选自
MiniMaxir
作者:Max Woolf
机器之心编译
参与:Jane W、吴攀
Keras 是由 François Chollet 维护的深度学习高级开源框架,它的底层基于构建生产级质量的深度学习模型所需的大量设置和矩阵代数。Keras API 的底层基于像 Theano 或谷歌的 TensorFlow 的较低级的深度学习框架。Keras 可以通过设置 flag 自由切换后端(backend)引擎 Theano/TensorFlow;而不需要更改前端代码。
虽然谷歌的 TensorFlow 已广受关注,但微软也一直在默默地发布自己的机器学习开源框架。例如 LightGBM 框架,可以作为著名的 xgboost 库的替代品。例如几周前发布的 CNTK v2.0(Microsoft Cognitive Toolkit),它与 TensorFlow 相比,显示出在准确性和速度方面的强劲性能。参阅机器之心报道《
开源 | 微软发行 Cognitive Toolkit 2.0 完整版:从性能更新到应用案例
》。
CNTK v2.0 还有一个关键特性:兼容 Keras。就在上周,对 CNTK 后端的支持被合并到官方的 Keras 资源库(repository)中。
Hacker News 论坛对于 CNTK v2.0 也有评论(https://news.ycombinator.com/item?id=14470967),微软员工声称,将 Keras 的后端由 TensorFlow 改为 CNTK 可以显著提升性能。那么让我们来检验这句话的真伪吧。
在云端进行深度学习
