监督学习:监督学习是最常见的分类问题,通常是让计算机去学习我们已经创建好的分类系统。
无监督学习:与监督学习相比,无监督学习没有预先标注好的分类系统。在无监督学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
半监督学习:是介于监督学习和无监督学习之间的一种极其学习方式,是模式识别和机器学习领域研究的重点问题。
强化学习:强化学习通过观察来学习动作的完成,每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
MLlib(Machine Learning lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。具有速度快、易用性、集成度高等特点。
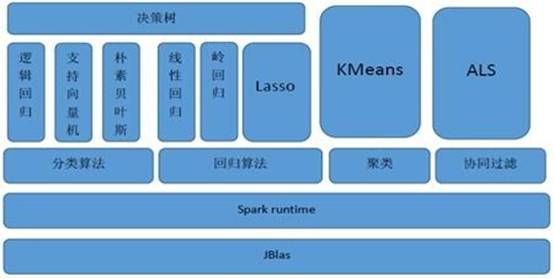
底层基础:包括Spark的运行库、矩阵库和向量库;
算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法;
实用程序:包括测试数据的生成、外部数据的读入等功能。
4.1 MLlib支持本地的密集向量和稀疏向量,并且支持标量向量
Vectors
MLlib支持本地矩阵和分布式矩阵
LabelPoint (Double目标, Vectors特征)
RowMatrix
IndexedRowMatrix
CoordinateMatrix
4.2本地矩阵Matrix
importorg.apache.spark.mllib.linalg.{Matrix, Matrices}
//创建密集矩阵((1.0, 2.0),(3.0, 4.0), (5.0, 6.0))
val dm: Matrix = Matrices.dense(3, 2,Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
//创建稀疏矩阵 matrix((0.0, 1.0, 3.0), (0.0, 2.0, 1.0), (9.0, 6.0, 8.0))
val sm: Matrix = Matrices.sparse(3, 2,Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8))
4.3分布矩阵RowMatrix
import org.apache.spark.mllib.linalg.Vector
importorg.apache.spark.mllib.linalg.distributed.RowMatrix
val rows: RDD[Vector] = ... // an RDD oflocal vectors
val mat: RowMatrix = new RowMatrix(rows) //基于RDD[Vector]创建RowMatrix
val m = mat.numRows()//获取行数
val n = mat.numCols()//获取列数
5.1分类算法属于监督式学习,使用类标签已知的样本建立一个分类函数或分类模型,应用分类模型,能把数据库中的类标签未知的数据进行归类。MLlib目前支持分类算法有:逻辑回归、支持向量机、朴素贝叶斯和决策树。
5.2回归算法属于监督式学习,每个个体都有一个与之相关联的实数标签,并且我们希望在给出用于表示这些实体的数值特征后,所预测出的标签值可以尽可能接近实际值。MLlib 目前支持回归算法有:线性回归、岭回归、决策树。
5.3聚类算法是观察式学习,在聚类前可以不明确类别甚至不给定类别数量,聚类是无监督学习的一种,MLlib目前支持广泛使用的K-Means聚类算法。
5.4协同过滤算法常被应用于推荐系统,这些技术旨在补充用户-商品关联矩阵中所缺失的部分。MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。
协同过滤算法分类:基于用户过滤的推荐模型、基于产品过滤的推荐模型、基于协同过滤的推荐模型、基于关联规则的推荐模型。
CDA数据分析研究院为解决当下企业招人难、学员就业难的问题所研发的大数据课程,以数据分析理论与实践案例结合的方式讲授,内容覆盖了国内企业招聘大数据分析师岗位所需的技能,学员经过系统全面的脱产学习(数理统计和数据挖掘算法、Java、Hadoop、Spark、Scala等),达到企业用人标准,快速在大数据时代找准工作定位。
想转行大数据,还在犹豫什么?听听业内人士分享大数据在企业中的应用
座机:010-68456523(张老师)
QQ:2931495854
邮箱:[email protected]










