原文来源
:
medium
作者:William Koehrsen
「机器人圈」编译:嗯~阿童木呀
 使用Google预训练的Inception CNN模型进行图像分类
使用Google预训练的Inception CNN模型进行图像分类
现如今,可以说卷积神经网络是应用于
图像识别
领域最先进的一种技术,即识别图像中的人或汽车等目标。对于人类来说,可以很轻松地完成目标识别的任务,但是想要使用机器算法实现这一过程却是十分困难的,直到卷积神经网络的出现(
从1998年开始开发LeNet-5
),这一由来已久的状况开始有所好转。但在这看似具有挑战性的任务中,即使最好的计算机也并不是适用于所有人的。而从CNN设计的最新进展中可以看到,尤其是得益于廉价计算能力和诸如初始模块和跳过连接等增强技术的可用性,
具有更多层的更具深度的模型已经创建了在目标识别中能够与人类准确性相抗衡的模型。
此外,CNN已随时准备要在自动驾驶以至
医学成像评估
(这是一个电脑已经超越人类的领域)等领域产生具有实际价值的影响。然而,训练卷积神经网络,特别是实现用于更新模型参数的反向传播方法(
backpropagation method
),代价是非常昂贵的。一般来说,训练数据(标记图像)的数量越多,网络越深,训练时间就越长。降低网络深度或减少训练数据量都是不可取的,因为任何机器学习系统的
性能与高质量训练样本的数量是直接相关的
,而不是说网络越深(达到某一上限)表现就更好。
而诸如dropout或批量归一化等附加的性能增强技术,在提高性能的同时也增加了计算时间。
可以说,用一台个人计算机在数以万计的标签图像上适当地训练有用的图像识别网络可能需要花费几个月或更长的时间。此外,如果想要开发正确的架构并选择最佳超参数则需要对网络进行数百或数千次的训练,这就意味着如果我们将自己限于只用笔记本电脑来进行项目运行的话,我们最好准备:这个项目可能会需要几十年的时间。幸运的是,Google不仅开发了一系列图像分类理想架构的迭代(在2014年,GoogLeNet赢得了Imagenet大型视觉识别挑战(
Imagenet Large Scale Visual Recognition Challenge
),其中模型必须识别1000个不同类别的目标),而且还发布了在跨越1000个类别的120万张图像中进行训练的模型。这意味着,我们可以使用Google预先训练的模型来进行高精度的目标识别,而不用在训练周期之后建立自己的网络,且不用等待遥遥无期的训练周期。
Inception神经网络
Google拥有大量可用于
TensorFlow的神经网络模型
。在这里我们将使用的两个模型是Inception-v3和Inception-v4。
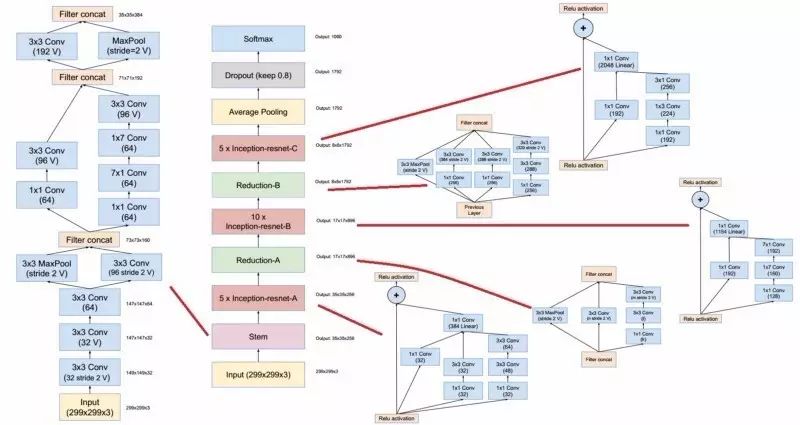
基本inception CNN架构
它们都使用了
inception模块
,这些模块采用不同大小的卷积内核,并在深度维度上叠加它们的输出,以捕获不同尺度上的特性。