在云端设置基于 GPU 的深度学习实例令人惊讶地被忽视了。大多数人建议使用亚马逊 AWS 服务,它包含所有可用的 GPU 驱动,只需参照固定流程(https://blog.keras.io/running-jupyter-notebooks-on-gpu-on-aws-a-starter-guide.html)设置远程操作。然而,对于 NVIDIA Tesla K80 GPU,亚马逊 EC2 收费 $0.90/小时(不按时长比例收费);对于相同的 GPU,谷歌 Compute Engine(GCE)收费 $0.75/小时(按分钟比例收费),这对于需要训练许多小时的深度学习模型是非常显著的弱点。
要使用 GCE,你必须从一个空白的 Linux 实例中设置深度学习的驱动和框架。我使用 Keras 进行了第一次尝试(http://minimaxir.com/2017/04/char-embeddings/),但这并不有趣。不过,我最近受到 Durgesh Mankekar 文章(https://medium.com/google-cloud/containerized-jupyter-notebooks-on-gpu-on-google-cloud-8e86ef7f31e9)的启发,该文章采用了 Docker 容器这种更现代的方法来管理依赖关系,该文章还介绍了名为 Dockerfile 的安装脚本和容器与 Keras 必需的深度学习驱动/框架。Docker 容器可以使用 nvidia-docker 进行加载,这可以让 Docker 容器访问主机上的 GPU。在容器中运行深度学习脚本只需运行 Docker 命令行。当脚本运行完后,会自动退出容器。这种方法恰巧保证了每次执行是独立的;这为基准评估/重复执行提供了理想的环境。
