

作者:孔泽林 腾讯DBA高级工程师
来源:腾讯课堂Coding学院
导语:王者荣耀从2015下半年至今取得辉煌成就,正所谓最好的爱情莫过于各自努力彼此成就:)这期间Tcaplus伴其成长,遇到了很多风险和挑战。本文主要回顾了王者Tcaplus几大优化点。特别感谢ben,ob,shiwei,fengjun以及资源组等专家的帮助。
1、DB整体概述
1.1 Tcaplus整体架构如下:
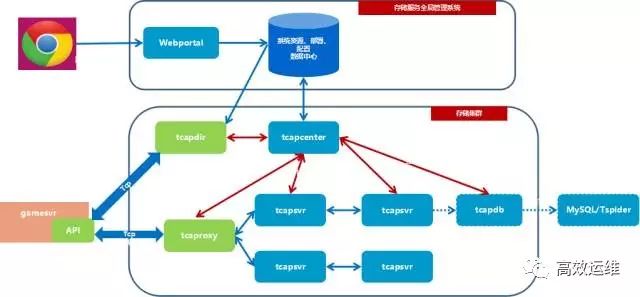
①模块:
Tcaplus的管理模块由存储服务全局管理系统(OMS)和tcapcenter组成,OMS向用户呈现基于web的管理入口,将用户的指令转发给tcapcenter,实际的控制、管理工作由tcapcenter完成,OMS则将操作的进度和结果反馈给用户。每个存储集群有一个tcapcenter,而OMS与tcapcenter之间是一对多的关系,因此一个OMS可以管理多个存储集群。
②资源:
存储集群是一组硬件资源的集合体,对其位置没有特别的限制,但按照惯例,同一个集群的节点都应在同一个IDC内,以保证存储服务的性能。
③Tcaplus数据服务模块的工作原理:
API client连接tcapdir,读取tcaproxy列表;
tcapdir是Tcaplus API使用者在初始化系统时唯一需要提供的信息;
tcapdir可以部署多个,以达到容灾的效果;
API client获取tcaproxy列表之后,连接所有的tcaproxy进程。
用户发送数据读写请求,Tcaplus API根据用户所指定的表名及key字段信息,决定将请求发送给哪个tcaproxy进程。
tcaproxy进程接收到请求消息后,根据其维护的路由表确定目标tcapsvr master,然后将消息转发给该tcapsvr master。
tcapsvr master接收到请求消息之后,进行数据读写,并生成响应消息,原路返回经由proxy到达API client。
如果请求消息类型为写操作,tcapsvr在发送响应之前,实际上还会生成一条binlog记录,在较短时间内(毫秒~秒级)同步至slave,使得slave可实时维护一份与master相同的数据。
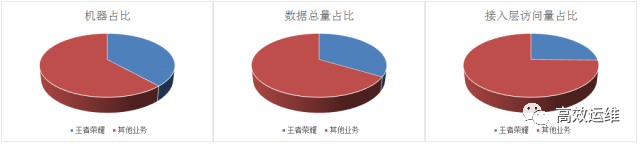
1.2 王者当前DB体量
2、主要优化案例
2.1存储层引擎参数性能优化
Tcaplus表引擎可配置参数 如下:
bnum:hash桶数,必须为正整数。默认值4194301。越大冲突越小,但占用内存越多。
xmsiz:mmap映射区的大小,默认值1073741824,即1G。
lnum:LRU链表元素个数,必须为正整数。默认值1048573。
xikmsiz:key存取区域基本大小。 默认为475000000, 即475M。根据key占用空间合理分配,过大浪费空间,过小则key不能全cache。
vmapow/vfapow/kmapow/kfapow:基本数据块大小的2的幂数,取值范围[6, 12],默认值10,表示基本数据块大小2^10 = 1024Bytes。这几个参数决定内存及磁盘使用的最小单位,类似磁盘的block,过大浪费空间,过小造成多次内部IO,影响效率。
例:以tbAcntInfo 为例,该表原始引擎参数设置为bnum=7500000#xmsiz=1000000000#lnum=7300000#xikmsiz=475000000#vfapow=6#vmapow=6#kfapow=6#kmapow=6
由于篇幅原因这里只分析两个参数
xikmsiz=475000000 代表在1个shard1G的mmap映射区内存中, key独享区为475MB,考虑到tbAcntInfo 单key只占8个字节。 线上该表单shard所有key实际只占用不到10%。因此可以把该缓存区缩小,给活跃数据留出更多缓存空间。
#kmapow=6、#kfapow=6、#vmapow=6、#vfapow=6 四个属性分别代表: 内存里key的基础块大小【2^7 B】;文件里key的基础块大小【2^7 B】;内存value的基础块大小【2^6 B】;文件里value的基础块大小【2^6 B】

