
微信公众号
关键字
全网搜索
最新排名
『量化投资』:排名第一
『量 化』:排名第一
『机器学习』:排名第四
我们会再接再厉
成为全网
优质的
金融、技术类公众号
编译:watermelon、西西
作者:
Thomas Wiecki
在评估交易算法时,我们通常可以使用样本外的数据,以及真实交易数据去进行评测。评测策略最大的问题是,它有可能是过度拟合的,在过去的数据上表现很好,但在样本外或者未来的真实行情数据中表现一般。今天,公众号编辑部编译了这篇来自Q-blog的文章,也
加进了我们自己的一些见解和对文章专业知识的解释
,来告诉大家使用贝叶斯估计预测未来可能的回报。
建模计算总会带来一些风险,如估计不确定性,模型错误指定等错误。 根据这种风险因素,模型预测并不总是100%可靠。 然而,即使预测不完美,模型预测仍然可以用于提取有用的算法信息。
例如,将交易算法应用于未知市场数据产生的实际结果,与我们已有模型生成的预测进行比较,可以让我们知道该算法是否按照预测的方式进行反演,或者是否过度依赖过去的数据。这样的算法可能具有最佳的回测结果,但它们在实际交易中可能不一定具有如此出色的表现。就好比前端时间,在很多量化平台产出的策略曲线很好看,但是有些是在特定瓶品种和参数调优下的结果,或者就是在特定市场环境中的产出,过去的业绩不能代表未来的收益,更何况用一些很复杂的算法,结果却不是很理想等等。这种算法的一个例子可以在下图中看到。
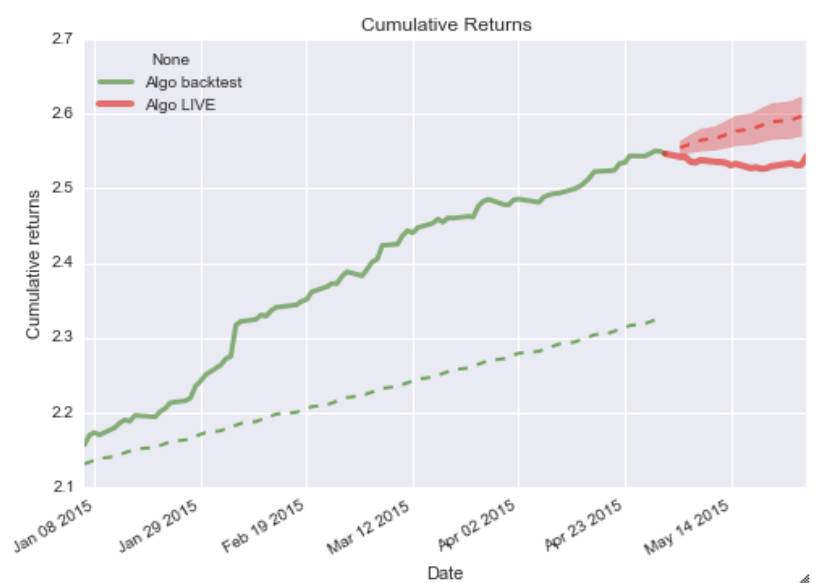
可以看出,算法的实时交易结果完全超出了我们的预测范围,算法的运行情况比我们的预测差。这些预测是通过线性拟合累积返回的值生成的。然后我们假设这种线性趋势不断前进。由于我们对将来进一步的事件有更多的不确定性,因此线性锥体正在扩大,假设返回值的属于正态分布,并从后验数据估计出方差。这肯定不是产生预测的最佳方法,因为它有一些强大的假设,如收益率的正态性,我们可以根据有限的回测数据准确地估计方差。下面我们可以看出,我们可以使用贝叶斯模型改进这些锥形来预测未来的回报。
一方面,有一些算法在过去的数据和实时交易数据上表现相同。 下面的图片可以看出这个例子。

最后,我们可以发现由于市场变化而不是由于算法本身的特征而导致的过去和实时交易期间的算法行为之间的差异。 例如,下图显示了一个算法,直到2008年的某个时候,这个算法相当不错,但突然之间,市场崩溃了。
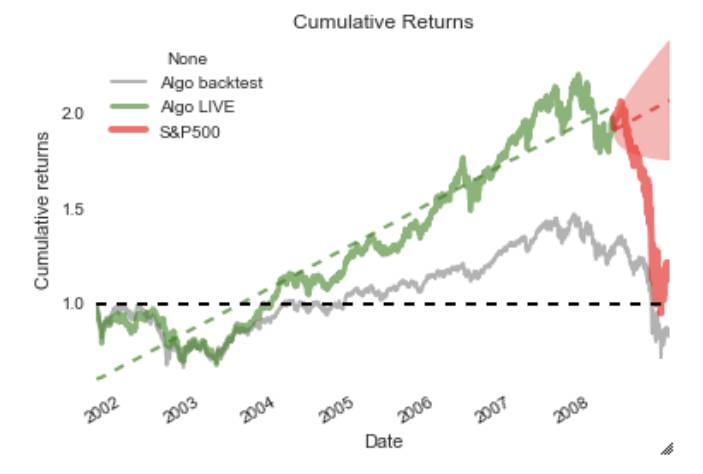
在贝叶斯方法中,我们没有得到我们的模型参数的单个估计,就像我们用最大似然估计一样。 相反,我们为每个模型参数获得完整的后验分布,量化了该模型参数的不同值的可能性。 例如,对于很少的数据点,我们估计不确定度将被广泛的后验分布反映出来。 随着我们收集更多的数据,我们对模型参数的不确定性将会降低,我们后验分布范围
将会越来越窄
。 贝叶斯方法还有许多好的方法,例如将先前知识纳入范围之外的效果等等。
我们简单地看一下可以用于预测的两个贝叶斯模型。 这些模型对如何分配日常收益做出了不同的假设。
常规模式
我们称第一个模型为常规模型。 该模型假设每日收益是从一个正态分布中抽样的,正态分布的均值和标准偏差相应地从一个正态分布和一半分布中抽样。 正常模型的统计描述及其在PyMC3中的实现如下所示。
mu ~ Normal(0, 0.01)
sigma ~ HalfCauch(1)
returns ~ Normal(mu, sigma)
with pm.Model():
mu = pm.Normal('mean returns', mu=0, sd=.01)
sigma = pm.HalfCauchy('volatility', beta=1)
nu = pm.Exponential('nu_minus_two', 1. / 10.)