我稍微调整了 Docker 容器(GitHub 网址 https://github.com/minimaxir/keras-cntk-docker),容器安装了 CNTK、与 CNTK 兼容的 Keras 版本,并设置 CNTK 为 Keras 的默认后端。

基准方法
Keras 的官方案例(https://github.com/fchollet/keras/tree/master/examples)非常全面,涉及多种现实中的深度学习问题,并能完美地模拟 Keras 在不同模型的性能。我选取了强调不同神经网络架构的几个例子(https://github.com/minimaxir/keras-cntk-benchmark/tree/master/test_files),并添加了一个自定义 logger,它能够输出含有模型性能和训练时间进程的 CSV 文件。
如前所述,只需要设置一个 flag 就能方便地切换后端引擎。即使 Docker 容器中 Keras 的默认后端是 CNTK,一个简单的 -e KERAS_BACKEND ='tensorflow' 命令语句就可以切换到 TensorFlow。
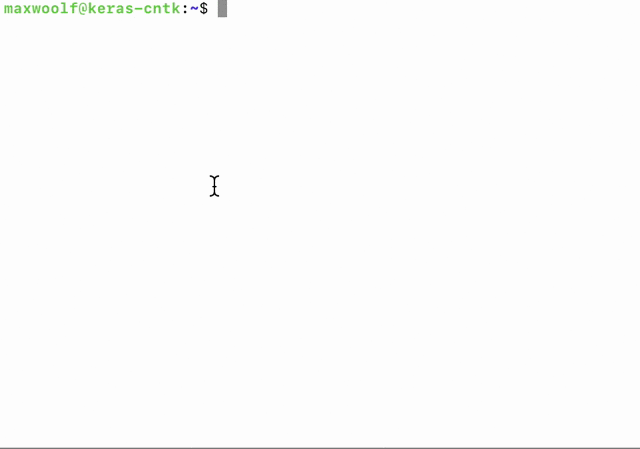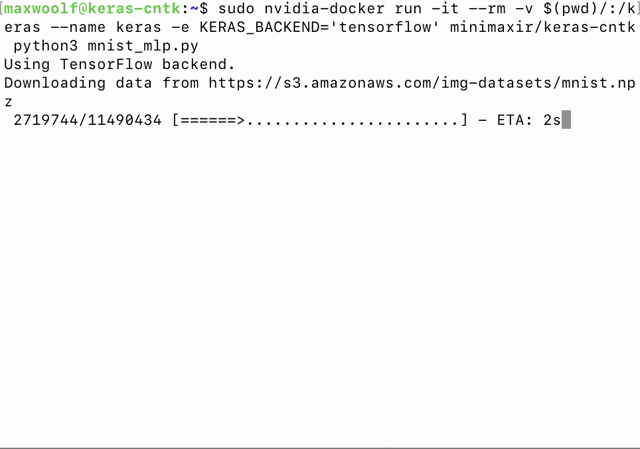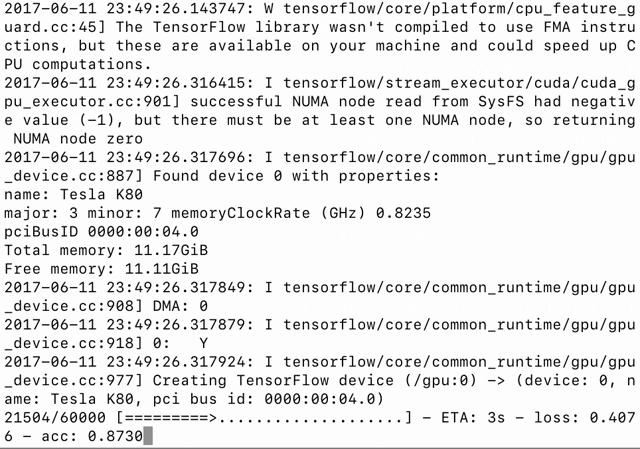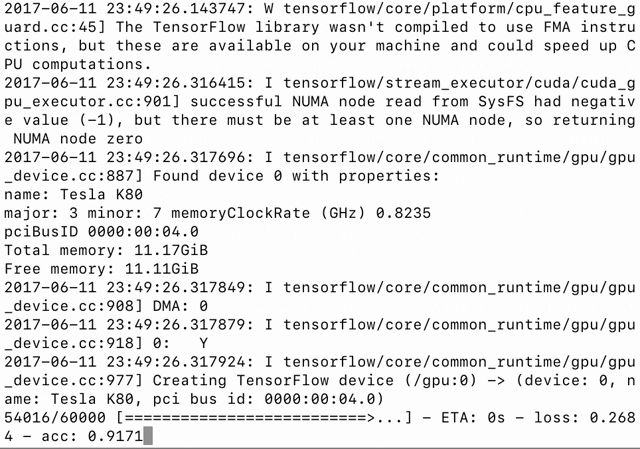