keyNum[0] 代表数据分片范围的key数量,这个范围是 [ 0 B,key基础块×(KeyNum下标+1) B】= [ 0 B, 2^6×(0+1) ] = [ 0 B, 64 B ], 在这个范围内的key有263761个
valNum[16] 代表数据分片范围的val数量,这个范围是 //[ value基础块×valueNum下标 B,+∞ B】= [ 2^6×16, +∞ ] = [ 1024 B, +∞ B ], 在这个范围内的key有263761个。
上图可以看到,所有value都大于16*64B, 而现在的配置每个value块只有2^6=64B,查询一条记录需要扫描多个块, 所以vapow应该尽可能取最大值。使每个value记录尽可能分布在最少数量的block中。
修改都的引起参数为bnum=7500000 #xmsiz=1000000000 #lnum=7300000 #xikmsiz=100000000 #vfapow=12 #vmapow=12 #kfapow=6 #kmapow=6
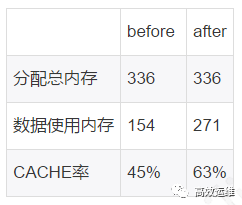
效果
2.2 Tcapsvr负载均衡-分而治之
由于业务数据突飞猛进,中途扩容Z30和Z3混用,表数量之多(7个区364个表),表的shard分布情况之复杂,造成tcapsvr节点之前负载不均(如下图1,图2)。
表shard原始分布示例:

造成各节点访问量不均:

结合业务各表的访问形态和数据规模, 我们采取分而治之的均衡策略:
核心表,诸如玩家信息表、战斗历史表。
特点是体积大,访问量大,需要消耗较多的磁盘,CPU和内存资源。 需要大量服务器来堆积性能。 抽出80%左右的节点来均匀存放,一来可以确保服务器负载均衡,也可以确保shard资源数够用。
非核心表,如全局配置表。
特点是体积小,访问量小,不占用太多资源。 可以抽出20%左右的节点来集中存放, 不干扰核心表的布局, 也因为其体积小, 可以全cache,保证了非核心表的性能。
最终tcapsvr机器的归属情况会分为三大模块:
大表模块:正式服大表(大概数据量20G以上,访问量1亿/天以上) 均匀存放在大部分Z30。
小表模块:正式服小表(大概数据量20G以内,访问量1亿/天以内)和游客服均匀存放在小部分Z30。
各个模块的机器数量视业务情况而定。
表shard均衡优化后示例:

2.3 大索引问题原理
Tcaplus索引访问原理:
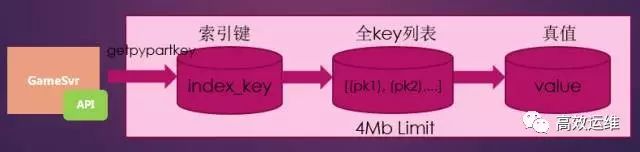
Tcaplus分两次存储引擎层的数据,第一次存储的是(index_key)=>[(primary_key1), (primary_key2),(primary_key3),……],即索引键到全key的映射。第二次存储的是[(primary_key1), (primary_key2),(primary_key3),……]=>value,即全key列表到value真值的映射
现象:
表tbBurningEnemyInfo的主键是LogicWorldID,Uid,Grade,索引键是LogicWorldID,Grade, 见图:

某些tcapsvr上发现了有明显的索引键的记录增加失败的日志,即某个LogicWorldID,Grade下面的全key数组长度【(LogicWorldID,Uid,Grade)】已经大于4MB了,不能再在索引上增加全key数组了
风险点:
API对这个表的数据会落地到tcaplus的数据文件,但是如果某个索引key下的全key列表大于4MB后,对该索引key下增加的全key的记录不再增加进索引文件了
按照索引键查询(getbypartkey)获取某个索引key下的LogicWorldID,Grade下的数据记录,存在返回的数据记录可能和玩家真实的数据不一致的, 比如数据记录有10w,按照索引键查询为9.8w(剩余的由于索引记录大于4MB增加进索引文件失败了)
按照全key查询数据不走索引逻辑, 依然能获取到数据。
解决方案:
Tcaplus已经在最新的tcapsvr版本中对索引问题进行优化,优化的核心思想为:
在tcapsvr端将原来的单条索引记录存在一条数据记录的方法,修改成单条索引记录对应的记录存在N条数据记录的方法
2.4 超时问题根治
超时原因:
王者tcaplus超时原因主要集中在tbGlobalReward表。 tbGlobalReward表的分表因子是Type,Type 属于[1, 2, 3]
<struct name="tbGlobalReward" version="1" primarykey="LogicWorldID,InsertTime,Type" splittablekey="Type" >
<entry name="LogicWorldID" type="uint32" desc="逻辑区ID(填上指只允许这个逻辑的玩家获取)" notnull="true" />
<entry name="InsertTime" type="uint64" desc="奖励插入时间/公告插入时间" />
<entry name="Type" type="uint8" desc="公告/全区全服奖励/跑马灯/小红点配置" />
业务分表因子的设计和业务的访问场景等因素关联, 造成该表数据始终集中在单个shard。业务在起服和运行时, 会定期拉取分表因子中的其中一个值。
api的请求经过一致性hash关联到tcaproxy和svr始终只有三点一线, 单个tcaproxy和tcapsvr之间的通道只有来回共10M的缓存,当gamesvr数量越多, 并发访问越大,势必会造成tcapsvr向tcaproxy回包时产生丢包。
解决方案:
Tcapsvr侧通过将 tbGlobalReward表独立存放单个节点,将此节点tcapsvr → tcaproxy的通道设置为50MB,超时问题得到缓解。
3、运维分享
3.1 基础资源
资源储备:DB全万兆网络、现网环境Tcapsvr主备异机房
资源池充足储备,保证故障替换及时性。
3.2 日常监控
3.3 备份恢复
我们目前提供一套全备+ulog的备份策略,并及时上传冷备系统,备份和上传成功率可以达到99.99%。
备份系统承诺DB可以回档到过去20天内的任意时刻。并实现页面自动回档。
3.4 扩缩容&性能优化
Tcaplus基于号段的扩缩容操作已经做到基本无损,并形成了一套固定的扩容优化单据流程。
扩容→清理无用数据→restore→主备切换→restore
3.5 故障处理
一般地,master机器故障切换到slave后,db处于单点的状态,对业务存在很大的风险。 在过去很长一段时间, 我们只能依赖设备搬迁(即上架一组新的master和slave,等凌晨的时候把故障机器数据搬迁到新机器),这种方式DB单点的时间比较久, 如果这期间再挂掉一台后果将不堪设想。
因此, 我们优化了做法, 祭出了slave重建单据,直接拉取冷备重做一台新的slave,并学习新master上的ulog,直到主备同步一致。最后剔除故障机器。将故障恢复时间降到最低。