Inception模块
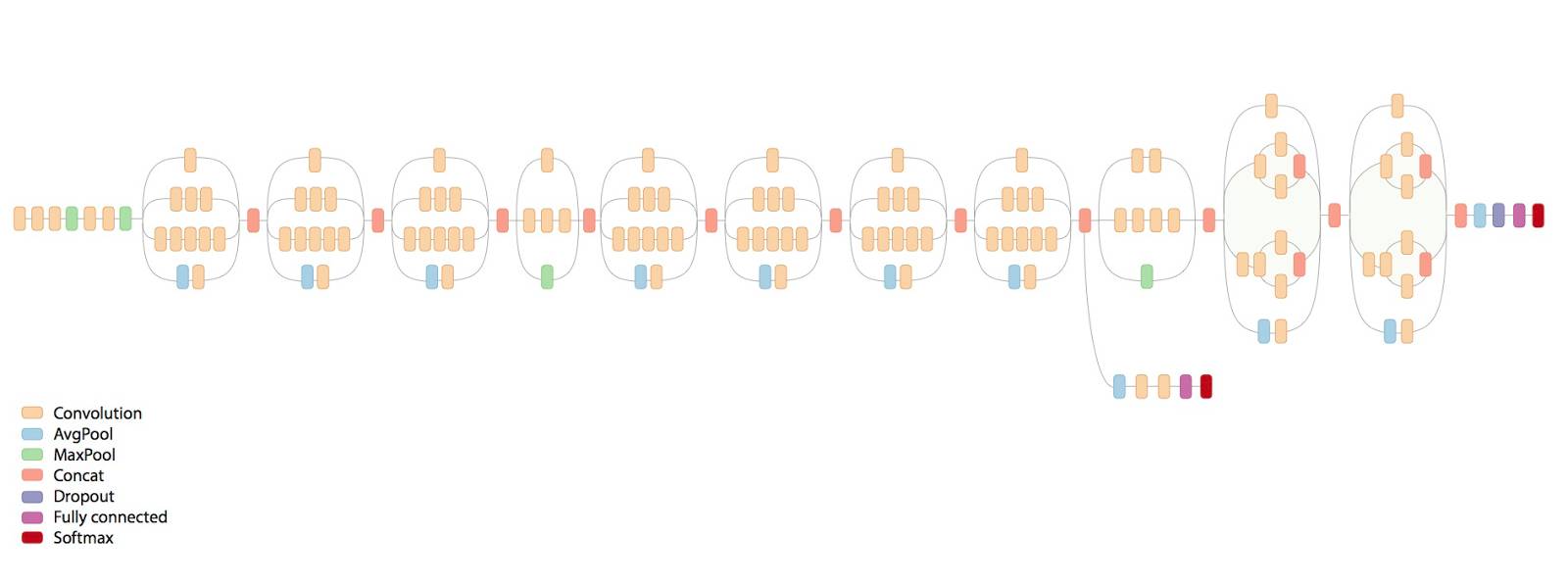
两个网络还借用了一个带有跳过连接的残差网络(
residual network
)的概念,即将输入添加到输出中,使得模型被强制地预测残差而不是目标本身。
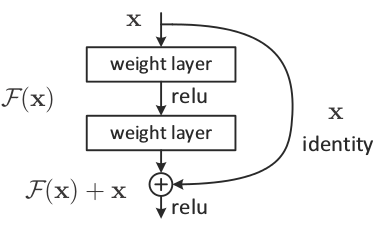
通常用于残差网络的跳过连接操作
使用该架构,incepv4能够在Imagenet数据集上实现80.2%的最高精度和95.2%的前5精度,或者换句话说,该网络只需要原时间的4/5就可以在图像中确定目标,且能够在前五名的概率输出中将正确预测率提高19/20倍。
Google开发的其他模型(特别是Inception-ResNet-v2)的运行效果更好,但Inception-v3和-v4网络仍然处于领先地位。
检索预训练模型
如果你想要获取适当的Python库,请访问tensorflow / models GitHub资源库并下载或复制相关的代码资源。我们将要做的所有工作都应该在the slim library中运行,所以你需要导航到该文件夹,并在其中创建一个新的Python脚本或Jupyter Notebook。下一步是下载Inception网络的最新检查点。
模型列表
可以在tensorflow /models Git Hub上找到。如果想要下载不同的模型,只需用你选择的架构替换“inception_v3_2016_08_28.tar.gz”(其他代码可能也需要做相应的修改)。

