庆余年电视剧上映一段时间,火的不要不要,这两天赶紧爬取数据看一下它的表现。
《庆余年》是作家猫腻的小说。这部从2007年就开更的作品拥有固定的书迷群体,也在文学IP价值榜上有名。

期待已久的影视版的《庆余年》终于播出了,一直很担心它会走一遍《盗墓笔记》的老路。
在《庆余年》电视剧上线后,就第一时间去看了,真香。

《庆余年》在微博上一直霸占热搜榜,去微博看一下大家都在讨论啥:
于是爬取了微博
超
话页面,然后找到相关人员,分别去爬取相关人员的微博评论,看看大家都在讨论啥。
import argparse
parser = argparse.ArgumentParser(description="weibo comments spider")
parser.add_argument('-u', dest='username', help='weibo username', default='')
parser.add_argument('-p', dest='password', help='weibo password', default='')
parser.add_argument('-m', dest='max_page', help='max number of comment pages to crawl(number larger than 0 or all)', default=)
parser.add_argument('-l', dest='link', help='weibo comment link', default='')
parser.add_argument('-t', dest='url_type', help='weibo comment link type(pc or phone)', default='pc')
args = parser.parse_args()
wb = weibo()
username = args.username
password = args.password
try:
max_page = int(float(args.max_page))
except:
pass
url = args.link
url_type = args.url_type
if not username or not password or not
max_page or not url or not url_type:
raise ValueError('argument error')
wb.login(username, password)
wb.getComments(url, url_type, max_page)
相关函数已经封装好,后台回复“
微博
”下载直接使用。
如何利用Python生成词云图
爬取到微博评论后,老规矩,词云展示一下,不同主角的评论内容差别还是挺大的



从目前大家的评论来看,情绪比较正向,评价较高,相信《庆余年》会越来越火的。
看了一下几位主演的相关微博,都是几十万的评论和转发,尤其是肖战有百万级的转发,尝试爬了一下肖战的微博,执行了6个小时的结果,大家随意感受一下执行过程:
最终还是败给了各位
小飞侠,
之后有结果再同步给大家。

