在大型语言模型(LLM)的推理能力提升领域,传统方法高度依赖监督微调(SFT)与人工标注数据,导致训练成本高昂且泛化能力受限。DeepSeek团队在arXiv:2501.12948论文中提出创新性解决方案:通过纯强化学习(RL)框架直接激励模型的自我推理进化,实现了无需监督数据的端到端训练范式。该研究首次验证了RL在复杂推理任务中的独立有效性,其开源的DeepSeek-R1模型在17个数学推理基准测试中超越Llama3-70B等主流模型,部分指标达到OpenAI-o1水平。
DeepSeek-R1-Zero:纯强化学习的初步探索
DeepSeek-R1-Zero 是该研究的核心起点,它通过大规模强化学习(RL)直接训练基础模型(DeepSeek-V3-Base),无需任何监督微调(SFT)作为前置步骤。
研究团队采用了 Group Relative Policy Optimization(GRPO)算法,通过采样和优化策略模型,显著提升了模型在推理任务中的表现。

在训练过程中,DeepSeek-R1-Zero 使用了基于规则的奖励系统,包括准确性奖励(用于验证答案的正确性)和格式奖励(确保模型的推理过程符合指定格式)。这种奖励机制避免了神经奖励模型可能带来的奖励劫持问题。
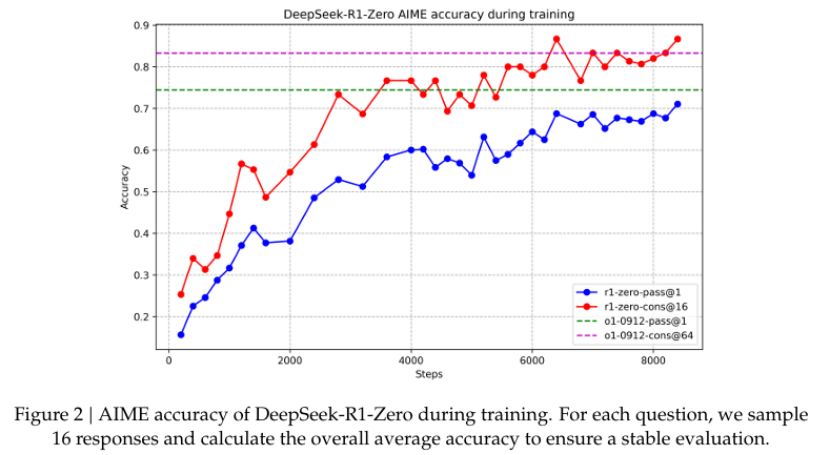
随着训练的进行,DeepSeek-R1-Zero 的推理过程逐渐变得更加复杂和深入,模型自然学会了如何通过增加推理时间来解决更复杂的任务,并且出现了“aha moment”,即模型在推理过程中自发地重新评估初始方法,展现出类似人类的反思行为。在 AIME 2024 基准测试中,DeepSeek-R1-Zero 的 Pass@1 分数从 15.6% 提升至 71.0%,并通过多数投票进一步提升至 86.7%,接近 OpenAI-o1-0912 的性能水平。
DeepSeek-R1:多阶段训练与推理能力的提升
尽管 DeepSeek-R1-Zero 展现了强大的推理能力,但它在可读性和语言混合方面存在问题。为了解决这些问题,DeepSeek 团队进一步提出了 DeepSeek-R1,该模型通过多阶段训练和冷启动数据(cold-start data)来提升推理性能。
研究团队收集了数千条长推理链(CoT)数据,用于微调基础模型,作为 RL 训练的起点。这些数据不仅提高了模型的推理能力,还显著提升了输出的可读性。
DeepSeek-R1 的训练过程包括两个 RL 阶段和两个监督微调(SFT)阶段。第一阶段的 RL 训练专注于提升推理能力;第二阶段的 SFT 通过拒绝采样生成新的训练数据,进一步优化模型;最后,第二阶段的 RL 训练结合了所有场景的提示,使模型在推理、写作、问答等任务上表现更加出色。
在多项基准测试中,DeepSeek-R1 达到了与 OpenAI-o1-1217 相当的性能水平。例如,在 AIME 2024 中,DeepSeek-R1 的 Pass@1 分数达到了 79.8%,在 MATH-500 中达到了 97.3%,在 Codeforces 中的 Elo 评级达到了 2029,超越了 96.3% 的人类参赛者。
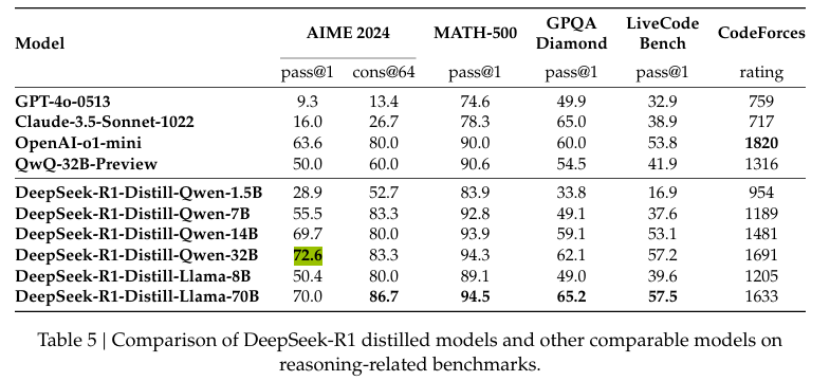
知识蒸馏:将推理能力赋予小型模型
为了使更高效的较小模型具备推理能力,DeepSeek 团队将 DeepSeek-R1 的推理模式通过知识蒸馏技术传递给基于 Qwen 和 Llama 的小型模型。研究发现,直接从 DeepSeek-R1 进行蒸馏的效果优于在小型模型上单独进行 RL 训练。
使用 DeepSeek-R1 生成的 800K 训练样本对小型模型进行监督微调(SFT),而不包括 RL 阶段。这种方法显著提升了小型模型的推理能力。例如,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 中的 Pass@1 分数达到了 55.5%,超越了 QwQ-32B-Preview;DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 中达到了 72.6%,在 MATH-500 中达到了 94.3%,在 LiveCodeBench 中达到了 62.1%,显著优于其他开源模型。