按上方蓝字关注“硅星人”,带你看不一样的硅谷!

IQ 的 I ,并不是 AI 的 I
生活在一个AI“泛滥”的时代,我们几乎每天都能看到 AI 研究上的最新进展。
昨天,AI 打 DoTA 战胜人类了;今天,AI 能自己找路了;明天,AI 能假冒人类打电话了。
在担心 AI 会灭掉人类的人们眼中,AI 正像一只怪物一样野蛮生长,像一只侵略军一样从远方大跨步逼近。
然而实际上,你所看到的这些进展,只是不同的 AI 在特定方向的进步。虽然当前基于深度学习的 AI 热潮已经有五六年了,还是没有一个独立的 AI,像一个独立的人一样,能够优秀地执行多种任务。
人们在形容 AI 时,通常会用这样一种说法:这个 AI 的智商,跟三岁小孩差不多。
智商 (Intelligence quotient) 简称 IQ,是评价人类智商一个普遍接受的标准 。你有智商,我也有智商,就连三岁小孩也有智商。接下来问题来了:既然说 AI 跟三岁小孩差不多,那么它的智商到底有多少呢?
得给 AI 测测智商了。
自 AlphaGo 横空出世以来,AI 在解决一些复杂的、策略性的问题上,能力已经得到了证明。但如果想要更像“人”,AI 必须也拥有像人类一样的抽象理解能力。
而如果你小时候不幸被父母带去少年宫测过智商,应该还记得那些题吧?
比如有几个数列在一起,中间空了一位让你填的:

也有下面这种图形演进变换的:

科学不科学先不说,这些智商测试题的意图还是很明显的,主要就是为了检测小朋友在计算、逻辑推理还有抽象理解等方面的能力。
给 AI 测智商也一样。只不过现在的 AI 计算能力不用说了,推理能力也很强,所以只剩抽象理解能力了。Google 旗下的 AI 科研机构 DeepMind 认为,“基于神经网络的机器学习模型取得了惊人的成绩,但想要衡量其推理抽象概念的能力,却非常困难。”
为了搞清楚现在的 AI 在抽象理解能力上究竟实力如何,DeepMind 还真给 AI 设计了一套测试题:

(论文地址 http://t.cn/Rdd9eDZ 点文末的“阅读原文”也可以看到)
这套测试题,借鉴了人类的 IQ 测试里著名的瑞文推理测验:给定一组图片,找到符合其“演进”规律的图片。
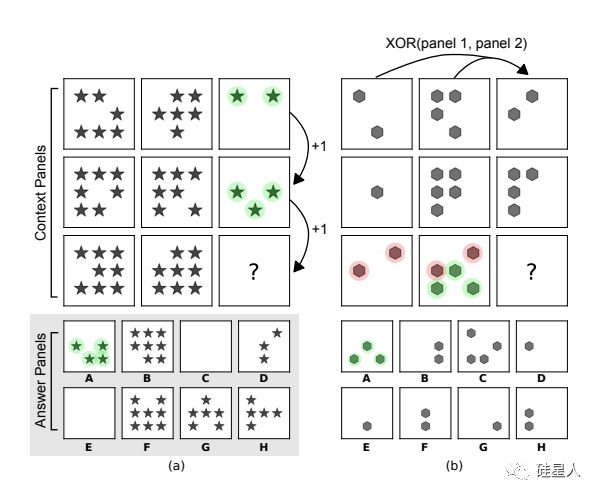
(图片来源:DeepMind 论文)
在这种测试中,题目里并不会告诉你要找到符合什么标准的图形,而是需要我们根据日常生活中学习或掌握到的一些基本原则,来理解和分析测试中出现的简单图案。
要找到正确的答案,往往要借鉴我们从生活中明白的“演进”规律。比如小树苗长成大树,比如从 0 到1、2、3、4、5 的加法,再比如加减乘除。
以上这些,就是我们生活中所提炼出的抽象的“演进”(progression)的意义,只要上过小学,甚至没经历过系统教育的人都能够理解。这就是人类的抽象理解能力。这也是为什么你的爸妈可能在你还不太记事、懂事的时候,就带你测过智商了。
“但是,我们现在还没有找到办法,能让 AI 也可以从 ‘日常经验’中学到类似的能力。” DeepMind 在论文中说。
“不过,我们依然可以很好地利用人类的这种视觉抽象逻辑测试,来设计一个实验。在这个测试中,我们并不是像人类测试那样,考察从日常生活到视觉推理问题的知识转移。而是研究AI在将知识从一组受控的视觉推理问题,转移到另一组问题的能力。”
听不懂没关系,我们翻译一下这段话:DeepMind 先给 AI 喂一组由三角形构成的图像的视觉推理题库,等训练的差不多了,再出一组由方块构成的视觉推理题,让 AI 去回答,看它是能随机应变举一反三,还是学会了三角,换成方块就不灵了。
对于担心 AI 取代人类的朋友来说,DeepMind 的一部分实验结果确实是个好消息:他们找来的一些 state of the art(当前最优秀)的 AI 模型,在这个IQ测试中的表现得并不咋样……
我们还是拿三角和方块来举例。正如预期的那样,当训练集和测试集所采用的抽象元素相同,也就是训练三角、测试三角时,多个 AI 模型都表现出超过75%的准确率。
然而,当测试集和训练集出现变化,甚至有时候只是把黑点换成较暗的浅色圆点,AI 的表现就会像无头苍蝇一样,失去了准星。