returns = pm.T('returns', nu=nu + 2, mu=mu, sd=sigma, observed=data)
start = pm.find_MAP(fmin=sp.optimize.fmin_powell)
step = pm.NUTS(scaling=start)
trace = pm.sample(samples, step, start=start)
预测锥:实时交易期间预测的可视化
在这里,我们阐述从贝叶斯模型中创建预测的步骤。 这些预测可以用我们期望从模型中看到的累积回报的锥形区域可视化。 假设我们正在使用适合交易算法的过去每日收益的正常模型。 该模型在PyMC3中拟合的结果是模型参数mu(均值)和sigma(方差)的后验分布。
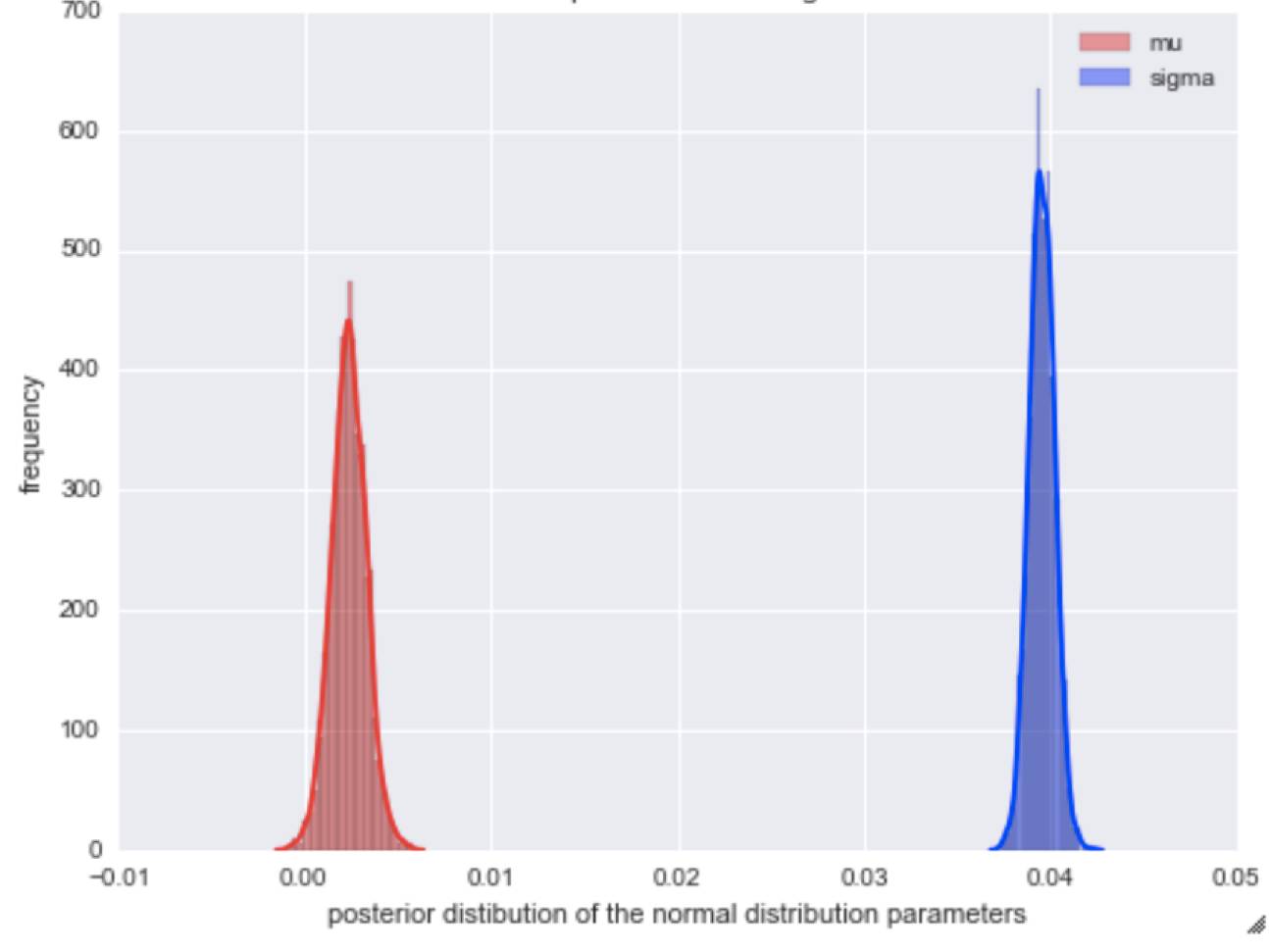
现在我们从mu后验分布中获取一个样本,并从sigma后验分布中抽取一个样本,用它们构建正态分布。 这给了我们一个可能的正常分配,它对每日回报率数据有合理的适用性。








