1、SHA-1算法
SHA-1的输入是最大长度小于
2
64
位的消息,输入消息以512位的分组为单位进行处理,输出是160位的消息摘要。SHA-1具有实现速度高、容易实现、应用范围广等优点,
其算法描述如下。


图 单个512位消息块的处理流程
SHA-1的步函数如图所示,它是SHA-1最为重要的函数,也是SHA-1中最关键的部件。
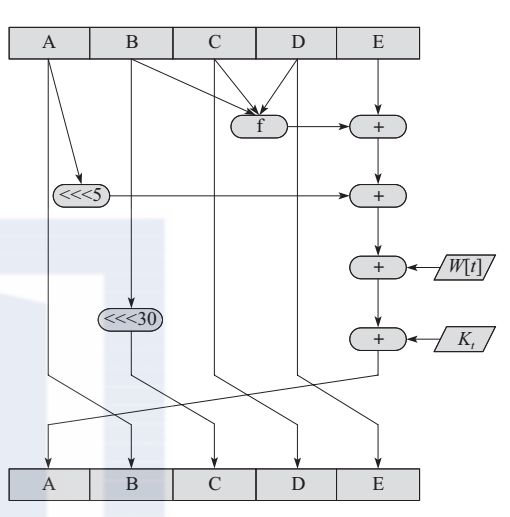
图 SHA-1的步函数
SHA-1每运行一次步函数,A、B、C、D的值就会依次赋值给B、C、D、E这几个寄存器。同时,A、B、C、D、E的输入值、常数和子消息块在经过步函数运算后就会赋值给A。

其中,t是步数,0≤t≤79,
W
t
是由当前512位长的分组导出的一个32位的字,
K
t
是加法常量。
基本逻辑函数f的输入是3个32位的字,输出是一个32位的字,其函数表示如下。


对于每个输入分组导出的消息分组
w
t
,前16个消息字
w
t
(0≤t≤15)即为消息输入分组对应的16个32位字,其余
w
t
(0≤t≤79)可按如下公式得到:
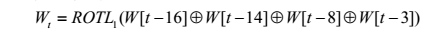
其中,
ROTL
s
表示左循环移位s位,如图所示。
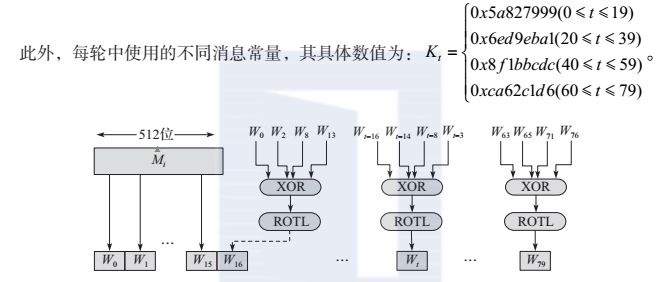
图 SHA-1的80个消息字的产生过程
2、SHA-2算法
SHA-2系列Hash算法,其输出长度可取SHA-2系列哈希算法的输出长度可取224位、256位、384位、512位,分别对应SHA-224、SHA-256、SHA-384、SHA-512。它还包含另外两个算法:SHA-512/224、SHA-512/256。比之前的Hash算法具有更强的安全强度和更灵活的输出长度,其中SHA-256是常用的算法。下面将对前四种算法进行简单描述。
SHA-256算法
SHA-256算法的输入是最大长度小于
2
64
位的消息,输出是256位的消息摘要,输入消息以512位的分组为单位进行处理。算法描述如下。
(1)消息的填充
添加一个“1”和若干个“0”使其长度模512与448同余。在消息后附加64位的长度块,其值为填充前消息的长度。从而产生长度为512整数倍的消息分组,填充后消息的长度最多为
2
64
位。
(2)初始化链接变量
链接变量的中间结果和最终结果存储于256位的缓冲区中,缓冲区用8个32位的寄存器A、B、C、D、E、F、G和H表示,输出仍放在缓冲区以代替旧的A、B、C、D、E、F、G、H。首先要对链接变量进行初始化,初始链接变量存储于8个寄存器A、B、C、D、E、F、G和H中:

初始链接变量是取自前8个素数(2、3、5、7、11、13、17、19)的平方根的小数部分其二进制表示的前32位。
(3)处理主循环模块
消息块是以512位分组为单位进行处理的,要进行64步循环操作(如图所示)。每一轮的输入均为当前处理的消息分组和得到的上一轮输出的256位缓冲区A、B、C、D、E、
F、G、H的值。每一步中均采用了不同的消息字和常数,下面将给出它们的获取方法。
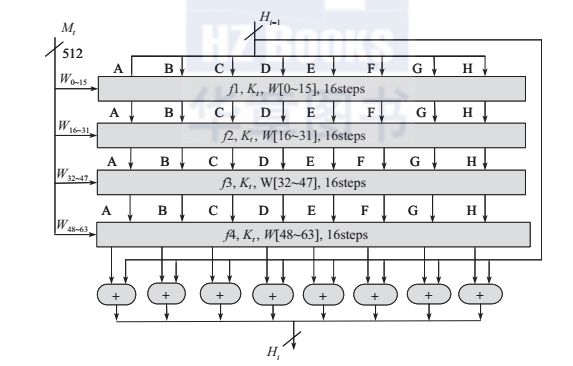
图 SHA-256的压缩函数
(4)得出最终的Hash值
所有512位的消息块分组都处理完以后,最后一个分组处理后得到的结果即为最终输出的256位的消息摘要。
步函数是SHA-256中最为重要的函数,也是SHA-256中最关键的部件。其运算过程如图所示。
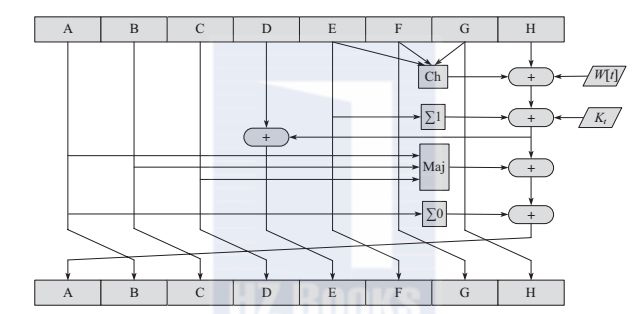
图 SHA-256的步函数

根据
T
1
、
T
2
的值,对寄存器A、E进行更新。A、B、C、E、F、G的输入值则依次赋值给B、C、D、F、G、H。


K
t
的获取方法是取前64个素数(2,3,5,7,……)立方根的小数部分,将其转换为二进制,然后取这64个数的前64位作为
K
t
。其作用是提供了64位随机串集合以消除输入数据里的任何规则性。
对于每个输入分组导出的消息分组
W
t
,前16个消息字
W
t
(0≤t≤15)直接按照消息输入分组对应的16个32位字,其他的则按照如下公式来计算得出:
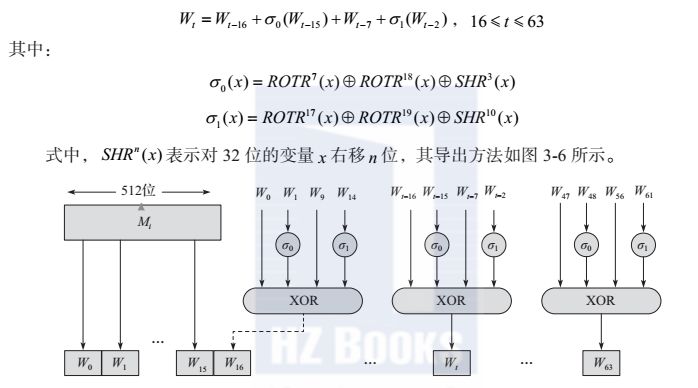
图 SHA-256的64个消息字的生成过程
SHA-512算法
SHA-512是SHA-2中安全性能较高的算法,主要由明文填充、消息扩展函数变换和随机数变换等部分组成,初始值和中间计算结果由8个64位的移位寄存器组成。该算法允许输入的最大长度是
2
128
位,并产生一个512位的消息摘要,输入消息被分成若干个1024位的块进行处理,具体参数为:消息摘要长度为512位;消息长度小于
2
128
位;消息块大小为1024位;消息字大小为64位;步骤数为80步。下图显示了处理消息、输出消息摘要的整个过程,该过程的具体步骤如下。

图 SHA-512的整体结构

初始链接变量采用big-endian方式存储,即字的最高有效字节存储于低地址位置。初始链接变量取自前8个素数的平方根的小数部分其二进制表示的前64位。