一些知名AI模型的表现 图片来源:DeepMind 论文
上面这些都是深度神经网络领域的当红炸子鸡,测起智商来却没那么灵光了。比如 ResNet 在其中一组测试中仅仅得到22.4%的低分。
ResNet (Deep Residual Network),即深度残差网络,它的提出曾被形容为CNN(卷积神经网络)的一个里程碑式事件,它在网络深度上比其他模型提升了n个量级,更重要的是它的残差学习方式,改良了模型的架构,因此一出现就秒杀众前辈。
而测试中表现最好的 WReN 模型,则是 DeepMind 在关系网络 (Relation Networks) 模型基础上改良的版本。它增加了对不同图像组合之间关系的分析,并可以对这类 IQ 测试的各种可能性结果进行评估。
(需要明确的是:对于这些神经网络和其作者,这个结果并不丢人——因为它们本来就不是设计用来像这样测智商的,而是解决某些特定问题的。)
不过,DeepMind 针对这个测试的逻辑,对一些模型进行改良,改良后的模型表现出明显的提升。
比如,在一些模型中,DeepMind 加入了元标记(meta-targets) 的辅助训练方法,让模型对数据集背后体现出的形状、属性(形状的数量、大小、颜色深浅等)以及关系(同时出现、递减、递增等等)进行预测,当这部分预测准确时,最终回答的准确率就明显出现提升,预测错误时,回答准确率明显下降。一些极端情况下,模型回答的准确率更是从预测错误时的32%提升至了87%。

(图片来源:DeepMind 论文)
DeepMind 表示,他们设计的这个实验,最终目的并不是为了让 AI 能够通过这种 IQ 测试。他们关注的是 AI 泛化能力的问题。
泛化是指模型很好地拟合以前未见过的新数据的能力,这是机器学习界的术语,你也可以粗暴的理解成一个 AI 模型能否在各类场景中“通吃”。AI 的泛化能力越强,离啥都能干的所谓“通用人工智能”就越近。
DeepMind 在博客最后这样说道:
研究表明,寻找关于泛化问题的普遍结论可能没有任何意义。我们测试的神经网络在某些泛化方案中表现优秀,但是其他方案下却很糟糕。
诸如所使用模型的架构、模型是否被训练从而能解释答案背后的逻辑等一系列因素,都会对泛化效果带来影响。而在大多数情况下,当需要处理过往经验从未涉及的、或完全陌生的情景时,这些 AI 的表现很糟糕。
至少现在看来,AI 还有很长的路要走啊。
(点击文末阅读原文可以查看 DeepMind 这篇论文)
在哪里,能将中美一线科技公司高管、顶级投资人、电影游戏跨界大师、AI 大牛以及区块链行内专家一网打尽?
必须是⤵️

没错,硅谷最精彩、
最有料、
最多人去的科技峰会 SYNC 又回来了!
今年,我们请来了各路中美科技和文化创新的前沿人士:
拳头游戏首席设计师/CMU教授
模拟城市、暗黑3首席设计师
等众多嘉宾。
具体演讲人资料,请访问票务网站了解:sync2018sv.eventbrite.com
或长按二维码购票(现在扫码有折扣哦!)

SYNC 2018 Decode Innovation
知名科技媒体 PingWest品玩和硅星人一同举办
主题:科技、文化、跨境、跨界
风格:干货、专业、有趣、亲切
时间:8 月 5 日
地点:Computer History Museum,
1401 N Shoreline, Mountain View, CA
抢票:sync2018sv.eventbrite.com