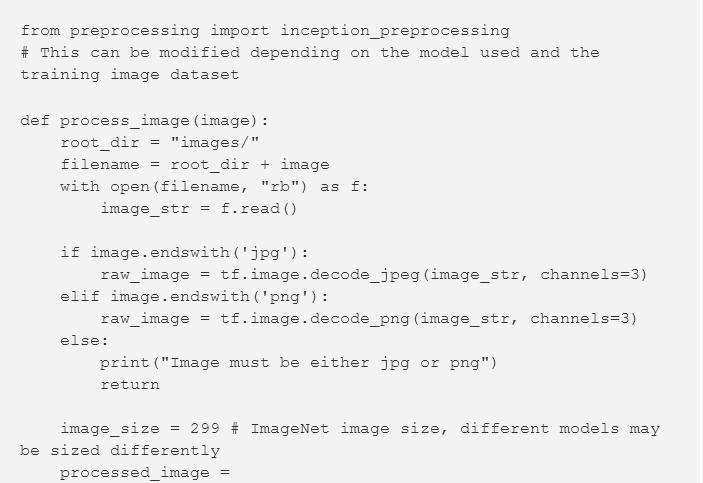
用于处理图像
既然现在我们已经下载了这些模型,我们需要一种方法来确保这些用于网络中的图像具有正确的配置。
Imagenet图像全部为299像素×299像素(高x宽)×3色通道(红-绿-蓝)。因此,我们通过网络发送的任何图像都必须使用相同的格式。Inception网络也期望将图像缩放在0和1之间,这意味着像素值需要除以255(颜色的最大强度值)。虽然这是相对简单的,但在我们正在工作的the slim library中,预处理目录中的
inception_preprocessing.py
脚本中已经含有一个内置的图片处理函数。此函数将图像作为像素值的一个三维数组,并返回正确格式化的数组以供Inception网络进行评估。它还具有许多其他功能用于训练,例如移动或改变图像,使得网络能够维持图像各个方面的不变性(例如方向),从而不影响图像中的目标。该技术也可以用于
增加一个小的数据集
,其中涵盖那些已经被移位,缩放或旋转的每个图像的副本。我们将通过is_training = False传入,从而使图像将被处理用于评估,且只能调整其大小。

我们应该将要进行分类的图像应放置在一个新的图像目录中,该文件夹位于slim文件夹(或更改上述代码中的root_dir)。现在,我们将坚持使用jpg和png图像,尽管其他格式也可以进行处理。为了生成正确的图像,我们创建一个TensorFlow会话来运行TensorFlow操作。我们返回的是原始图像以便我们可以对其进行相关绘制,以及那些格式为[batch_size,height,width,color_channels]的已处理图像。
显示示例图像
我们可以下载我们想要的任何图像,并将其放在images目录中。
但是,为了使网络能够有更正以至正确的机会,我们将需要ImageNet数据集中所包含的图像。
可以在这里找到包含1000个类的
完整列表
。(当网络用于is_training = False评估时,它将有1001个类,因为它添加了一个额外的“背景”类别。)选择几个图像并将其下载到images目录。当然,如果图像是闭合的,并在中心显示目标,那将再好不过了。我们可以先编写一个小函数,使用matplotlib.pyplot绘制图形,然后使用%matplotlib内置magic函数在Jupyter Notebook中显示绘制图。

野牛的原始形象
我们还可以检查原始图像和已处理图像的大小:

在面对类似于该图像的情况下,由于原始尺寸太小,预处理函数通过在现有像素值之间进行插值来增加额外的像素。而结果就是,这将导致一个不明显影响CNN性能的模糊图像。
还有一个有趣的图像:


帽子的原始形象
图像识别
这个项目的核心是预测图片的类别。既然现在我们已有几个图像(当然,你可以随意收集你想要的图像数量),其实,观察CNN对那些在训练过程中看不到的图像类别进行“猜想”是很有趣的。我们将会编写一个函数,用图像和要使用的CNN的版本(目前仅限于Inception架构,“V3”或“V4”)进行命名,绘制原始图像,并显示图形下方的前10个预测。

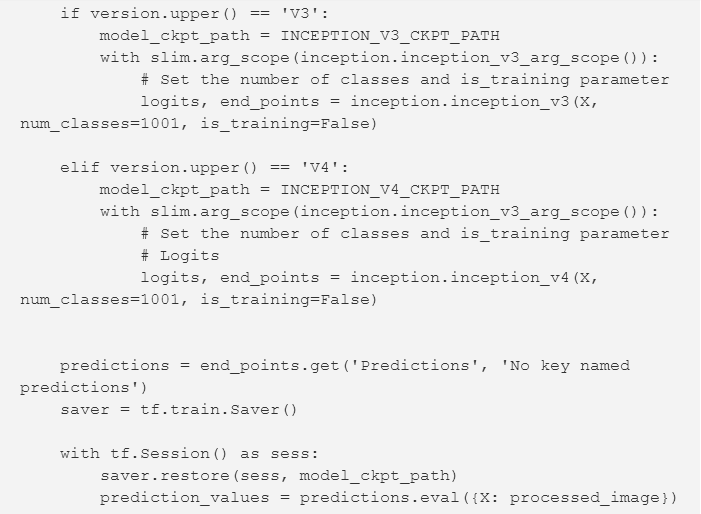

代码相对简单。我们课根据模型来应用正确的参数范围和函数。(请注意,我们需要将类的数量设置为1001,is_training = False。)在使用inception_v3函数(或inception_v4)构建TensorFlow计算图之后,我们需创建一个TensorFlow会话,以通过网络填充图像。我们使用一个保护程序恢复我们之前下载的模型权重。该图返回了来自网络的未分级输出的逻辑,以及通过softmax激活函数传递逻辑的结果以及概率。在我们得到预测之后,我们创建一个具有预测索引和相关概率的元组列表。然后,我们按概率对这些元组进行排序,并根据网络概率排名打印出前10名的类别名称。
预测结果
这里有几个典型的结果。