我写了一个 Python 基准脚本(https://github.com/minimaxir/keras-cntk-benchmark/blob/master/keras_cntk_benchmark.py)(在主机上运行)来管理并运行 Docker 容器中的所有例子,它同时支持 CNTK 和 TensorFlow 后端,并用 logger 收集生成的日志。
下面是不同数据集的结果。
IMDb 评论数据集
IMDb 评论数据集(http://ai.stanford.edu/~amaas/data/sentiment/)是用于情感分析的著名的自然语言处理(NLP)基准数据集。数据集中的 25000 条评论被标记为「积极」或「消极」。在深度学习成为主流之前,优秀的机器学习模型在测试集上达到大约 88% 的分类准确率。
第一个模型方法(imdb_bidirectional_lstm.py)使用了双向 LSTM(Bidirectional LSTM),它通过词序列对模型进行加权,同时采用向前(forward)传播和向后(backward)传播的方法。
首先,我们来看一下在训练模型时的不同时间点测试集的分类准确率:
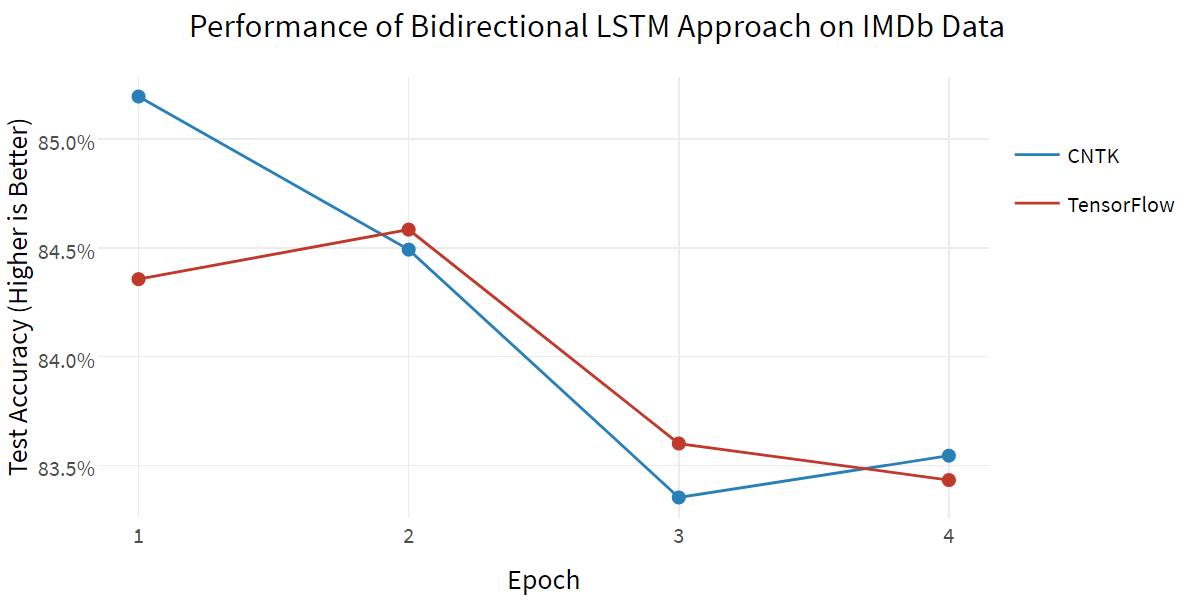
通常,准确率随着训练的进行而增加;双向 LSTM 需要很长时间来训练才能得到改进的结果,但至少这两个框架都是同样有效的。
为了评估算法的速度,我们可以计算训练一个 epoch 所需的平均时间。每个 epoch 的时间大致相同;测量结果真实平均值用 95%的置信区间表示,这是通过非参数统计的 bootstrapping 方法得到的。双向 LSTM 的计算速度:
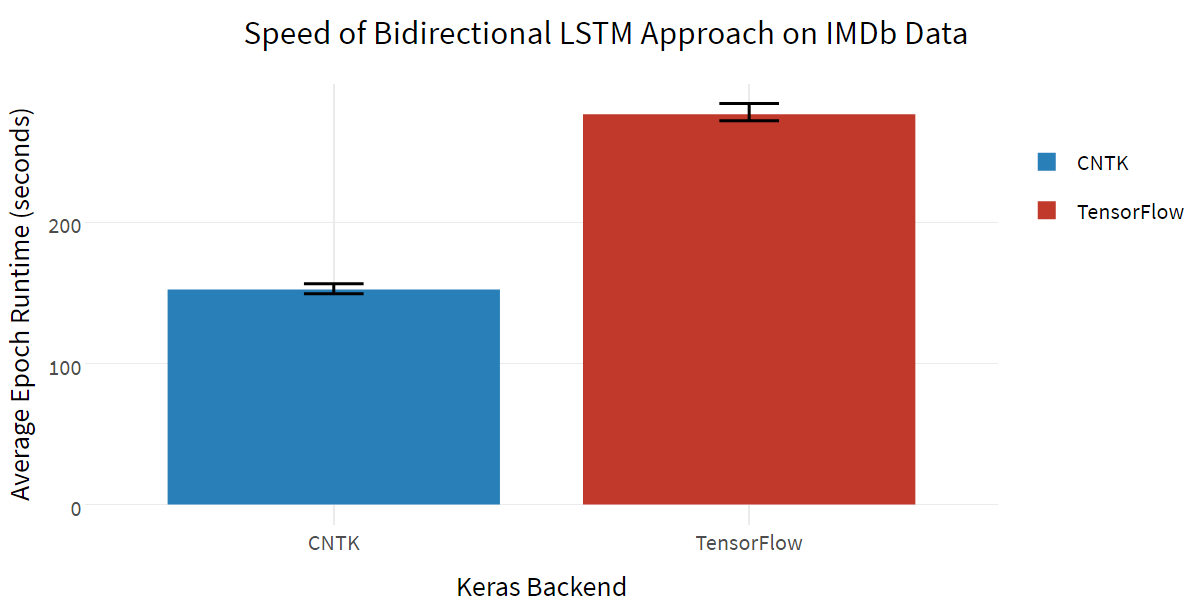
