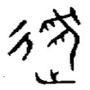标签 | 设计 DDD
说明:
本文是我即将在2017年领域驱动设计中国峰会演讲《Bounded Context的实践意义》的部分内容。在本次演讲中,我将彻底对限界上下文做一个全方位的解剖,包括解读限界上下文的定义、价值,了解限界上下文的三种边界,并提出如何识别限界上下文的方法。我们必须重视限界上下文,因为它可以是微服务设计的有力武器。提前发布出来,友情帮DDD在中国的这次顶级峰会“火上浇油”。
边界通过限界上下文来确定,这在领域驱动设计中具有非凡的意义。
对应于通用语言,限界上下文是语言的边界,对于领域模型,限界上下文是模型的边界,二者对应于问题空间(Problem Space)的界定。对于系统的架构,限界上下文还确定了应用边界和技术边界,进而帮助我们确定整个系统及各个限界上下文的解决方案。可以说,限界上下文是连接问题空间与解决方案空间的重要桥梁。
那么,限界上下文所界定的边界,究竟是逻辑边界,还是物理边界?这并没有定论,需得依据不同场景而做出不同的决策。
逻辑边界
根据业务对领域进行逻辑分解时,分与合是两个矛盾而又统一的概念。合是目标,分是降低复杂度的一种手段。分实则是为了更好的合。通过业务分解,每个分解出来的限界上下文规模就变得更小,因而更容易理解和把控。由于这种分解是从业务相关性来考虑的,使得领域可以更加细分,业务分析师或者领域专家就可以只要求掌握更加细分的专精领域。
从系统的代码模型(Code Model)看,所谓
逻辑边界
有两种表现形式。以Java为例,归纳如下:
将限定上下文的边界视为逻辑边界是最常见也是最简单的一种形式。一方面逻辑的分离可以保证系统代码的清晰结构,另一方面它也使得限界上下文之间的协作变得更加容易,更加高效。在物理上,限界上下文彼此之间的通信其实是无缝集成的,要重用的领域模型都可以直接访问,并对模型类进行实例化。如下是国际报税系统的逻辑边界(Java):
然而,正所谓
越容易重用,就越容易产生耦合
。编写代码时,我们需要谨守这条无形的逻辑边界,时刻注意不要逾界,并确定限界上下文各自对外公开的接口,避免对具体的实现产生依赖。
采用逻辑边界划分限界上下文的系统架构是单块(Monolithic)架构
,所有的限界上下文都部署在同一个进程中,因此不能针对某一个限界上下文进行水平伸缩。需要对限界上下文的实现进行替换或升级时,会影响到整个系统。即使我们守住了逻辑边界,这种耦合仍然存在,导致各个限界上下文的开发互相影响,团队之间的协调成本也随之而增加。
物理边界
逻辑边界的坏,正是物理边界的好;反过来,物理边界的坏,同样是逻辑边界的好。
当我们将限界上下文的边界定义为物理边界时,每个限界上下文就变成了一个个细粒度的微服务。
这里,我们需要针对Eric Evans提出的“限界上下文”概念做进一步澄清:
限界上下文究竟是仅仅针对领域模型的边界划分,还是对整个架构(包括基础设施层以及需要使用的外部资源)垂直方向的划分?
