来源:coderkian
链接:www.cnblogs.com/coderkian/p/3758068.html
递归函数具有很好的可读性和可维护性,但是大部分情况下程序效率不如非递归函数,所以在程序设计中一般喜欢先用递归解决问题,在保证方法正确的前提下再转换为非递归函数以提高效率。

函数调用时,需要在栈中分配新的帧,将返回地址,调用参数和局部变量入栈。所以递归调用越深,占用的栈空间越多。如果层数过深,肯定会导致栈溢出,这也是消除递归的必要性之一。递归函数又可以分为尾递归和非尾递归函数,前者往往具有很好的优化效率,下面我们分别加以讨论。
尾递归函数
尾递归函数是指函数的最后一个动作是调用函数本身的递归函数,是递归的一种特殊情形。尾递归具有两个主要的特征:
调用自身函数(Self-called);
计算仅占用常量栈空间(Stack Space)。
为什么尾递归可以做到常量栈空间,我们用著名的fibonacci数列作为例子来说明。
fibonacci数列实现方法一般是这样的,
int FibonacciRecur(int n) {
if (0==n) return 0;
if (1==n) return 1;
return FibonacciRecur(n-1)+FibonacciRecur(n-2);
}
不过需要注意的是这种实现方法并不是尾递归,因为尾递归的最后一个动作必须是调用自身,这里最后的动作是加法运算,所以我们要修改一下,
int FibonacciTailRecur(int n, int acc1, int acc2) {
if (0==n) return acc1;
return FibonacciTailRecur(n-1, acc2, acc1+acc2);
}
好了,现在符合尾递归的定义了,用gcc分别加-O和-O2选项编译,下面是部分汇编代码,
-O2汇编代码
FibonacciTailRecur:
.LFB12:
testl %edi, %edi
movl %esi, %eax
movl %edx, %esi
je .L4
.p2align 4,,7
.L7:
leal (%rax,%rsi), %edx
decl %edi
movl %esi, %eax
testl %edi, %edi
movl %edx, %esi
jne .L7 // use jne
.L4:
rep ; ret
-O汇编代码
FibonacciTailRecur:
.LFB2:
pushq %rbp
.LCFI0:
movq %rsp, %rbp
.LCFI1:
subq $16, %rsp
.LCFI2:
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl %edx, -12(%rbp)
cmpl $0, -4(%rbp)
jne .L2
movl -8(%rbp), %eax
movl %eax, -16(%rbp)
jmp .L1
.L2:
movl -12(%rbp), %eax
movl -8(%rbp), %edx
addl %eax, %edx
movl -12(%rbp), %esi
movl -4(%rbp), %edi
decl %edi
call FibonacciTailRecur //use call
movl %eax, -16(%rbp)
.L1:
movl -16(%rbp), %eax
leave
ret
可以看到-O2时用了jne命令,每次调用下层递归并没有申请新的栈空间,而是更新当前帧的局部数据,重复使用当前帧,所以不管有多少层尾递归调用都不会栈溢出,这也是使用尾递归的意义所在。
而-O使用的是call命令,这会申请新的栈空间,也就是说gcc默认状态下并没有优化尾递归,这么做的一个主要原因是有时候我们需要保留帧信息用于调试,而加-O2优化后,不管多少层尾递归调用,使用的都是第一层帧,是得不到当前帧的信息的,大家可以用gdb调试下就知道了。
除了尾递归,Fibonacci数列很容易推导出循环实现方式,
int fibonacciNonRecur(int n) {
int acc1 = 0, acc2 = 1;
for(int i=0; in; i++){
int t = acc1;
acc1 = acc2;
acc2 += t;
}
return acc1;
}
在我的机器上,全部加-O2选项优化编译,运行时间如下(单位微秒)
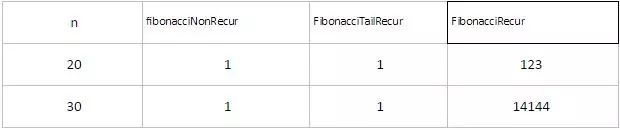
将fibonacci函数的迭代,尾递归和递归函数性能比较,可以发现迭代和尾递归时间几乎一致,n的大小对迭代和尾递归运行时间影响很小,因为只是多执行O(n)条机器指令而已。但是n对递归函数影响非常大,这是由于递归需要频繁分配回收栈空间所致。正是由于尾递归的高效率,在一些语言如lua中就明确建议使用尾递归(参照《lua程序设计第二版》第6章)。
非尾递归函数
编译器无法自动优化一般的递归函数,不过通过模拟递归函数的过程,我们可以借助于栈将任何递归函数转换为迭代函数。直观点,递归的过程其实是编译器帮我们处理了压栈和出栈的操作,转换为迭代函数就需要手动地处理压栈和出栈。
下面我们以经典的快速排序为例子。
int partition(int *array, int low, int high) {
int val = array[low];
while(low high) {
while(lowhigh && array[high]>=val) --high;
swap(&array[low], &array[high]);
while(lowhigh && array[low]val) ++low;
swap(&array[low], &array[high]);
}
return low;
}
void Quicksort(int *array, int b, int e) {
if (b >= e) return;
int p = partition(array, b, e);
Quicksort(array, b, p-1);
Quicksort(array, p+1, e);
}
其实不难看出快速排序的递归算法就是一个二叉树的先序遍历过程,先处理当前根节点,然后依次处理左子树和右子树。将快速排序递归算法转换为非递归相当于将二叉树先序遍历递归算法转为非递归算法。
二叉树先序遍历递归算法伪码
void PreorderRecursive(Bitree root){
if (root) {
visit(root);
PreorderRecursive(root->lchild);
PreorderRecursive(root->rchild);
}
}
二叉树先序遍历非递归伪码
void PreorderNonRecursive(Bitree root){
stack stk;
stk.push(root);
while(!stk.empty()){
p = stk.top();
visit(p);
stk.pop();
if(p.rchild) stk.push(stk.rchild);
if(p.lchild) stk.push(stk.lchild);
}
}
每次处理完当前节点后将右子树和左子树分别入栈,类似地,我们也很容易得到快速排序的非递归算法实现。partition将数组分为左右两部分,相当与处理当前节点,接下来要做的就是将左右子树入栈,那么左右子树需要保存什么信息呢?这个是处理非递归函数的关键,因为被调用函数信息需要压入栈中。快速排序只需要保存子数组的边界即可。
void QuicksortNonRecur(int *array, int b, int e) {
if (b >= e) return;
std::stackstd::pairint, int> > stk;
stk.push(std::make_pair(b, e));
while(!stk.empty()) {
std::pairint, int> pair = stk.top();
stk.pop();
if(pair.first >= pair.second) continue;
int p = partition(array, pair.first, pair.second);
if(p pair.second) stk.push(std::make_pair(p+1, e));
if(p > pair.first) stk.push(std::make_pair(b, p-1));
}
}
总结
虽然将递归函数转换为迭代函数可以提高程序效率,但是转换后的迭代函数往往可读性差,难以理解,不易维护。所以只有在特殊情况下,比如对栈空间有严格要求的嵌入式系统,才需要转换递归函数。大部分情况下,递归并不会成为系统的性能瓶颈,一个代码简单易读的递归函数常常比迭代函数更易维护。
Reference:
https://secweb.cs.odu.edu/~zeil/cs361/web/website/Lectures/recursionConversion/page/recursionConversion.html
http://en.wikipedia.org/wiki/Tail_Recursion
http://c2.com/cgi/wiki?TailRecursion
http://c2.com/cgi/wiki?RecursionVsLoop











