1. 终端用户与应用程序交互,产生的数据存储在应用的线上产品数据库中。
2. 然后这些数据会被传到一个线下的历史数据库中(如 Hadoop 或 S3),由数据科学家进行分析,搞清楚用户是如何与应用交互的。这些数据也有别的用处,比如构建一个模型,根据用户在应用中的行为把他们进行分类,这样我们就可以利用这些信息对用户进行营销。
3. 一旦构建出了一个模型,我们可以把它登记到一个模型注册表中,这时一个治理程序会对模型进行评估,批准其投放产业应用,并对模型部署要求进行评估。
4. 当模型的产业应用被批准后,我们就开始部署模型。为此,我们要搞清楚组织会如何使用这个模型,作出相应调整,确保模型能在特定性能约束下自主端到端运行,同时也要进行测试,以确保在部署之后模型仍与开发出来的一致。一旦完成这些步骤,我们就在投入生产前,再次对模型进行了评估和批准。
5.最后,一旦部署完毕,模型所做出的预测就能服务于应用程序,这些预测的权值都是根据用户交互行为计算出的。这些信息有助于改进模型,或提出一个新的商业问题,这就又回到了过程(2)。
为了确保周期运行成功,我们需要理解数据科学的开发和部署有着不同的要求,这些要求都需要被满足。这就是为什么你需要一个实验室,同时也需要一个工厂。
实验室
数据实验室是数据科学家进行研究的地方,关注点不同于应用产品。最终目标也许是利用数据驱动组织内的决策制定,但是,实现这个之前,我们需要先弄清楚对组织而言,那些假设有意义,并证明其价值。因此,我们主要关注的是创造出一个环境——实验室,在这里,数据科学家可以提出问题,构建模型,并用数据进行测试。
正如以下基于 CRISP-DM 模型的图表所示,这个过程基本上迭代式的。
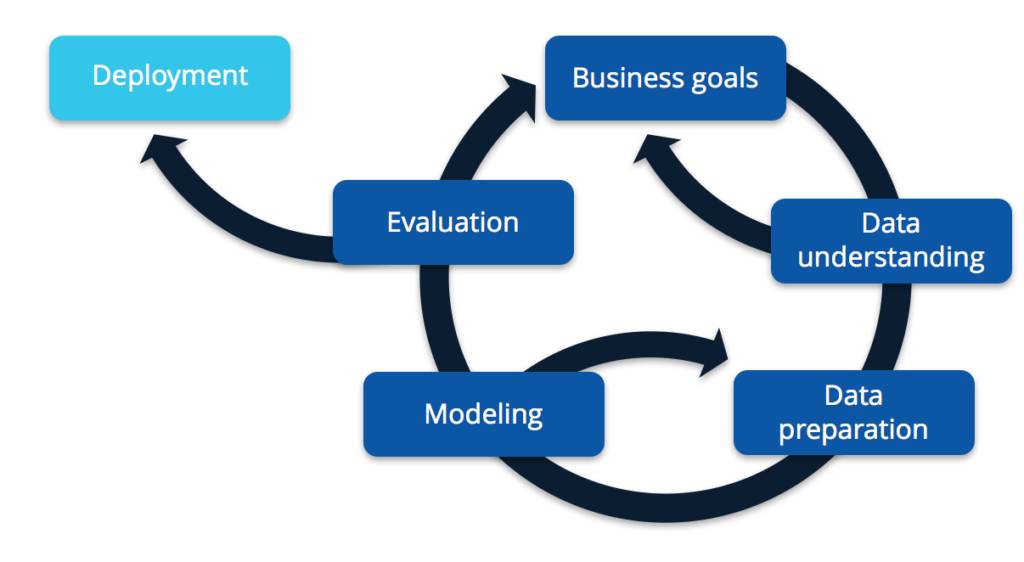