哇,CNTK 比 TensorFlow 快很多!虽然没有比 LSTM 的基准测试(https://arxiv.org/abs/1608.07249)快 5-10 倍,但是仅通过设置后端 flag 就几乎将运行时间减半就已经够令人震惊了。
接下来,我们用同样的数据集测试 fasttext 方法(imdb_fasttext.py)。fasttext 是一种较新的算法,可以计算词向量嵌入(word vector Embedding)的平均值(不论顺序),但是即使在使用 CPU 时也能得到令人难以置信的速度和效果,如同 Facebook 官方对 fasttext 的实现(https://github.com/facebookresearch/fastText)一样。(对于此基准,我倾向于使用二元语法模型/bigram)
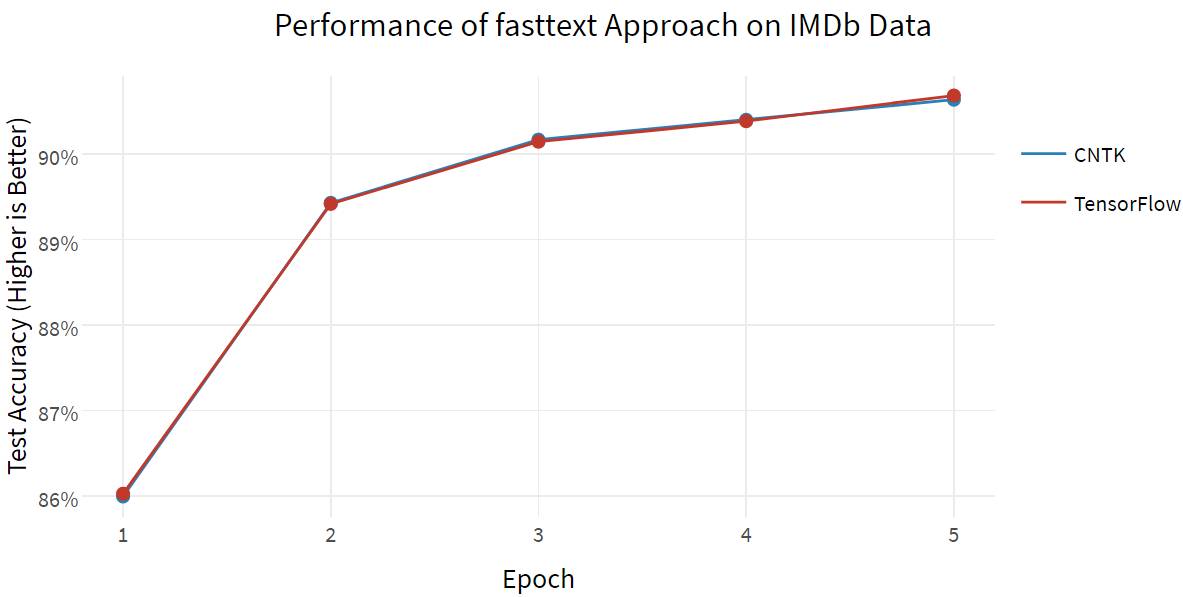
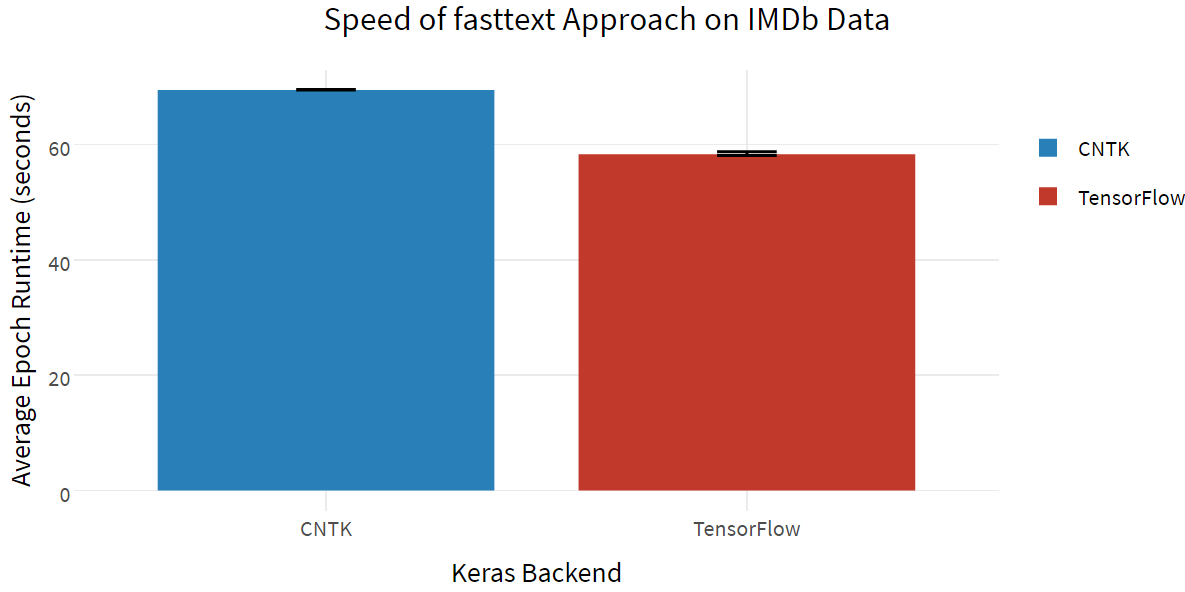
由于模型简单,这两种框架的准确率几乎相同,但在使用词嵌入的情况下,TensorFlow 速度更快。(不管怎样,fasttext 明显比双向 LSTM 方法快得多!)此外,fasttext 打破了 88%的基准,这可能值得考虑在其它机器学习项目中推广。
MNIST 数据集
MNIST 数据集(http://yann.lecun.com/exdb/mnist/)是另一个著名的手写数字数据集,经常用于测试计算机视觉模型(60000 个训练图像,10000 个测试图像)。一般来说,良好的模型在测试集上可达到 99%以上的分类准确率。
