作者:许键
来源:腾讯云技术社区(https://www.qcloud.com/community/)
导语
在知乎等地方经常看到有人问,Python 的多线程是不是鸡肋?为何我用多线程性能一点没有提升,有时候性能反而下降?在这里通过日常工作中遇到的问题以及自己的一些总结,来一探 Python 多线程究竟是不是鸡肋;如果不是,那又该如何使用。
1、遇到的问题
工作中常用到 python 来分析文件,统计数据;随着业务的发展,原先的代码性能受到了一定的挑战,下面根据两个案例来讲解在 python 的使用过程中,遇到的一些问题,以及自己的一些总结。
案例一:数据统计,将文件按照一定的逻辑统计汇总后,入库到本地 db 中。
最开始的代码流程框图:
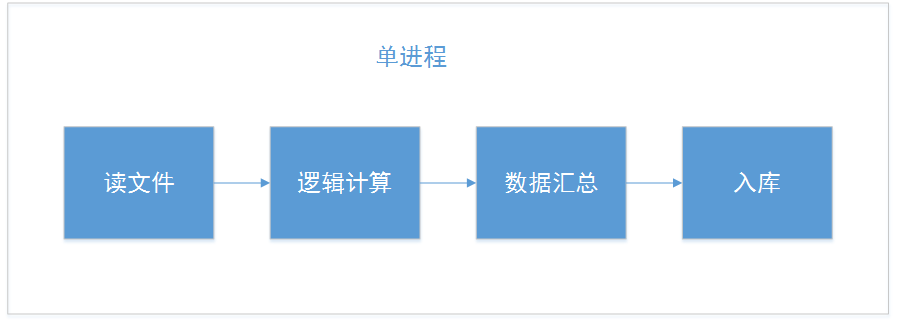
大概流程:
1、循环读文件,按照一定格式将文本进行拆分计算;
2、根据指定的 key 来统一汇总数据;
3、入库本地 DB,入库时,会先查找 db 中是否存在这条记录,然后再判断是否插入 db 中;相当于这里会有两次 db 操作,一次查询,一次写入。
一开始业务量小,db 数据量少,整个流程耗时较短,在秒级能够完成,随着业务发展,所需时间也有秒级变成了分钟级,十分钟级别等。
测试 1
通过对其中的一个业务某天的数据进行测试,它的耗时主要分部为,读文件(文件大小 1G 左右)耗时 2 秒,逻辑计算及汇总 58s,数据入库 32s;总耗时大概在 1 分半钟。
1.1 方案一
流水线形式的多线程
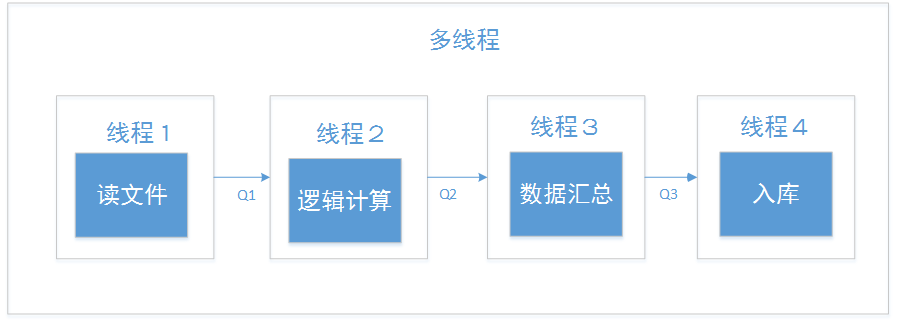
线程1负责读取数据,然后通过 python 自带的 Qeueue,Q1 传递数据给线程 2;
线程 2 负责逻辑计算,然后通过 Q2 传递数据给线程 3;
线程 3 负责汇总数据,然后通过 Q3 传递数据给线程 4;
线程 4 则入库数据;
这个方案在实现之后立马就被废弃了,它的效率比单进程的效率低很多,通过查看系统调用之后,发现是因为多个线程一直在竞争锁,以及线程切换导致其执行效率还不如单线程。
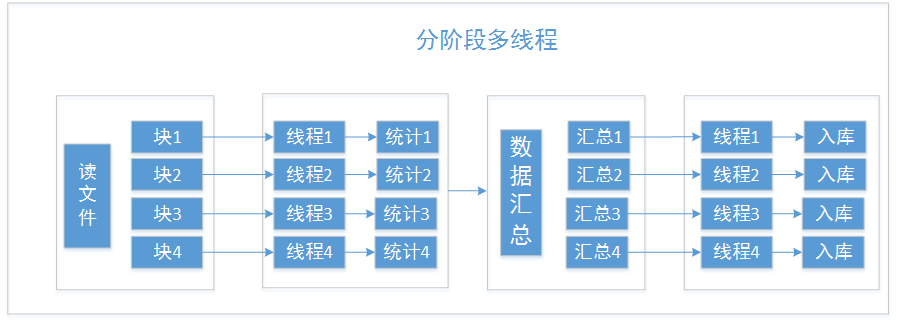
1.2 方案二
数据分片分段多线程
在不同的时机采用多线程来处理,同时尽量避免多线程对同一资源进行竞争,以减少锁的切换带来的消耗。因此这里在逻辑计算和数据入库阶段分别采用数据分组,多线程执行的方式来进行处理。
分段一、逻辑计算和汇总,将内存读到内存中后,按照线程数量,将数据切分成多块,让第 i 个线程 thread[i]处理第 i 份数据 data[i],最后再将计算得到的 4 份数据汇总,按照相同的 key 进行汇总;得到 sum_data。
分段二、将 sum
data 按照线程数量,切分成多份,同样让 thread[i]处理 sum
data[i]的数据,让他们各自进行数据的查询以及写入操作。
测试 2
对同一个文件进行测试,读文件耗时 2 秒,逻辑计算及汇总 62s,数据入库 10s;总耗时大概在 70 多秒,相比最开始的单线程,时间大概下降了 20 多 s;但可以看出,逻辑计算的时间相比单线程确增加了不少,而入库操作的时间减少了 20 多 s;这里就引发一个问题,逻辑计算跟入库的差异在哪里?为何前面的多线程性能下降,而后面性能确大幅度提高。
这里的原因究竟为何?