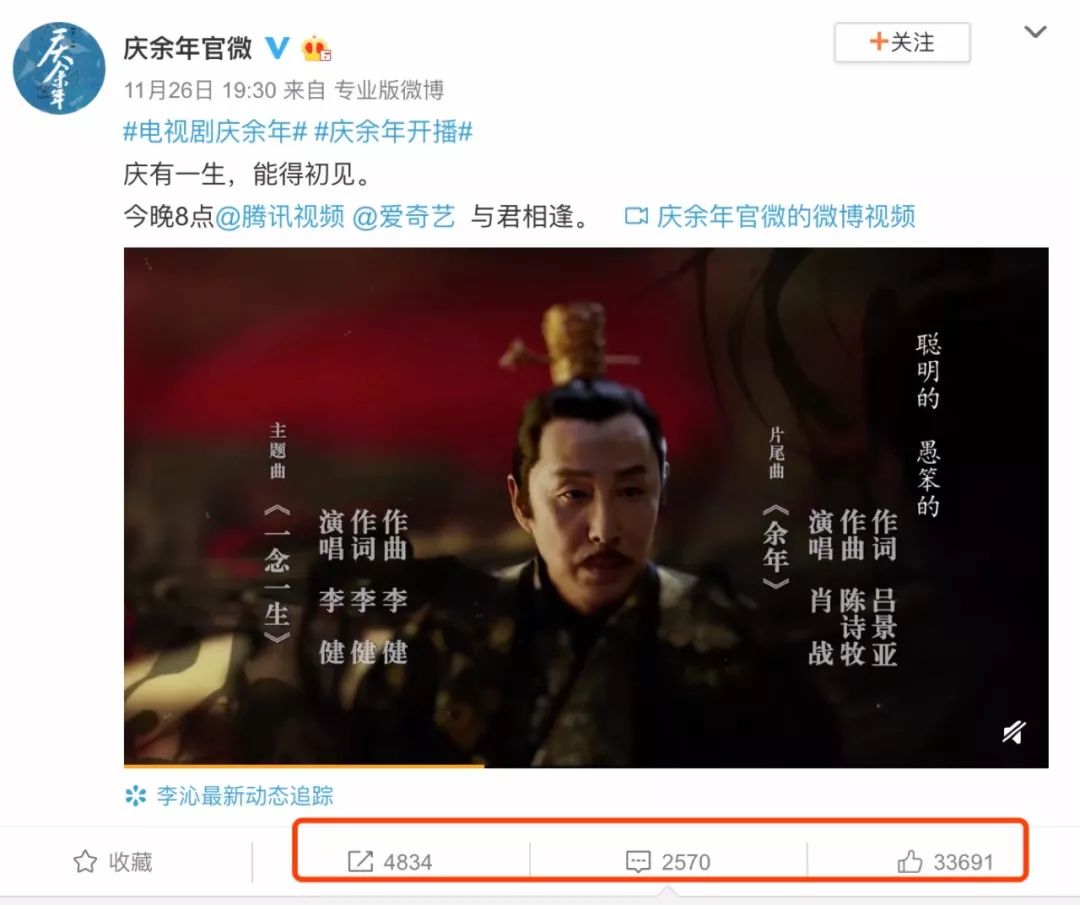
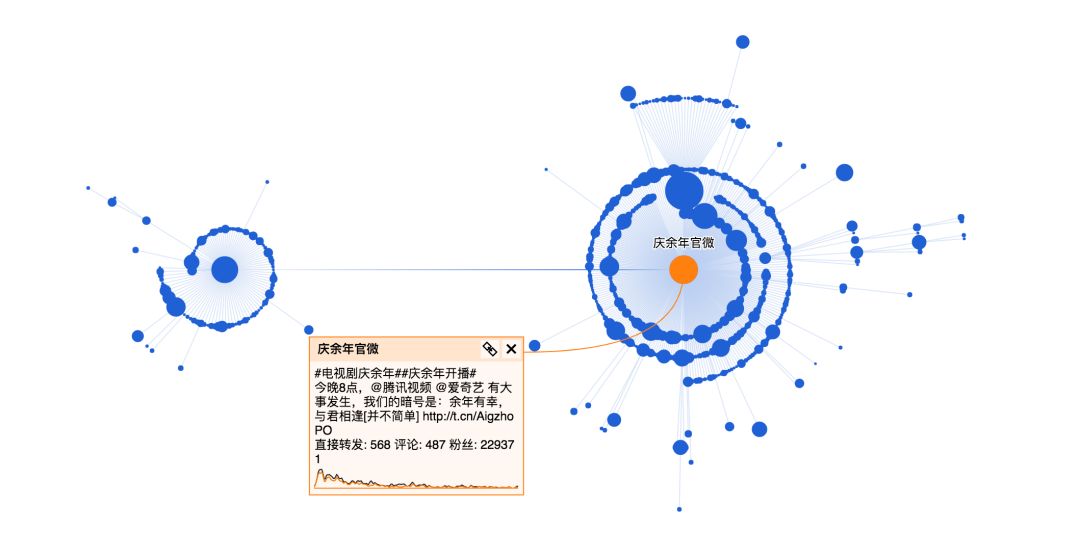
这条微博发布时间是26号,经过一段时间已经有比较好的传播,其中有几个关键节点进一步引爆话题。
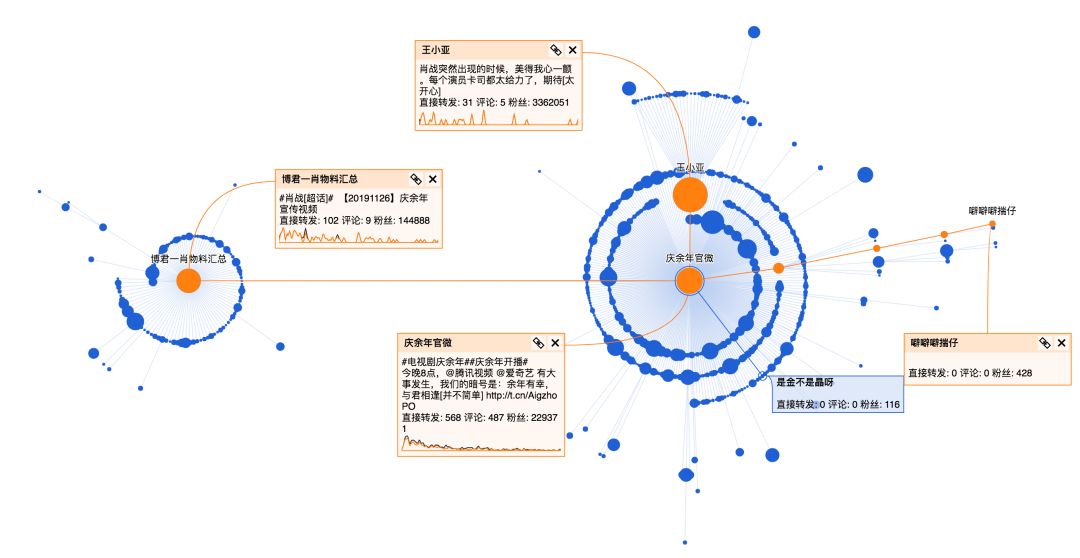
经过几个关键节点后,进一步获得传播,这几个关键节点分别是:
肖战的超话:
https://weibo.com/1081273845/Ii1ztr1BH
王小亚的微博:
https://weibo.com/6475144268/Ii1rDEN6q
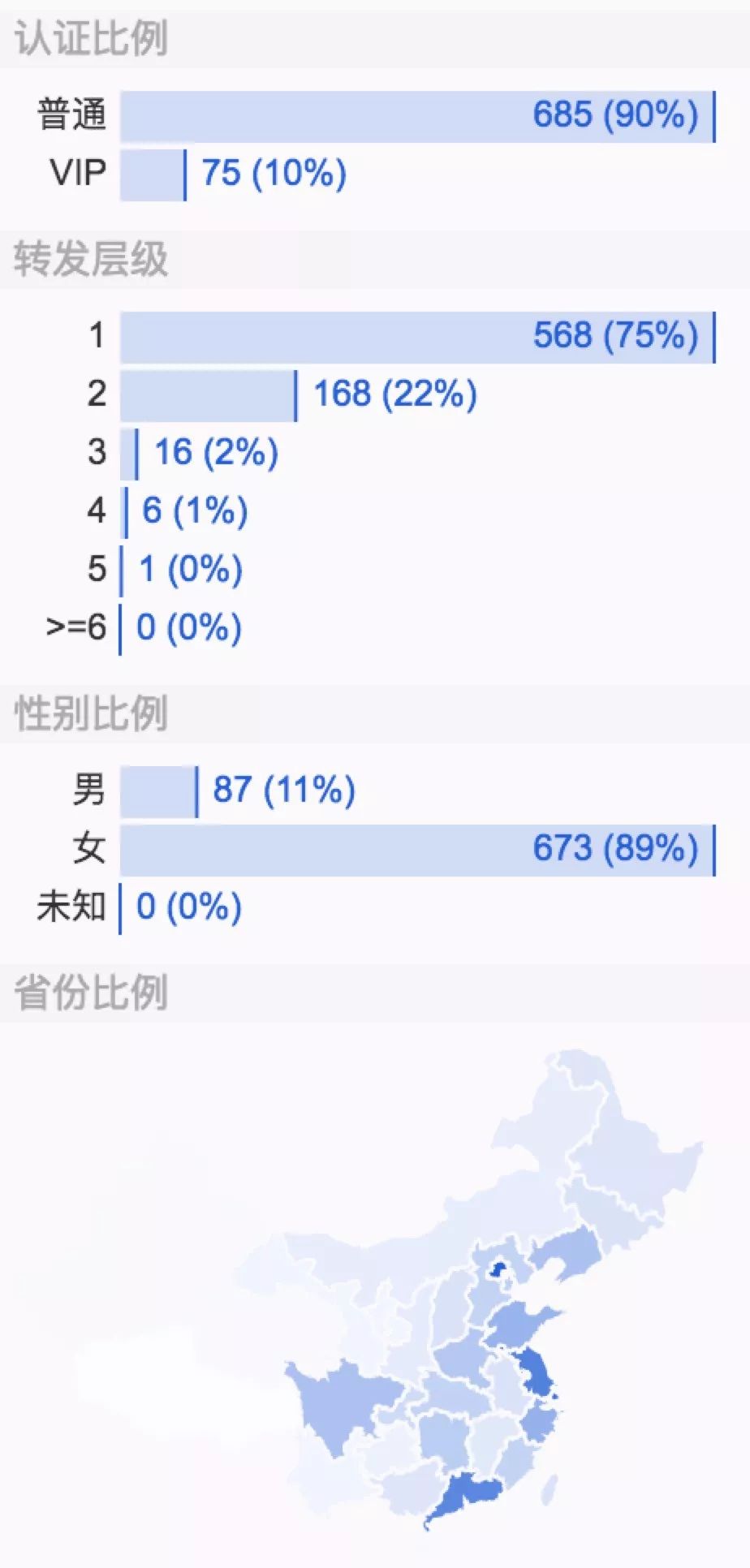
整体看下来,庆余年官微的这条微博90%都是普通用户的转发,这部剧转发层级达到5层,传播范围广,在微博上的讨论女性居多(占比89%),大部分集中在一二线城市。
如果只看微博,不分析原著,那就不是一个合格的书粉。


emmm.....确实挺丑的,大家可以去Gephi上调整。
首先我需要从原著里洗出人物名,尝试用jieba分词库来清洗:
import jieba
test= 'temp.txt'
text = open(test, 'r', 'utf-8')
seg_list = jieba.cut(text, cut_all=True, HMM=False)
print("Full Mode: " + "/ ".join(seg_list))
发现并不能很好的切分出所有人名,最简单的方法是直接准备好人物名称和他们的别名,这样就能准确定位到人物关系。

def synonymous_names(synonymous_dict_path):
with codecs.open(synonymous_dict_path, 'r', 'utf-8') as f:
lines = f.read().split('\n')
for l in lines:
synonymous_dict[l.split(' ')[0]] = l.split(' ')[1]
return synonymous_dict
接下来直接清理文本数据:
def clean_text(text):
new_text = []
text_comment = []
with open(text, encoding='gb18030') as f:
para = f.read().split('\r\n')
para = para[0].split('\u3000')
for










