引言
本篇文章属于“多传感器融合”方法和技术专栏的第一篇,后续还有一篇在“多传感器融合”方面针对“多观测数据信息整合方法”的文章,具体可详见链接,欢迎感兴趣的朋友交流和讨论,也希望知乎上的大佬批评和指正文章中不恰当的地方:
https://zhuanlan.zhihu.com/p/569124652
1 背景概述
移动机器人、无人机或者无人船等是不能够像工业机器人利用关节处的力矩传感器和编码器的读数直接进行位姿的解算的,抛开工业机械设计制造及其装配时带来的误差,移动机器人、无人机或者无人船等内置的传感器往往会因为轮子打滑、imu噪声等问题引入难以忽略的误差,由此机器人学中的状态确认就成了一种概率性质的状态估计与更新方法论了。简单的问题分类与描述如下:
-
-
-
-
建图、定位、SLAM的方法都是基于状态估计与更新;
那么结合上面的问题和描述,需要解决的事情大致就这么几件:明确状态量的组成(变量?定位?地图模型?)获取各个位置的传感器读数、整合传感器数据生成地图、将传感器读数与地图模型建立关系、计算在地图模型中的位置、估计位置和模型的确定性、提升状态估计的正确性。
针对以上问题,各理论方法在过去几十年的时间内被提出和应用在机器人学中的基于概率(贝叶斯)理论的位姿估计问题上,从80年代甚至更早,高斯模型、线性近似模型和位置跟踪的方法论“组成”了最初的Kalman Filters框架,在95年代,离散的方法论开始在拓扑型表征和栅格模型表征上进行全局定位、重定位和不确定处理(POMDPs)的研究,再到了99年,无参滤波器Particle Filters开始在基于采样方法的定位、重定位方向上大展身手,而千禧年后各个假说和前提条件下的滤波器研究成了研究的热门,如EKF的各个变体:ESKF、MSCKF和IKF都是针对不同的应用情况和追求被提出并得到了广泛的应用和优化。
本文将从贝叶斯公式及其相关的概率基础知识入手,遍历KF、EKF和UKF等基本的带参数的滤波器原理与公式,再谈谈ESKF、IKF和MSCKF这类EKF的变体滤波器,最后进入无参滤波器PF及其优化的策略。
2 概率基础
2.1 贝叶斯公式
联合概率密度分解成条件概率密度和边缘概率密度的乘积:

重新整理可以得到贝叶斯公式:
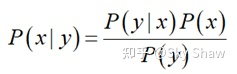
如果移植先验概率密度函数P(x),以及传感器模型P(y|x),那么就可以根据贝叶斯公式推断出后验概率密度,即:
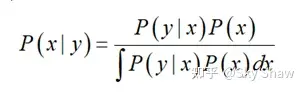
以上过程即贝叶斯推断,也称为贝叶斯估计。
2.2 高斯概率密度函数
一维高斯分布:

多维高斯分布:
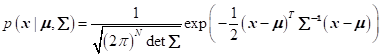
例如,二维高斯分布为:
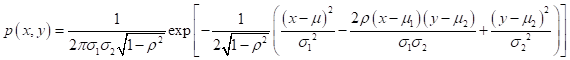
其中,

为x,y的相关系数,当x,y线性无关时,上式即等于0.
2.3 联合高斯概率密度函数
若有高斯分布:
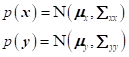
则它们的联合概率密度函数为
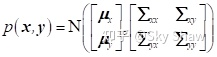
根据舒尔补公式:
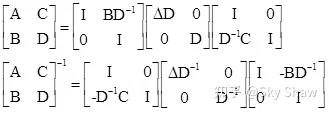

称为矩阵D关于原矩阵的舒尔补。利用舒尔补公式,联合分布的方差矩阵可以写成:
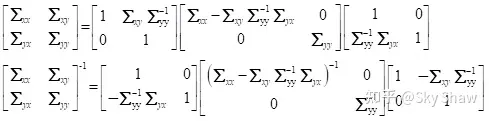
联合高斯分布 的指数部分的二次项包括以下内容:

因此有
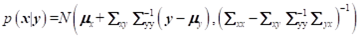
2.4 高斯随机变量的线性分布
假设
y=Gx+n
, G 是一个常量矩阵, n 为零均值白噪声,在实际中指的是观测噪声。则有:

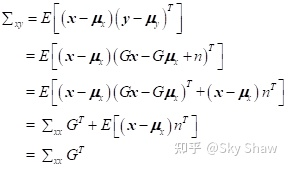

3 贝叶斯滤波
所谓的机器人状态估计,其实就是估计机器人在当前时刻的状态x_t。这是一个向量,包含了我们想要估计的量,比如机器人的位置、姿态和速度。估计所需的信息来自两个方面。内部传感器提供的信息记作u__t,通常是运动信息,比如里程计或IMU提供的位移、速度等信息。外部传感器提供的信息记作z_t,通常是观测信息,比如激光测距仪提供的距离信息、相机提供的像素信息等。于是,状态估计问题可以描述为:在给定从1时刻到t时刻的所有传感器信息后,求条件概率:
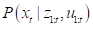
该条件概率称为贝叶斯后验概率,记作bel(x_t)。所谓“后验”是结合了观测之后的概率。既然如此,当然就存在一个“先验”概率,即结合观测之前的概率,记作
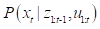
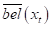
为了计算简便,不可能每次都用所有时刻的传感器信息来估计后验概率。
最明智的做法是迭代估计,用上一时刻的后估计当前时刻的后验:
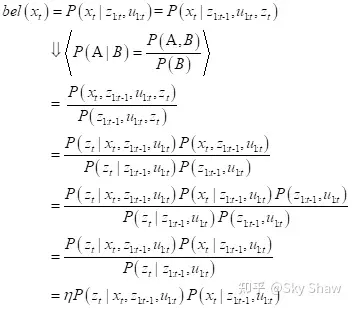
其中,分母与x_t无关,可以当做常量,用归一化因子代替。注意,这里用的是所谓的条件贝叶斯公式,

始终作为条件变量,不受贝叶斯公式影响。
这个概率所依赖的条件太多,为了能够方便地求解它,我们不妨做一假设:
马尔可夫假设:系统当前时刻的状态只与上一个时刻有关,与之前任意时刻的状态都没有关系。当然,马尔可夫假设的成立是有条件的,它要求状态变量 具有完整性,换句话说,系统的全部信息都包含在了 中,不存在其它随机变量对系统状态产生影响。
考虑马尔可夫假设后,后验概率可以进一步简化为:
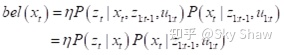
也就是说,
当前时刻的观测z_t只依赖于当前状态x_t,与之前的状态和传感器数据无关
。仔细观察s上式,可以发现右侧的第二个概率恰好是
即:
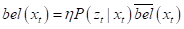
现在唯一的问题是后验概率如何计算,将其按照全概率公式展开:

这里利用了连续情况的全概率公式,考虑所有可能的x_(t-1)所能生成的x_t。再次考虑马尔可夫假设,将上式简化:
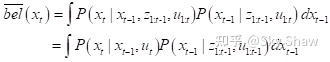
其中,第一行去掉了对
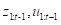
的依赖,因为它们所产生的影响已经完全包含在x_(t-1)中。第二行去掉了对u_t的依赖,因为u_t不可能对上一时刻的状态x_(t-1)产生影,再者可以发现积分号中的第二个概率恰好是
上一时刻
的后验概率,即:

至此,我们实际上把贝叶斯滤波分成了两个步骤。第一步称为
预测
,从bel[x_(t-1)]预测bel[x_t]。第二步称为
更新
,从bel[x_t]更新到其后验概率。在应用贝叶斯滤波时,需要事先根据具体的传感器类型确定两个条件概率:


然后利用传感器数据u_t和z_t不断进行预测和更新,得到当前时刻机器人的状态。
4 卡尔曼滤波
在实际应用中,如何根据具体的传感器类型确刚刚上述的那两个条件概率往往会使得计算很复杂,甚至无法顺利进行,特别是
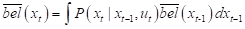
还包括一个积分。卡尔曼滤波则是为我们提供了一套针对在
线性系统
中的解决方案,保证求解的时效性。在卡尔曼滤波中,系统的状态改变和观测服从下面的线性方程:

其中,状态量中引入高斯随机变量,表示由状态转移引进的不确定性;观测量中也是同理引入分布是均值为0,方差为 Q的高斯随机变量。那么刚刚上述的那两个条件概率分别表示为:
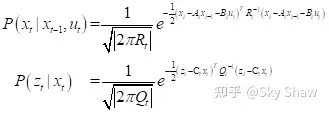
对于条件概率来说,已知的条件已经不再是随机变量,因此第一个式子中的x_(t-1)和u_t,第二个式子中的x_t应按照常量对待。只在状态量和观测量中引入的噪声是服从高斯分布的随机变量。因此,两个式子得到的结果仍然是高斯分布:

4.1 KF第一部分:预测
接下来,仍然按照贝叶斯滤波的两个步骤:
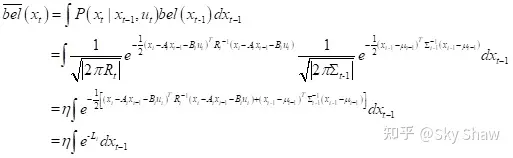
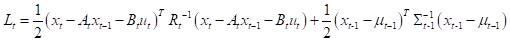
直接求积分很困难,但可以尝试利用概率密度函数来求。我们就可以把拆分成两部分

上右边的第一项满足高斯分布指数部分的形式,第二部分是后面的常数项。利用以下操作:

为了计算二次型的系数,计算 Lt的一阶、二阶导数:
假设
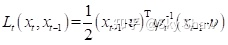
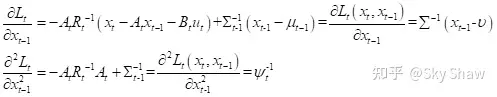
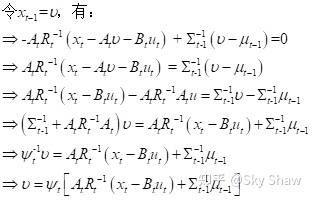
因此可以将二次型函数 定义为:
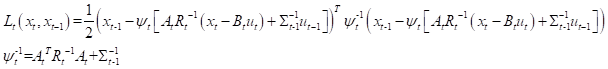


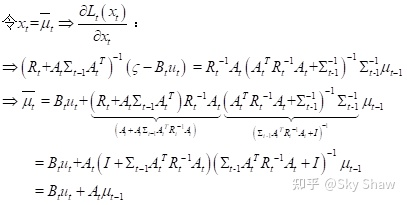
最后可以得到,预测部分的分布为:
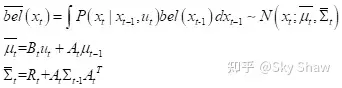
4.2 KF第二部分:更新



5 扩展卡尔曼滤波算法(EKF)
卡尔曼滤波的前提是系统的状态改变和观测是线性的,但是实际应用中系统是非线性的。EKF通过一个一阶泰勒展开的线性系统来近似非线性。假设系统的状态和观测方程如下:


6 无迹卡尔曼滤波算法(UKF)
该算法的核心思想是:采用UT变换,利用一组Sigma采样点来描述随机变量的高斯分布,然后通过非线性函数的传递,再利用加权统计线性回归技术来近似非x线性函数的后验均值和方差。
相比于EKF,UKF的估计精度能够达到泰勒级数展开的二阶精度。其本质是:近似非线性函数的均值和方差远比近似非线性函数本身更容易。
6.1 UT变换
y=f(x)是一个非线性变换, x为 n 维随机变量,UT变换根据一定的采样策略,获得一组Sigma采样点,并设定均值权值W和方差权值,来近似非线性函数的后验均值和方差。利用选取的Sigma采样点集进行非线性函数传递可得:

其中,y_i为Sigma采样经过非线性函数传递后对应的点。根据加权统计线性回归技术,可以近似得到y的统计特性:
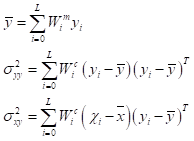
6.2 Sigma点采样策略
下面介绍两种经常使用的采样策略:
比例采样和比例修正对称采样
。