多层感知器(multilayer perceptron/MLP)方法(mnist_mlp.py)仅使用一个大型全连接网络,就达到深度学习魔术(Deep Learning Magic™)的效果。有时候这样就够了。
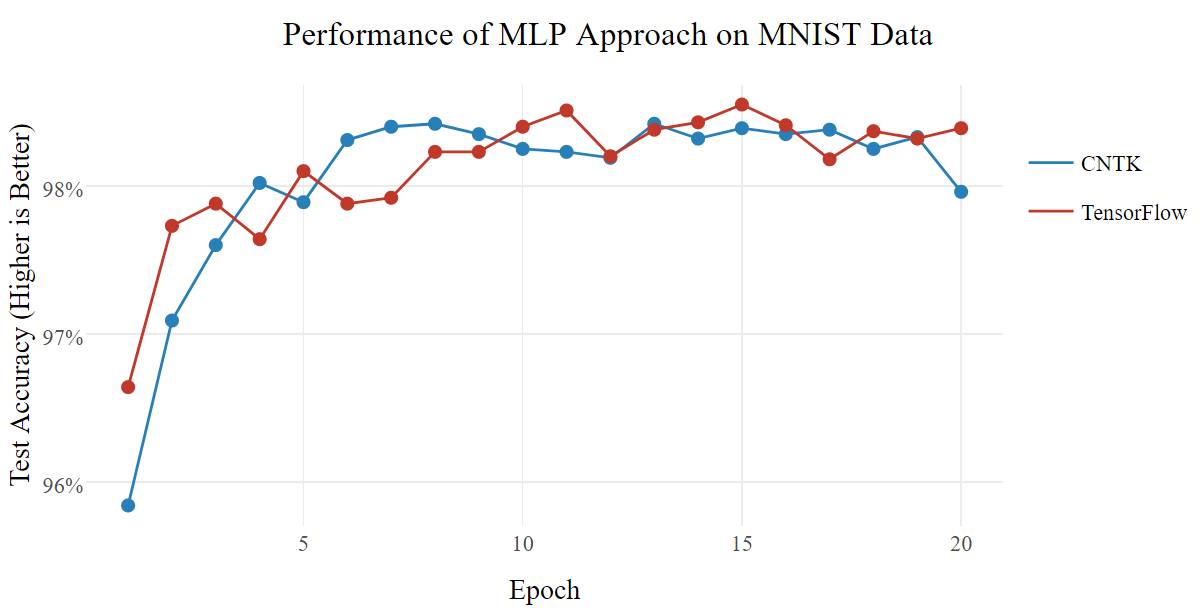
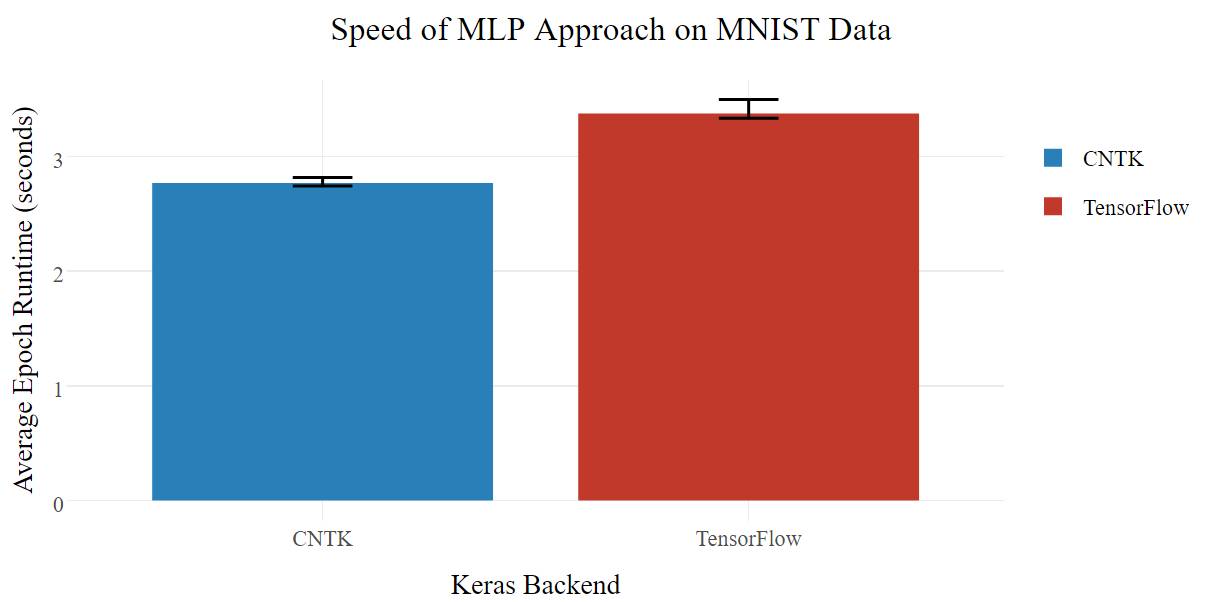
这两个框架都能极速地训练模型,每个 epoch 只需几秒钟;在准确性方面没有明确的赢家(尽管没有打破 99%),但是 CNTK 速度更快。
另一种方法(mnist_cnn.py)是卷积神经网络(CNN),它利用相邻像素之间的固有关系建模,是一种逻辑上更贴近图像数据的架构。

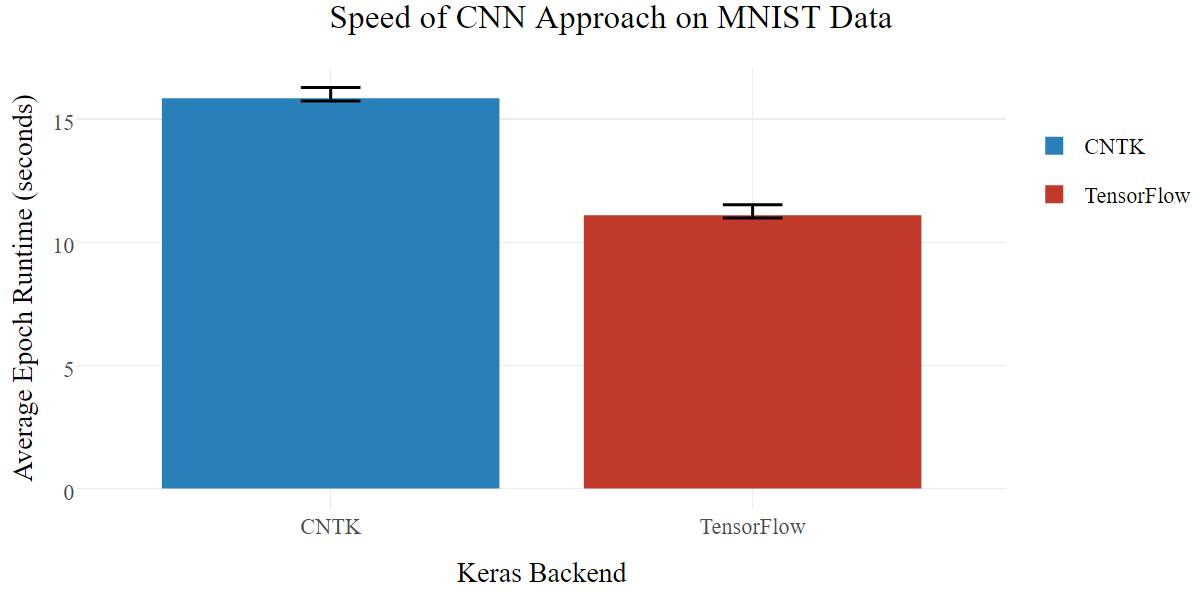
在这种情况下,TensorFlow 在准确率和速度方面都表现更好(同时也打破 99%的准确率)。
CIFAR-10
现在来研究更复杂的实际模型,CIFAR-10 数据集(https://www.cs.toronto.edu/~kriz/cifar.html)是用于 10 个不同对象的图像分类的数据集。基准脚本的架构(cifar10_cnn.py)是很多层的 Deep CNN + MLP,其架构类似于著名的 VGG-16(https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3)模型,但更简单,由于大多数人没有用来训练的超级计算机集群。
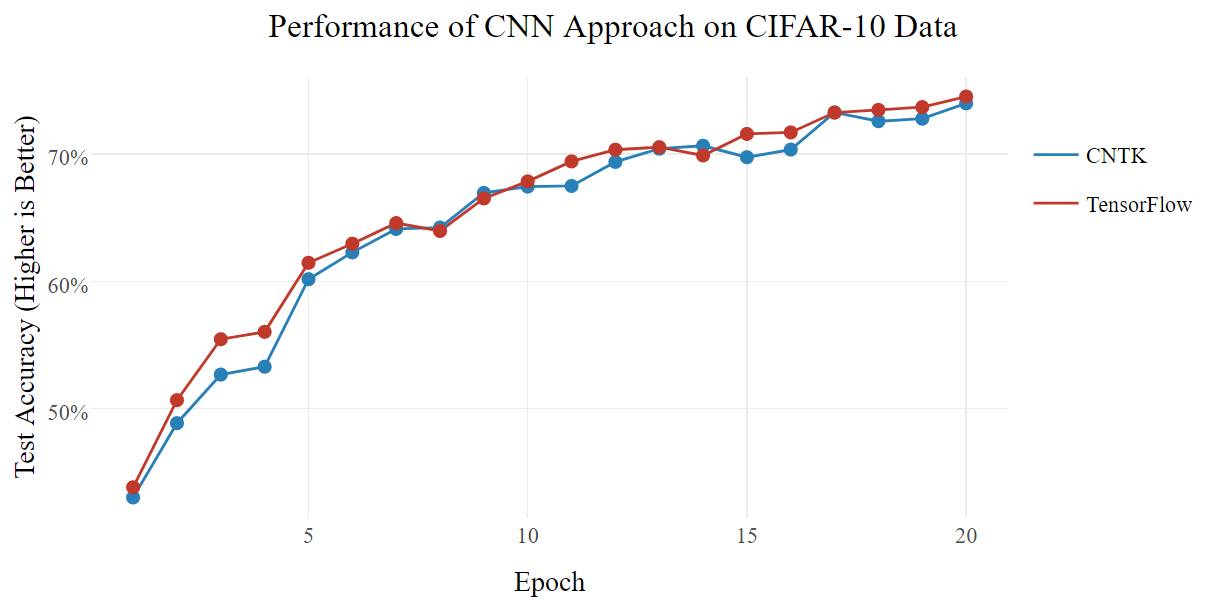
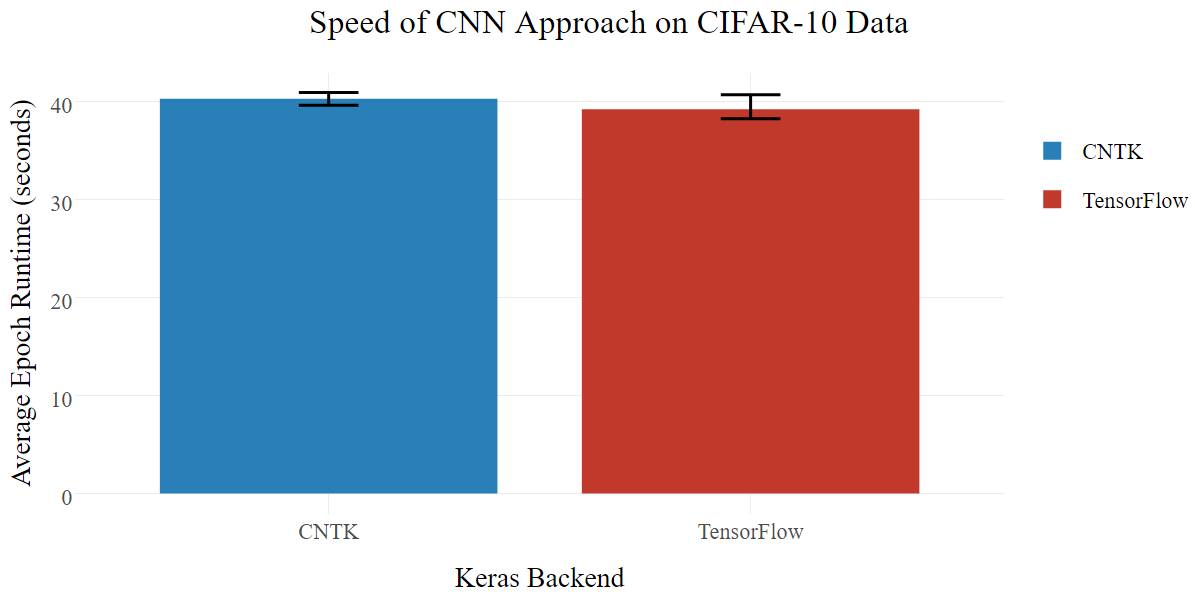
