作者:李乐 CSDN专栏作家
深度学习的潜在优势就在于可以利用大规模具有层级结构的模型来表示相关数据所服从的概率密度。从深度学习的浪潮掀起至今,深度学习的最大成功在于判别式模型。判别式模型通常是将高维度的可感知的输入信号映射到类别标签。训练判别式模型得益于反向传播算法、dropout和具有良好梯度定义的分段线性单元。然而,深度产生式模型相比之下逊色很多。这是由于极大似然的联合概率密度通常是难解的,逼近这样的概率密度函数非常困难,而且很难将分段线性单元的优势应用到产生式模型的问题。
基于以上的观察,作者提出了产生对抗网络。顾名思义,产生对抗网络包含两个网络:产生器和判别器。产生器负责伪造一些数据,要求这些数据尽可能真实(尽可能服从只有上帝知道的概率分布),而判别器负责判别给定数据是伪造的(来自产生器生成的数据),还是来自由上帝创造的真实分布。至此,我们不得不佩服作者如此的问题形式化。整个过程中就是在博弈。产生器尽可能伪造出真实的数据,而判别器尽可能提高自身的判别性能。
这样一种问题形式化实际上是一种通用框架,因为判别器和生成器可以是任何一种深度模型。为了简单起见,该篇文章只利用多层感知机,而且生成器所生成的样本是由随机噪声得到的。利用这种方法,整个模型的训练融入了之前无法利用的反向传播算法和dropout. 这个过程中不需要近似推测和马尔科夫链。
这部分将具体介绍产生对抗网络模型,并详细推导出GAN的优化目标。
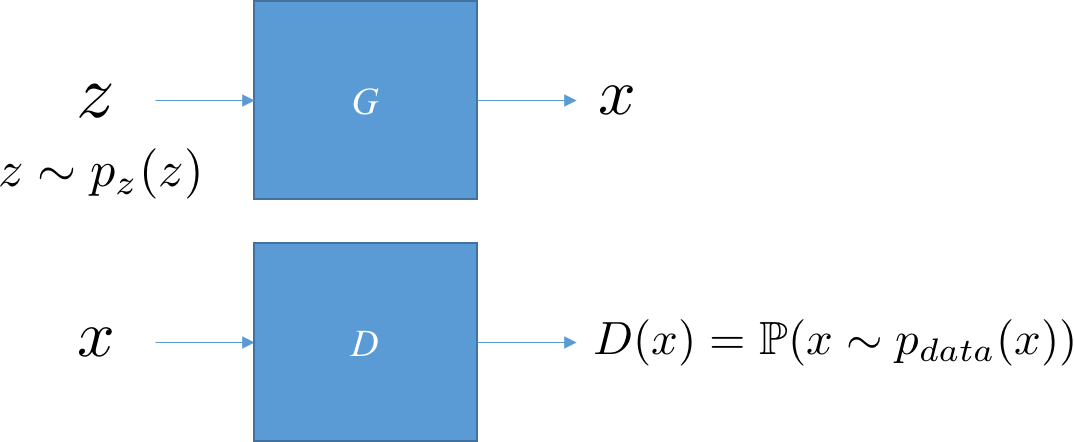
简单起见,生成器和判别器都基于多层感知神经元。对于生成器,我们希望它是一个由噪声到所希望生成数据的一个映射;对于判别器,它以被考查的数据作为输入,输出其服从上帝所定义的概率分布的概率值。下图清晰地展示了这个过程。
假设我们有包含
m个样本的训练集
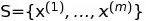 . 此外,任给一种概率密度函数
. 此外,任给一种概率密度函数
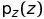 (当然,在保证模型复杂度的前提下,相应的概率分布越简单越好),我们可以利用随机变量
(当然,在保证模型复杂度的前提下,相应的概率分布越简单越好),我们可以利用随机变量
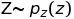 采样得到
m个噪声样本
采样得到
m个噪声样本
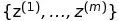 . 由此,我们可以得到似然函数
. 由此,我们可以得到似然函数
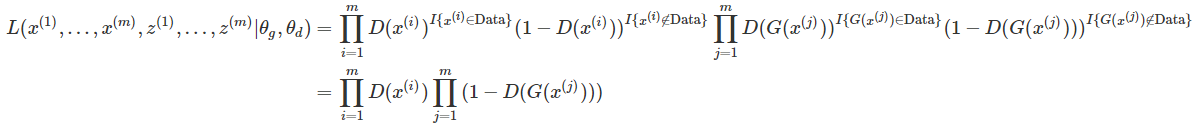
进一步,得到对数似然
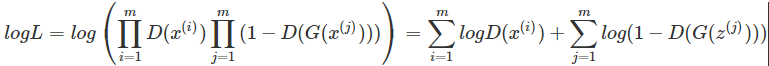
由大数定律,当
m→∞时,我们用经验损失来近似期望损失,得
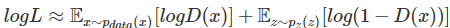
回到我们的初衷:整个过程中就是在博弈。产生器尽可能伪造出真实的数据,而判别器尽可能提高自身的判别性能。注意到我们刚刚构造的似然函数是针对判别器