我们不会在本文讨论太多细节,但是我们有一个深入这个主题的教程。如果你想下载此教程的课件,请访问 https://goo.gl/SwAfWw
在这里,我们关心的问题是需要实验室来研发模型,还需要一个工厂,用以部署这个模型并将之自动应用到实时数据,在约束条件下把结果传送给适当的客户,并且监管整个过程,以防运行失败或异常。
工厂
在工厂里,我们要做的是优化价值创造并降低成本,评估稳定性和结构弹性,确保在约束条件下把结果传送给适当的客户,同时能监控和管理程序故障。我们需要给模型提供一个结构,根据生产中的情况进行预期。
为了理解工厂的运行过程,我们来看一下如何通过模型注册表来管理模型,以及部署时需要考虑哪些问题。
模型注册表
为了给模型一个结构,我们会根据模型的组件进行定义,包括数据依存性,脚本,配置以及文件。另外,我们会捕获模型上的元数据及其不同版本,提供额外的商业环境和模型特定信息。给模型提供一个结构,接着就能将模型目录清单存在模型注册表中,包括了不同模型版本,以及执行过程反馈的关联结果。下面的图示解释了这个概念。
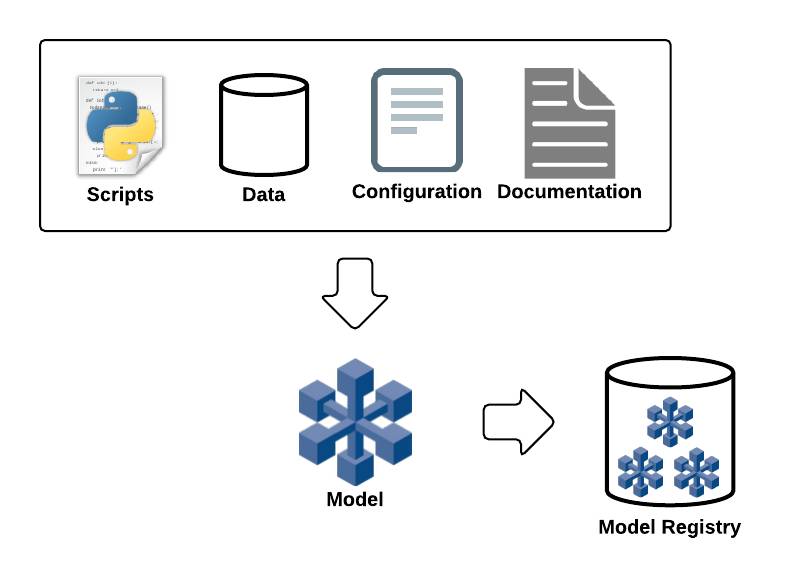
通过注册表,我们可以:
你同样也可以选择在模型某个版本中加入 Jupyter Notebook 。这可以让一个审阅者或开发者遍历此版本原始开发者最初开发时的思维过程和假设。有助于模型维护,也有助于组织探索。
这里有一个矩阵,解构了一个模型的不同元素:
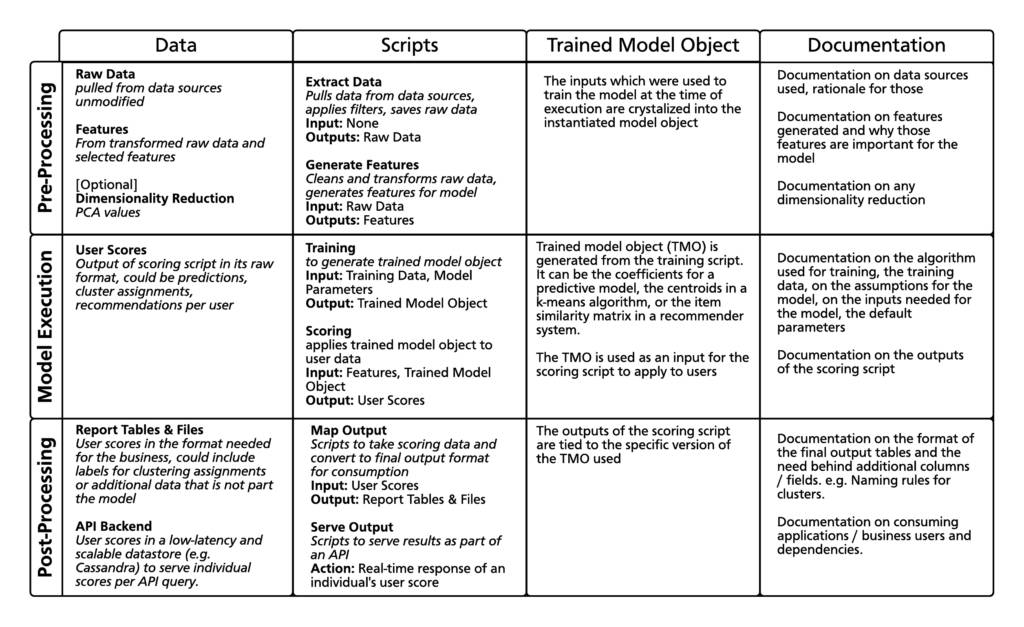
注册表需要捕捉到数据、脚本和训练过的模型对象之间的联系,图中说明了与一个模型特定版本相关的文件。
这对我们的实践有什么帮助?