在这种情况下,两个后端的在准确率和速度上的性能均相等。也许 CNTK 更利于 MLP,而 TensorFlow 更利于 CNN,两者的优势互相抵消。
尼采文本生成
基于 char-rnn(https://github.com/karpathy/char-rnn)的文本生成(lstm_text_generation.py)很受欢迎。具体来说,它使用 LSTM 来「学习」文本并对新文本进行抽样。在使用随机的尼采文集(https://s3.amazonaws.com/text-datasets/nietzsche.txt)作为源数据集的 Keras 例子中,该模型尝试使用前 40 个字符预测下一个字符,并尽量减少训练的损失函数值。理想情况的是损失函数值低于 1.00,并且生成的文本语法一致。
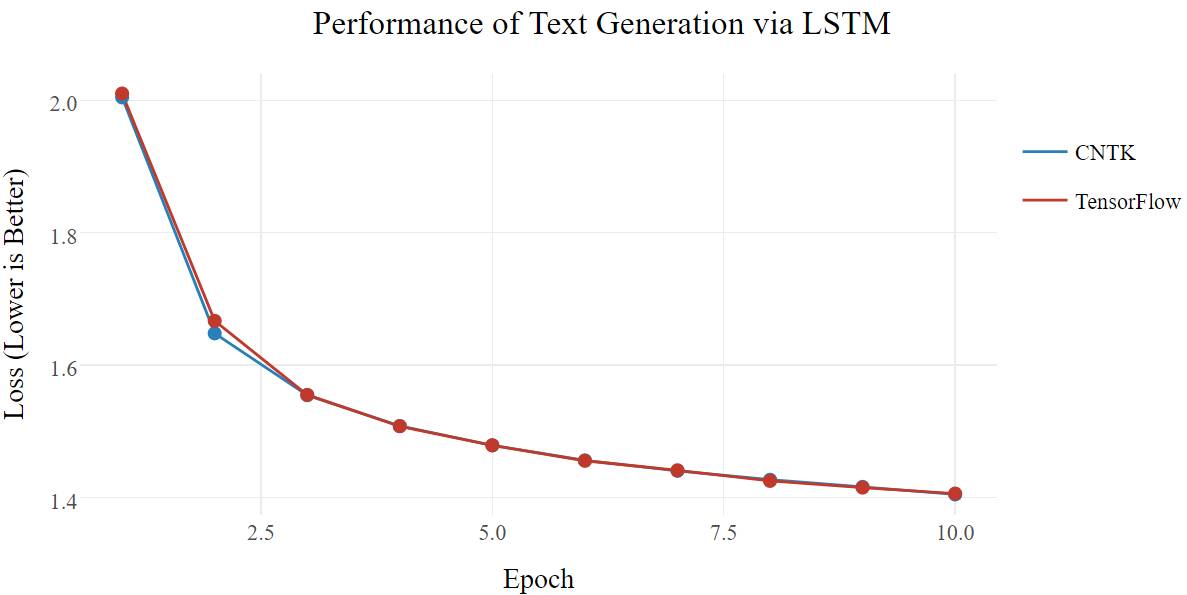
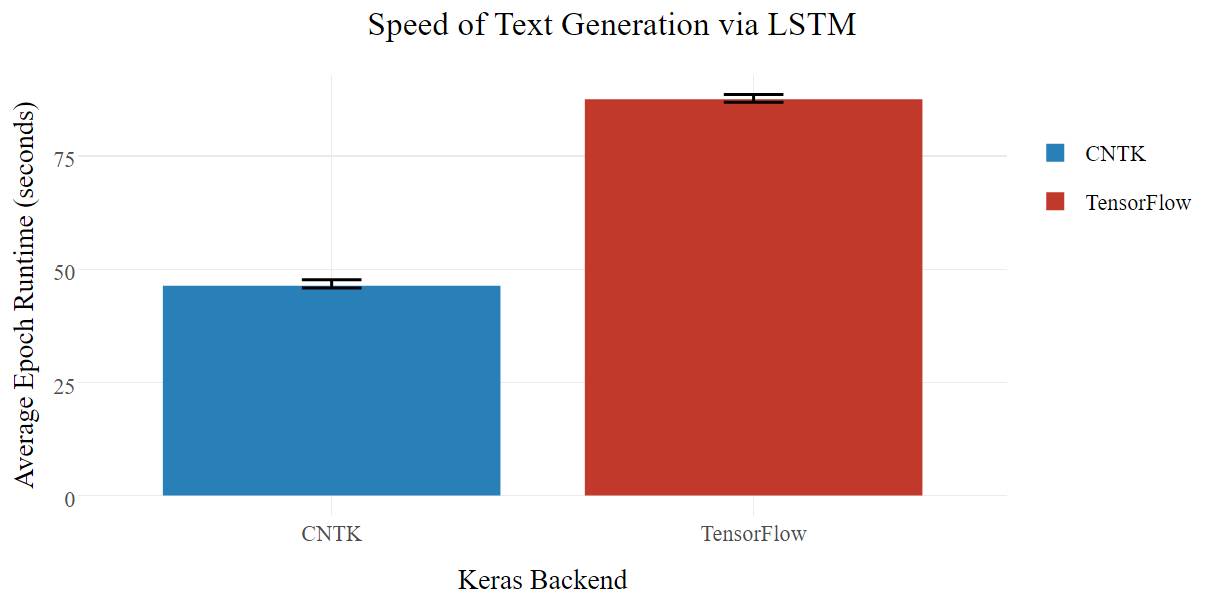
两者的损失函数值随时间都有相似的变化(不幸的是,1.40 的损失函数值下,仍有乱码文本生成),由于 LSTM 架构,CTNK 的速度更快。
对于下一个基准测试,我将不使用官方的 Keras 示例脚本,而是使用我自己的文本生成器架构(text_generator_keras.py),详见之前关于 Keras 的文章(http://minimaxir.com/2017/04/char-embeddings)。
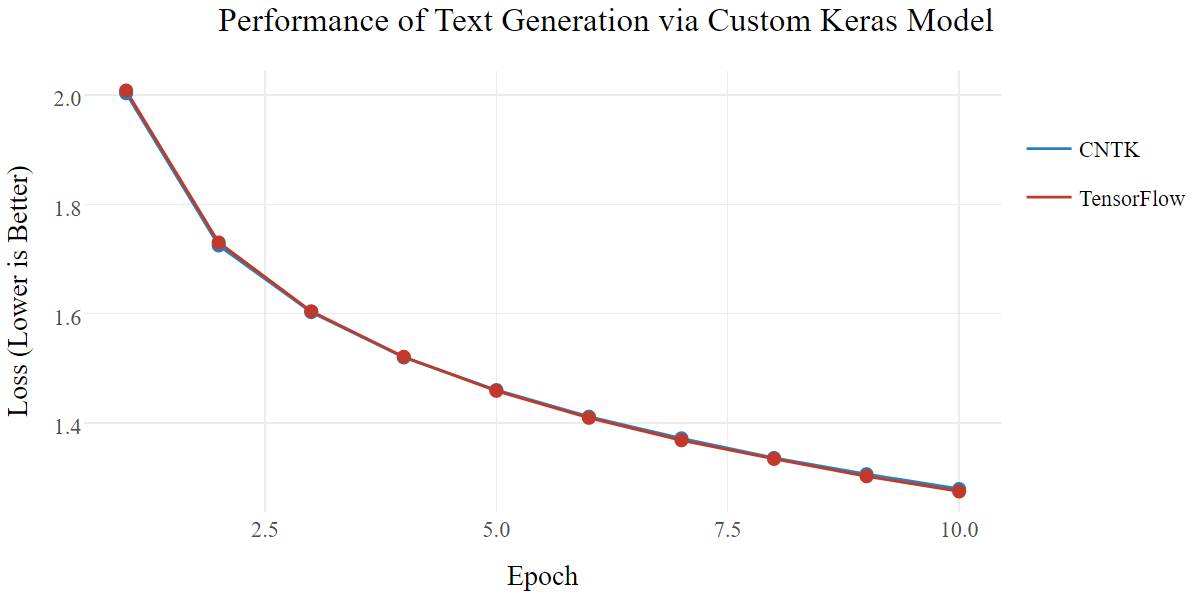
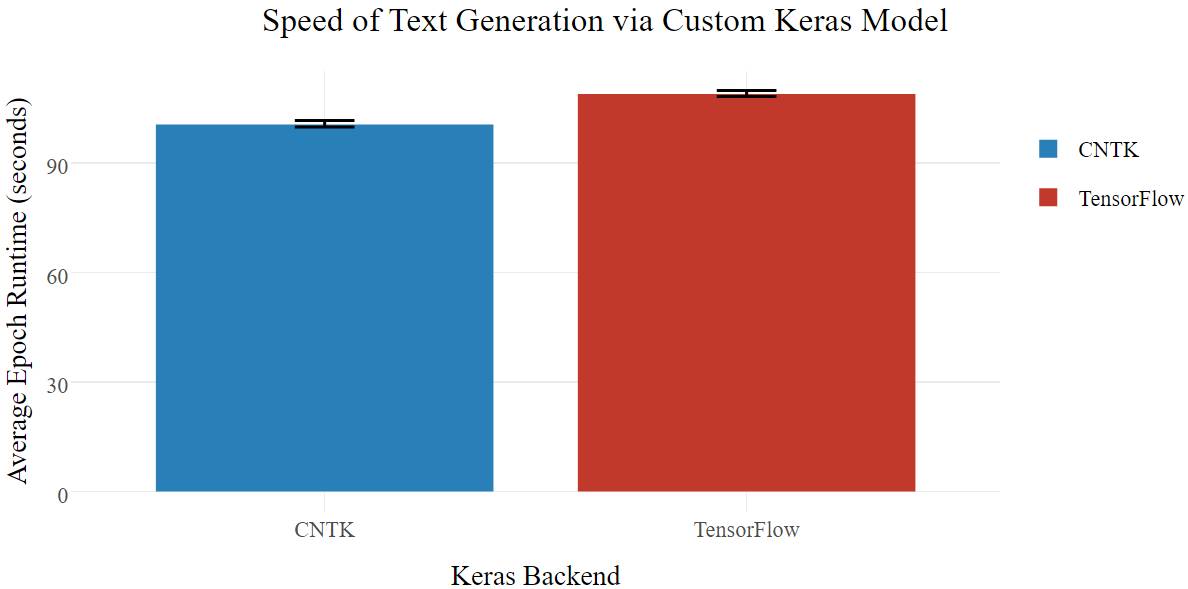
我的网络避免了过早收敛,对于 TensorFlow,只需损失很小的训练速度;不幸的是,CNTK 的速度比简单模型慢了许多,但在高级模型中仍然比 TensorFlow 快得多。
以下是用 TensorFlow 训练的我的架构模型生成的文本输出:
hinks the rich man must be wholly perverity and connection of the english sin of the philosophers of the basis of the same profound of his placed and evil and exception of fear to plants to me such as the case of the will seems to the will to be every such a remark as a primates of a strong of
[...]
这是用 CNTK 训练的模型输出:
(_x2js1hevjg4z_?z_aæ?q_gpmj:sn![?(f3_ch=lhw4y n6)gkh
kujau
momu,?!ljë7g)k,!?[45 0as9[d.68éhhptvsx jd_næi,ä_z!cwkr"_f6ë-mu_(epp
[...]
等等,什么?显然,我的模型架构导致 CNTK 在预测时遇到错误,而「CNTK+简单的 LSTM」架构并没有发生这种错误。通过质量评估,我发现批归一化(batch normalization)是错误的原因,并及时提出了这个问题(https://github.com/Microsoft/CNTK/issues/1994)。