案例二
案例 2 的整体流程为,将几份不同的数据源从 db 中取出来,按天取出,经过一定的整合后,汇总插入到一个目标 db 中。
一开始的代码流程:
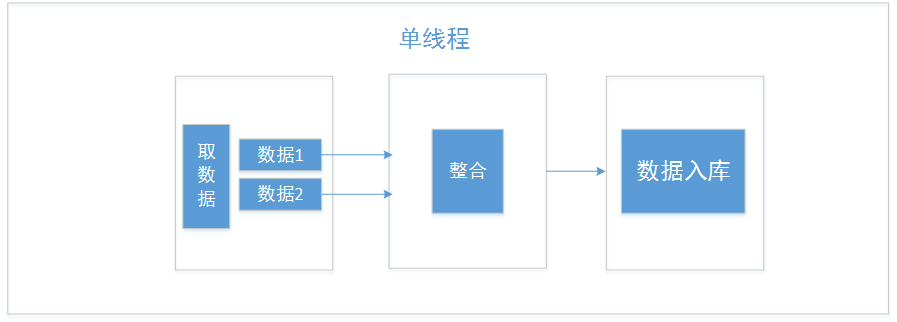
同样最初的时候,需要整合的数据量较少,db 中的数据量也较少。随着业务增长,每天需要处理的数据量也逐渐增加,并且 db 中的数据量也越来越大,处理的时间也从开始的秒级别也逐渐增加到分钟级别,每次都是统一处理一个月的数据,整体耗时需要几个小时。
测试 3
对某天的数据进行测试,结果为:取数据 整合 耗时 30s;插入数据耗时约 8 分钟。
更改成以下模型:
入库操作同样需要先根据 key 查找当前 db 中是否存在该条数据,不存在则写入。
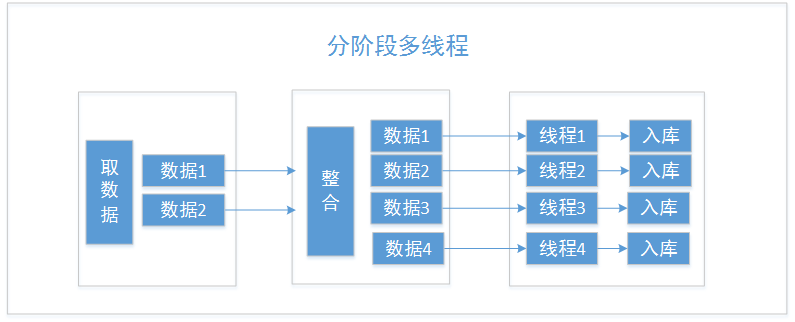
测试 4
取数据 整合 耗时 30s;插入数据耗时约 2 分钟。
更改之后性能大幅度提升,由原先的 8 分半钟,缩减为不到 2 分半钟左右,缩减的时间主要体现在入库阶段;
从以上两个例子可以看到,当涉及 I/0 操作时,python 的多线程能发挥较好的性能;而当涉及到 CPU 密集型逻辑运算时,python 的多线程性能不升反降。这里都是由于 python 的 GIL 在发挥的作用。
2、了解 python 的 GIL
这里我们使用的解释器为官方实现的 CPython,它是由 C 语言实现的 python 解释器。同时还存在由 Java 实现的 Jython 解释器,由.NET 实现的 IronPython 等解释器。这里我们主要是依据 CPython 来讲解 GIL 锁。
GIL,全称 Global Interpreter Lock, 是一个全局解释器锁,当解释器需要执行 python 代码时,都必须要获得这把锁,然后才能执行。当解释器在遇到到 I/O 操作时会释放这把锁。但如果当程序为 CPU 密集型时,解释器会主动的每间隔 100 次操作就释放这把 GIL 锁,这样别的线程有机会执行,具体的间隔次数是由 sys.setcheckinterval( number ) 来设定这个值,通过 sys.getcheckinterval() 返回这个值,默认为 100。所以,尽管 Python 的线程库直接封装操作系统的原生线程,但 Python 进程,在同一时间只会有一个获得了 GIL 的线程在跑,其它的线程都处于等待状态等着 GIL 的释放。就这样对于 CPU 密集型操作来说,多线程不但不会提升性能,还会因为线程切换,锁竞争等导致性能的下降。
在我们上面的两个例子中,当涉及到数据的查询与插入时,都需要进行 I/O 交互,并且会等待数据库服务器返回,这个时候,线程会主动释放锁,其他线程能够合理利用这个时间,来做同样的事情。
知道了 GIL 之后,我们才能更加合理的使用 python 的多线程,并不是所有场景都适用于多线程。
同样,Python 的多线程也并不是大家所说的鸡肋,在适合的场景用上了,还是能够起到惊艳的作用。
题图:pexels,CC0 授权。

点击
阅读原文
,查看更多 Python 教程和资源。