通过收集如何运行一个模型所需的资产和元数据,我们就能驱动一个执行工作流,将模型的特定版本用于实时数据,为终端用户预测结果。如果这是批量程序的一部分,我们就可以利用这些信息为模型创造一个暂态的执行环境,来提取数据、脚本、运行模型、在目标存贮里保存结果,并在程序完成后关闭环境,在最大化资源的同时将成本最小化。
从监管角度来看,我们可以支持那些决定模型何时被推向产业化的商业工作流,这些工作流负责允许运行中的模型监视程序去做出一些决定,比如,当我们发现模型预测已不再符合现实情况时是否应该重新训练它。如果你有审计要求,你可能需要跟顾客解释你是如何得到某个特定结论的。为了做到这一点,你需要去考察在特定时间运行的某个特定版本的模型,并且需要知道复现这个结果用到了什么样的数据。
如果我们在一个已有模型中发现了漏洞,我们可以把它标记成不应该使用,修复后发布此模型的新版本。对所有使用漏洞版本的用户发送通知,他们就可以转而使用新的修复版。
如果不进行以上这些步骤,我们就有可能让模型维护变成需要试图理解原始开发者意图的冒险行为,部署后的模型不再与那些正在开发中模型相匹配,产生不正确的结果,在已有模型升级后还会扰乱下游用户的正常使用。
模型部署
一旦模型被批准部署,我们需要通过几个步骤来确保模型能被部署。要有验证正确性的测试,还要测试提取原始数据的管道流程、特征生成,以及分析模型评分以确定模型可以自主运行,以消费者需要的方式产生出结果,满足行业定义的性能要求。还要确保模型的执行过程处于监控中,以防发生错误或模型过时不再产生准确的结果。
在部署之前,我们要确保测试了下面几项:
我们通过两种方式来最小化部署后模型与开发模型匹配时的风险:1)部署到生产环节之前就运行测试,2)捕获环境细节,比如特定的语言版本和模型的库依存性(例如,一个Python requirements.txt 文件)。
一旦部署到生产环节后,我们就想对用户显示模型的预测结果。有多少用户会使用这一模型进行预测?在为模型打分时,提供特征数据的速度要有多快?比如,欺诈侦测中,如果特征信息每24小时产生一次,那么,从事件发生到诈骗侦测模型检测到此事件之间,会存在严重滞后。这就是我们需要解决的一些可扩展性和性能方面的问题。
就一个应用程序来说,最理想的方式是通过网页服务向用户展示结果,方式是通过模型实时得分或是以线下批处理过程展示评分结果。或者是,模型需要支持一个商业过程,我们需要把模型的结果放在一个为决策者生成报告并遵照该这些结果予以行事的地方。无论是那种情况,如果没有模型注册表,想要知道哪里可以找到并使用当前模型的结果是很困难的。
另一个应用实例是想要搞清楚模型如何背离实时数据运行,以考察模型是否变得陈旧,或者确定一个新开发的模型性能是否超过旧模型。一个简单的例子就是用回归模型来对比预期值和实际值。如果我们没有监测到模型结果随时间变化,那么,我们可能是在根据不再适用于当前情势的历史数据在做决策。
结论
这篇文章中,我们遍历了模型周期,讨论了对实验室和工厂的需要,意在降低部署那些可能影响商业决策(并且还可能带来高成本)坏模型带来的风险。另外,注册表也提供了组织中模型的透明性和可发现性。这有利于通过呈现组织使用的现有技术,来研发新模型,解决相似问题,也有利于现有模型维护或通过澄清模型当前版本、目前相关资产情况等来提升模型。
在 SVDS ,我们正在研发一个架构,它能支持模型管理,把不同模型版本登入注册表,并管理如何将这些模型版本部署到一个执行引擎中。
原文地址:http://www.kdnuggets.com/2017/04/models-from-lab-factory.html

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