Inception_v3的预测结果非常好!我们来看看v4预测:


可以看到,两个模型是一致的。我会给模型一些更容易的图片。


有趣的是,CNN不仅要做出正确的预测,还要注意其他潜在的备选。这里的第二个选择至少是有意义的,但其他的一些似乎已经已经过于偏离(概率非常小,并且使用的是小数点后两位数)。




这些结果印象深刻。我认为,我所选择的所有图像都比较容易识别,并且突出显示那些有趣的对象,而这两个条件都不可能在现实世界中进行复制。
在现实中,时间不会停留,一个场景中可能会有成千上百个的不同对象需要识别
(且认为我们是连续进行此操作,没有中断)。尽管如此,却不得不承认,这个网络是一个很好的开端,即使是面对的是一个复杂的图像,我们也可以获得准确的结果:

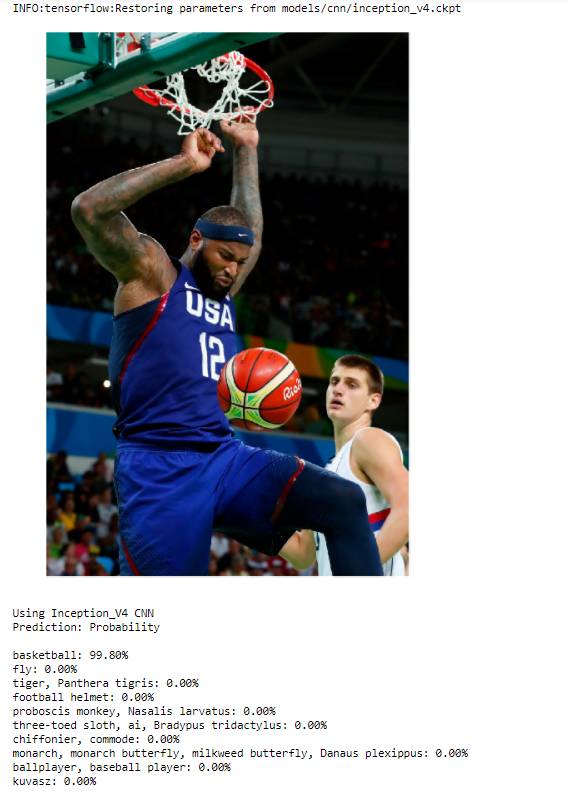
我们对该网络进行设计和训练,以便能够识别每个图像中的一个图像类别,这是它是非常适合的任务。
但是,如果我们在一张图片中引入更多的元素,那么预测就会开始崩溃。

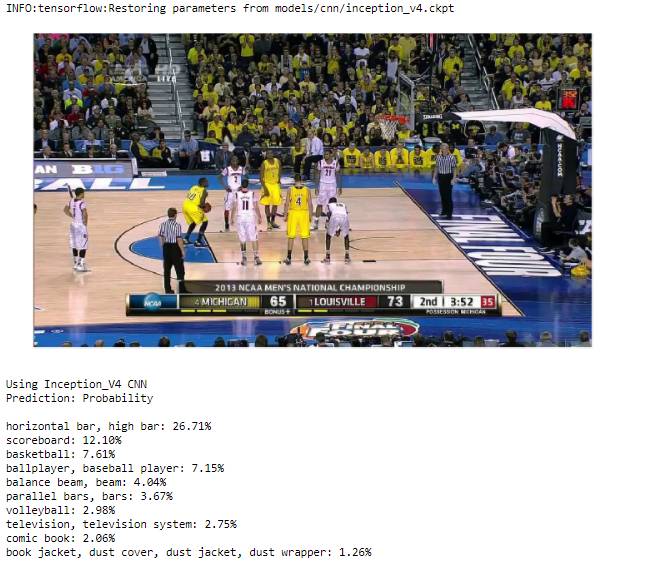
在组合中有一些很好的预测,
但总体而言,该模型已淹没于噪声之中。