正如前面对Eric Evans观点的引用,他在《领域驱动设计》一书中明确地指出:“根据团队的组织、软件系统的各个部分的用法以及物理表现(代码和数据库模式等)来设置模型的边界。”显然,限界上下文不仅仅作用于领域层和应用层。
它是架构设计而非仅仅是领域设计的关键因素。
倘若我们将限界上下文的边界视为物理边界,则可以保证边界内的服务、基础设施乃至于存储资源、中间件等其他外部资源的完整性,最终形成自治的服务。限界上下文之间仅仅通过限定的方式以限定的通信协议和数据格式进行通信,除此之外,彼此没有任何共享,这种架构被称之为
零共享架构
。这种架构的表现形式为:每个限界上下文都有自己的代码库、数据存储以及开发团队,每个限界上下文选择的技术栈和语言平台也可以不同。当每个限界上下文都被物理隔离时,一个限界上下文的开发人员就不能调用另一个限界上下文的方法,或者将数据存储在共享结构中了,这可以避免因为共享带来的耦合。下图为危机分析系统的架构:
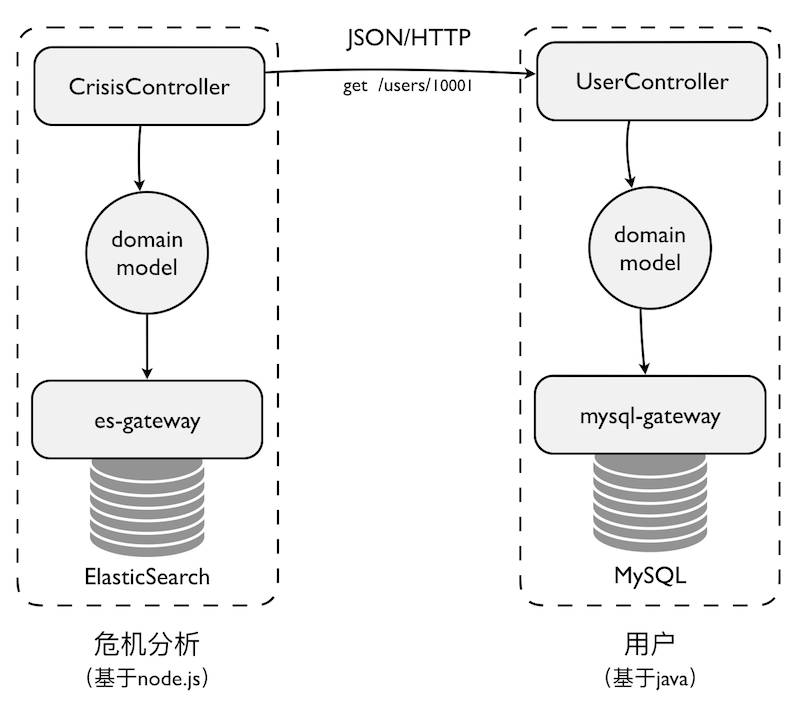
物理分隔开的限界上下文变得小而专,使得我们可以很好地安排遵循2PTs规则的小团队去治理它。然而,这种架构的复杂度也不可低估。限界上下文之间的通信是跨进程的,我们需要考虑通信的健壮性。数据库是完全分离的,当需要关联之间的数据时,需得跨限界上下文去访问,无法享受数据库自身提供的关联福利。由于每个限界上下文都是分布式的,如何保证数据的一致性也是一件棘手的问题。当整个系统都被分解成一个个可以独立部署的限界上下文时,运维与监控的复杂度也随之而剧增。
数据库共享
在逻辑边界和物理边界中间,还存在一种折中的手段。在考虑限界上下文划分时,分开考虑代码模型与数据库模型,就可能出现在代码上分离,而在数据库层面却存在数据共享的形式,即多个限界上下文共享同一个数据库。
因为没有分库,在数据库层面就可以更好地保证事务的ACID。这或许是该方案最有说服力的证据,但也可以视为是对“一致性”约束的妥协。
数据库共享的问题在于数据库的变化方向与业务的变化方向会不一致。这种不一致性体现在两个方面:
根据Netflix团队提出的微服务架构最佳实践,其中一个最重要特征就是“
每个微服务的数据单独存储
”。但是服务的分离并不绝对代表数据应该分离。数据库的样式(Schema)与领域模型未必存在一对一的映射关系。在对数据进行分库设计时,如果仅仅站在业务边界的角度去思考,可能会因为分库的粒度太小,导致不必要的跨库关联。因此,我们可以将“数据库共享”模式视为一种过渡方案,不要在一开始设计微服务的时候,就直接将数据彻底分开,而是采用演进式的设计。