D(⋅)的优化目标函数。因此,我们一方面希望对判别器的可学习参数优化,极大化对数似然函数,另一方面我们希望对判别器的可学习参数优化,极小化对数似然函数。将此形式化得到我们的优化目标:
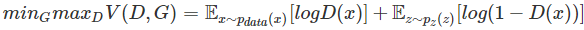
生成器
G(⋅)实际上隐式定义了一个概率分布
p
g
,将其称之为隐式是因为
G是从噪声
到样本
G(z)的映射。由此,我们自然会提出一个问题:通过这样的建模以及训练方式得到的
p
g
能否最终达到上帝创造的那个分布
p
data
,或者说两者差距到底多少?
这个问题由下面的命题和定理回答。
首先,任意给定生成器
G,我们考虑最优判别器
D.
命题1. 对于给定
G,最优判别器为
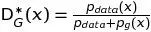
证明.
给定
G,我们目标是最大化
V(G,D)

其中,
χ和
Ω分别为
x和
z的积分域或者说是样本空间。
注意到第二项,利用映射关系
x=G(z),我们可以得到
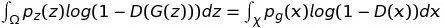
这一步并不显然。(详细推导见附录C:测度论中随机变量的换元)
所以,
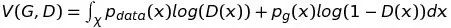
由于
G已经给定,上帝创造的分布也是确定的,因此
p
data
和
p
g
都是非零定函数,我们的目标是找到一个函数
D使得
V(G,D)到达最大。因此,我们对
D求变分(见附录A),令其为0,可以得到,极大值点
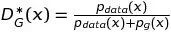
证毕。
有了这个定理,我们可以进一步将这个min max博弈重新形式化为最小化
C(G),其中
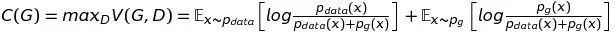
下面,我们提出并证明定理1. 由此回答本节最开始提出的问题:通过这样的建模以及训练方式得到的
p
g
能否最终达到上帝创造的那个分布
p
data
,或者说两者差距到底多少?
定理1. 对于
C(G)的全局优化最小值可达,当且仅当
p
g
=
p
data
,并且最小值为
−log4.
证明.
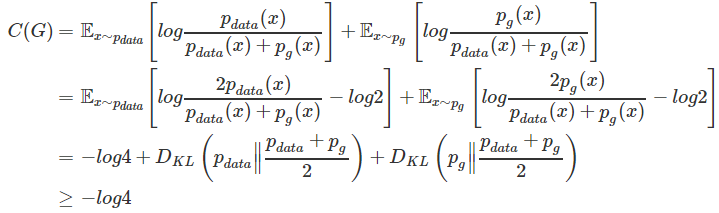
等号成立的条件为
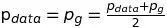 (见附
录B)
(见附
录B)
证毕。
由此可见,生成器完美地浮现了上帝创造数据的过程!
下面我们正式给出GAN训练算法流程,如下图所示。

注意到,作者给出的算法和我们的优化目标并不一致。我们推导出的优化目标,是先对D优化并将其优化到底,然后再对G优化。之所以实际训练流程与其不一致,是因为实际中如果对D优化到底,这将会导致很高的计算代价,而且通常会导致过拟合。相反,该算法是先对D优化k步,然后再进行一步对G的优化。通过这种方法,只要G变化得足够慢,D总是在最优解的附近。自然地,我们会提出一个疑问,这样交叉地训练G和D和形式化得到的minmax博弈,两者得到的解差距有多少?这个问题由下面的命题回答。