根据Sigma点采样策略不同,相应的Sigma点以及均值权值和方差权值也不尽相同,因此UT变换的估计精度也会有差异。但总体来说,其估计精度能够达到泰勒级数展开的二阶精度。
使用参数beta对高斯表示的附加的分布信息进行编码。如果分布是精确的高斯分布,则beta=2是最佳的选择。

6.3 UKF采样原则
为保证随机变量x经过采样之后得到的Sigma采样点仍具有原变量的必要特性,所以采样点的选取应满足:
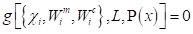
式中{}内的符号分别为Sigma采样点,均值权值和方差权值组成的集合;L为采样点个数,P为随机变量x的密度函数,g[~]确定x的相关信息。如果密度函数P(x)只有一、二阶矩时,可以写成:
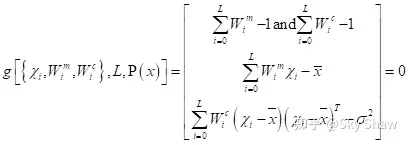


6.4 UKF的特点
UKF相比于EKF的精度更高一些,其精度相当于二阶泰勒展开,但速度会略慢一点。UKF另一个巨大优势是不需要计算雅克比矩阵,而有些时候雅克比矩阵也确实的我们无法获得的。
另外UKF与PF(粒子滤波)也有相似之处,只是无迹变换中选择的粒子是明确的,而粒子滤波中的粒子是随机的。随机的好处是可以用于任意分布,但也具有其局限性。因此对于分布近似为高斯分布的,采用UKF将更有效。
7 Error-state卡尔曼滤波(ESKF)
ESKF是一种典型的间接法滤波,其预测和更新过程都是针对系统的误差状态,再用修正后的误差状态修正系统状态。
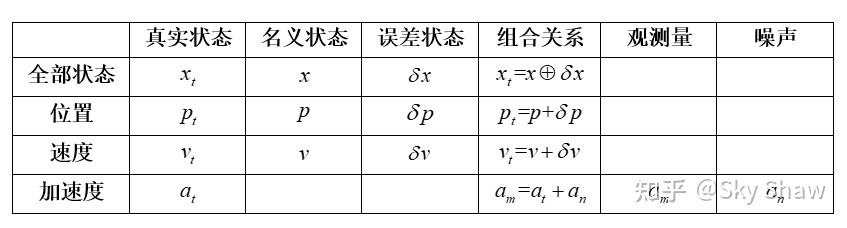
其核心在于将系统状态真值分解为系统名义状态值和误差状态值的结合。状态分解为两个部分组成:
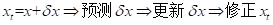
真实状态运动学:

名义状态运动学:

于是可以直接得到误差状态的运动学:
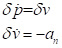
7.1 ESKF的优缺点
KF、EKF、UKF的系统模型都是直接描述系统状态,属于直接法滤波;ESKF的模型系统描述的是系统误差,而不是直接描述系统状态,需要通过转换得到系统状态,属于间接法滤波。ESKF的Error-State的值一般趋近于0,可以避免一些一阶部分可能出现的奇点,应用于惯导系统时的万向锁问题,提供所有时间内的线性有效性保证。而且Error-State很小,可以保证在泰勒展开中的二次部分忽略不计,使得雅可比的计算简单快速(计算复杂度UKF>EKF>ESKF>KF)。由于Error-State的动力系统通常比较缓慢,因此所有较大的分量被集中到计算名义状态,以为着可以使卡尔曼滤波的更新过程频率低于预测过程。
8 迭代卡尔曼滤波(IKF\IEKF)
IKF全称为Iterated Kalman filter,是基于Extended Kalman filter(EKF)的滤波框架,在其中应用高斯牛顿迭代法而改良的方法,该方法的策略是牺牲掉少量计算时间,以优化EKF线性近似时产生的近似误差。本质上是在EKF框架中构建非线性优化模型以求解状态后验的最大似然,以提升EKF的精度。
IKF的预测与EKF几乎相同,IKF算法的主要贡献在于其更新阶段的优化,同时算法将预测阶段的状态估计值作为了当前阶段的观测值。以典型的IKF实现案例(Fast-LIO系列)来说,整个系统中有两个关键的时间点:利用每一次IMU的数据进行积分预测,利用每一次激光数据进行观测迭代更新。引申到通用的模式下,其实也就是需要在更新开始前确认清楚当前的预测状态量、对应的预测状态量协方差、当前的观测量及其观测量协方差,以找到最好的位姿状态估计及其协方差估计。
IKF的算法流程如下:
-
-
-
针对第一个步骤预测积分就是先根据IMU的读数进行状态量预测和协方差预测
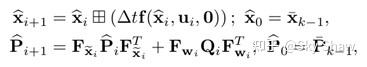
上式中的f即代表状态转移方程,Q为高斯白噪声w的协方差,Fw和Fx的定义式如下:

在上述中提到的两个关键时间点,该预测积分的过程会在每一次IMU读数到来的时候进行积分传播,直到下一帧激光数据来临时才结束进行更新操作 。

对于协方差的迭代更新,使用Matrix Inversion Lemma:

上式中P即为状态量的协方差矩阵,H表达为 的简写。进一步的分析可以看到,状态量的迭代更新与观测量z及其协方差R、预测状态及其协方差、观测方程g及其一阶导数H,整个迭代更新过程的converge条件就是达到局部最小值
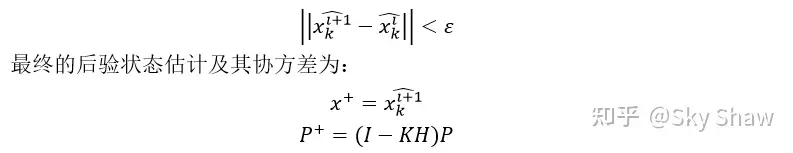
由此可得,整个状态向量的迭代过程若仅仅进行一次迭代,则IKF系统就成了EKF。
9 多状态约束下的卡尔曼滤波(MSCKF)
MSCKF是用于估算VIO的滤波算法,全称是Multi-State Constraint Kalman Filter,最早是在论文《A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation》中出现。
MSCKF是沿用EKF的框架,优化具体的实现以解决EKF-SLAM的维数爆炸问题为目标。在传统融合IMU数据和VO的EKF-SLAM框架中会将VO中的各个特征点信息加入到待解算的状态向量中(其中还包括了IMU的数据信息状态),也就是随着系统的运行,VO的关键帧越来越多,其VO中的特征点也会随之变得非常多,导致需要进行解算的状态向量维数会变得非常大。MSCKF则通过将不同时刻的VO相机关键位姿加入到状态向量,而不再将特征点加入到状态向量,如此操作的原因在于特征点可以被多个相机看到从而能够与多个相机状态(Multi-State)之间构建约束(Constraint),进而利用约束的信息构建观测模型对EKF进行更新。由于相机位姿的个数会远小于特征点的个数,MSCKF状态向量的维度相较EKF-SLAM大大降低,并通过滑动窗口(Sliding Window)历史的VO状态会不断移除从而对MSCKF后端的计算量进行限定,由此MSCKF的计算消耗较之传统方法更低,运行更加鲁棒。
所以根据上述MSCKF的原理,其中预测过程和EKF一致(利用IMU数据信息进行积分),关键的在于使用VO的信息来构建约束(利用3D特征点到VO相机的重投影坐标和实际观测到坐标构建误差方程)以更新IMU预测的状态向量。
MSCKF算法步骤如下:
-
预测(IMU积分)
:先利用IMU加速度和角速度对状态向量中的IMU状态进行预测,一般会处理多帧IMU观测数据。
-
相机状态扩增
:每来一张图片后,计算当前相机状态并加入到状态向量中, 同时扩充状态协方差.
-
特征点三角化
:然后根据历史相机状态三角化估计3D特征点(特征点跟丢时才进行操作)
-
特征更新
:再利用特征点对多个历史相机状态的约束,来更新状态向量。注意:这里不只修正历史相机状态,因为历史相机状态和IMU状态直接也存在关系(相机与IMU的外参),所以也会同时修正IMU状态。
-
滑动窗口历史相机状态移除
:如果相机状态个数超过N,则剔除最老或最近的相机状态以及对应的协方差.










