作者简介:钱钤现就职于某创业公司的高级程序员,毕业于清华大学,是待字闺中的忠实粉丝和撰稿人。也欢迎广大的读者投稿,稿件一经采用,陈老师请你吃饭。
这篇技术文章,是对
Koth大神上一篇关于深度学习分词技术博文
的分析理解介绍,目的是分享深度学习在分词方面应用的一个学习过程,文章是对涉及到的理论进行分析,进而对最后要介绍的技术方案做更好的理解,请不要被“深度学习理论”吓到了。如果对深度学习很熟悉,可以直接跳到最后一个小节。
深度学习与自然语言处理
深度学习是近几年来发展十分迅速的领域,相信不少人都对此进行过研究,这一小节只是先简单介绍一下它。深度学习是一种特征学习的方法,区别于其他机器学习方法,它能够由低层到高层自动地去学习一个特征的层次结构。深层神经网络是由沃伦·麦卡洛克 (Warren McCulloch) 在 1943 年提出的,具备多层神经网络结构,一开始由于层数多且随机初始化造成训练结果不稳定,后来Hinton等人通过基于受限贝尔兹曼机的逐层无监督训练的预处理结果,在图像识别领域取得突破,而随后本希奥
(Bengio
)和萨拉赫丁诺夫 (Salakhutdinov)提出了基于自动编码的预处理方法,也取得了比较好的效果。
除了在图像处理领域的突破性进展,深度学习在自然语言处理领域也受到更多重视,但这两个领域有所不同。首先对于图像来说,可以通过向量空间表示输入信号,而自然语言处理大部分情况以词为基础进行处理,词向量的转换是第一步;其次,自然语言处理中涉及到对序列以及句法、翻译等更复杂的树形结构的处理,通常需要特殊的神经网络结构。
RNN与LSTM
本小节将对RNN和LSTM模型作对比阐述,并更深入地对LSTM的模型机理进行了解析。
RNN是一种为了克服普通DNN缺乏对时间序列上的变化进行建模的能力,而输入样本的时间序列对自然语言处理、语音识别等应用十分重要,为了适应这种需求,循环神经网络结构RNN产生了。
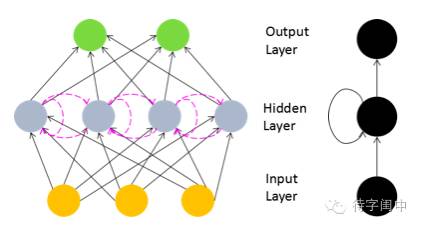
在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,比如在下面的RNN模型结构中,隐藏节点的输入,除了来自输入层神经元的信号,还有来自上一个时刻其自身的输出。
另外,RNN模型展开后就能够看出随时间变化的模拟能力了,如下图所示的展开网络。因此RNN就能够学出自然语言处理、语音识别、手写识别等应用场景所需要的,较为复杂的树型结构。
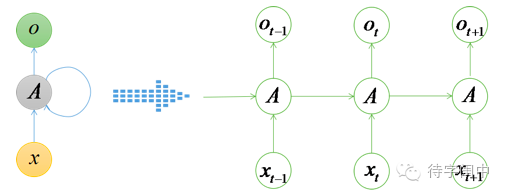
这种节点展开的结构理论上可以学习无限长的序列,然而在实践中却并非如此,Bengio等人经过实践发现了一些影响这种结果的原因,即“梯度消失”,神经网络随着层数的增加,这种情况会越来越严重,反向传播一层,梯度衰减为上一层的0.25,层数多了以后,底层神经元基本接收不到信号。RNN在时间传播上的这种梯度消失问题,被一种称为LSTM的长短时记忆单元较好的解决。LSTM的变体发展出很多,这里只介绍一个基本的LSTM单元的结构作为理解的基础,图如下所示(画全部解析图太复杂了,就借来博客中的图直接用了):
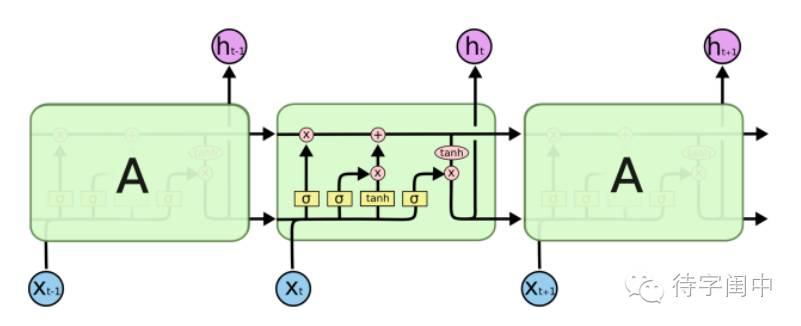
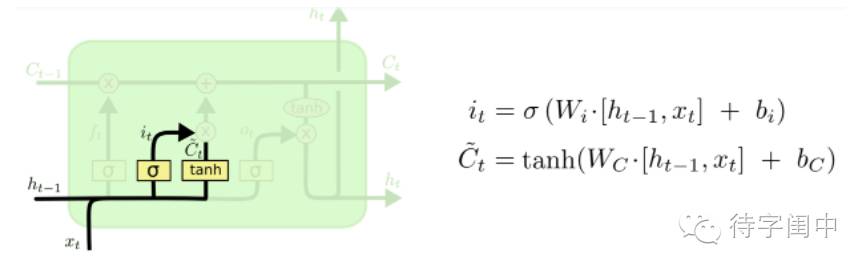
与RNN类似,LSTM的重复模块可以随时间传递信息,只是结构有所不同,不同于单一的神经网络层,LSTM用四个神经元进行信息交互。可以把词汇信息的交互理解为细胞状态在上图水平线上的传递,LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid (黄色背景单元)神经网络层和一个 pointwise(粉色背景单元) 乘法操作。
我们从左至右,按照细胞状态走向看LSTM的结构,下图所示,最左侧称之为“忘记门层”(forget gate),决定从细胞状态中丢弃信息,该门读取输入h(t-1) 和x(t) ,经过神经网络层后,输出一个0-1之间的数值f(t) 给状态 C(t-1),即从完全舍弃到完全保留之间的所有状态。用在语言模型场景中可以解释为,细胞状态带有的现有的词汇信息的记忆,词汇被正确识别后,希望在识别新词汇时不受之前的干扰,忘记之前的信息。
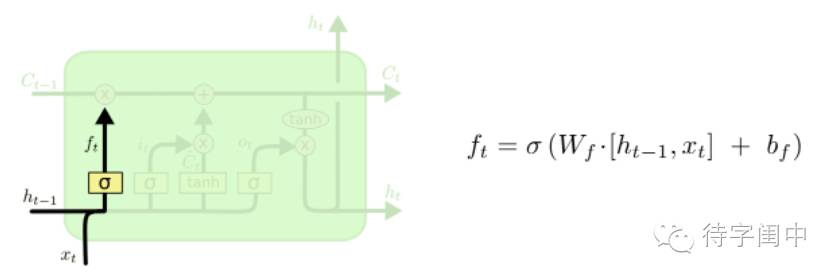
下面一步是更新旧细胞状态C(t-1) ,计算出经过忘记门层丢弃掉需要忘记的信息i(t)或上图指示的f(t)后,再叠加乘以下图所示的C~(t),这一步就丢弃掉不需要的旧有词汇的信息,添加信息将细胞状态更新为目标状态。