
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
这是我以前的博客文章的更新版本, 介绍了一些优化 Python 代码的推荐做法。
遵循最佳做法的代码库在当今世界受到广泛欢迎,如果你的项目是开放源代码,这是一个非常吸引人的方式。而作为一个开发人员,您要编写高效优化的代码,即:
代码占用了尽可能少的内存, 执行速度更快, 外观整洁, 文件正确, 遵循标准样式的准则, 对于新手开发人员来说很容易理解。
练习1:尽量不要用光内存
一个简单的 Python 程序可能不会在内存中造成很多问题, 但是在高内存消耗项目中这变得至关重要。因此,在进行大型项目开发时, 最好从一开始就牢记内存利用率。与 c/c++ 不同, Python 的解释器执行内存管理, 用户无法控制它,python 中的内存管理涉及一个包含所有 python 对象和数据结构的专有堆。
Python 内存管理器在内部确保了这个专有堆的管理。创建对象时, Python 虚拟机将分配所需的内存, 并决定将其放置在内存布局中的位置。但是, 更深入地了解事情的工作方式和不同的方法可以帮助您最小化程序的内存使用。
1、使用生成器计算大型结果集:
生成器可以实现惰性计算,您可以通过遍历使用它们:将其传递给函数或其他迭代结构,无论是明确或隐式地使用“for”循环。当生成器返回多个项目时,例如他们返回一个列表,项目被一个接一个地返回,而不是一次性返回。您可以在这里阅读更多关于Python生成器的内容:
https://jeffknupp.com/blog/2013/04/07/improve-your-python-yield-and-generators-explained/
2、对于大数据的处理, 您可以使用像 Numpy 这样的库, 它能够很好地进行内存管理。
3、使用格式代替 + 来生成字符串,在 Python 中, str 是不可变的, 因此必须将左右字符串复制到每对串联的新字符串中。如果您将四个长度为 10的字符串串联在一起, 您将复制 (10 + 10) + ((10 + 10) + 10) + (((10 + 10) + 10) + 10) = 90 个字符, 而不是仅仅40个字符。随着字符串数量和大小的增加, 事情变得更复杂。Java 通过将串联的字符串转换为 StringBuilder 来优化这种情况, 但 CPython 不这样做。因此, 建议使用. 格式化语法%,如果你不能在这二者之间选择, 可以查看 StackOverflow 这个有趣的讨论。
4、当定义 Python 类时使用slots属性。您可以告诉 Python 不要使用动态字典, 并且只为一组固定的属性分配空间, 从而消除了对每个对象使用一个字典的开销, 方法是将该类的 __slots__ 设置为一个固定的属性名列表。可以在这里阅读更多关于slots的内容:
https://stackoverflow.com/questions/472000/usage-of-slots
5、您可以通过使用内置模块 (如resource和 objgraph) 来跟踪对象级别的内存使用情况。
6、管理 Python 中的内存泄漏可能是一项艰巨的任务, 但幸运的是有像 heapy 这样的工具来调试内存泄漏。Heapy 可与 objgraph 一起使用, 以随时观察不同对象的分配增长。Heapy 可以显示哪些对象拥有最多的内存。Objgraph 可以帮助您找到后面的引用, 以便确切理解为什么不能释放它们。您可以在这里阅读有关诊断 Python 中内存泄漏的更多内容:
http://chase-seibert.github.io/blog/2013/08/03/diagnosing-memory-leaks-python.html
您可以在这里详细阅读 Theano 的开发人员对 Python 内存管理的信息:
http://deeplearning.net/software/theano/tutorial/python-memory-management.html
练习2:pyhton2还是python3?
当开始一个新的 python 项目, 或是学习 python时, 你可能会发现自己在选择 Python2 或 Python3 之间的两难境地。这是一个广泛讨论的话题, 在互联网上有许多评论。一方面, Python3 有一些伟大的新功能;另一方面, 您可能希望使用仅支持 Python2 的包, 而 Python3 不是向后兼容的。这意味着在 Python3上运行的代码在 Python2上会引发错误。
但是, 可以写出在 Python2 和 Python3 中都能运行的代码,最常见的方法是使用像 _future、builtins 和six这样的包来维护一个单一、干净的和 Python3. x 兼容的代码库, 它支持 Python2 和 Python3, 且开销最小。
python-future是 Python2 和 Python3 之间缺少的兼容层,它提供的future和past包能够弥合 Python3 和 Python2之间的差异。它还附带了 futurize 和pasteurize, 自定义2到3的脚本, 帮助您轻松地转换 Py2 或 Py3 代码, 以支持 Python2 和 Python3 在一个单一的干净的 Py3-style 模块。
您可以查看由Ed Schofield编写的 Python 2-3 兼容代码表。如果你是通过看视频来学习的, 那么他在 PyCon AU 2014的谈话 "编写2/3 兼容代码" 会非常有帮助。
练习3:写漂亮的代码, 因为-"第一印象就是最后的印象。
共享代码是一项值得付出的努力。无论目的如何, 如果人们发现您的代码难以使用或理解, 您的努力可能不会产生预期的结果。几乎每个组织都遵循一定的风格准则, 开发人员必须遵循这些指导原则, 以确保代码一致性、易于调试和易于协作。python 箴言就像一个迷你的风格和设计指南。Python 的流行风格准则包括:
1、PEP-8风格指南
2、python习语和效率
3、Google Python 风格指南
这些指南讨论了如何使用: 空白、逗号和大括号、对象命名准则等,虽然它们在某些情况下可能会发生冲突, 但它们都具有相同的目标,即"让代码更干净、可读和遵循一样的调试标准"。坚持一个指南,,或者跟随你自己的风格, 但不要试图去追寻与广泛接受的标准截然不同的东西。
使用静态代码分析工具
有许多可用的开源工具来使你的代码符合标准样式准则。Pylint 是一个 Python 工具, 它检查模块的编码标准。Pylint 可以快速简便地查看您的代码是否已捕获了 PEP-8 的精髓, 因此对一些用户来说它是非常 "友好" 的。它还为您提供了具有洞察力的指标和统计数据的报告, 可以帮助您判断代码质量。您也可以通过创建您自己的. pylintrc 文件来对其进行自定义。Pylint 不是唯一的选择,还有其他的工具如 PyChecker和PyFlakes,也有一些包如 pep8 和 flakes8。我的建议是使用 coala, 一个统一的静态代码分析框架, 目的是通过一个单一的框架提供语言不可知的代码分析。Coala 支持我前面提到的所有小工具, 并且是高度可定制的。
编写正确的文档
这方面对您的代码可用性是非常重要的,因此建议您尽可能详细地为您的代码编写文档, 以便其他开发人员能更容易的理解您的代码。
一个函数的典型内联文档应包括以下几点:
函数功能总结
1、交互式示例 (如果适用)。这些可以给新开发人员参考, 以便快速观察您的功能的使用情况和预期输出。以及您可以使用 doctest 模块断言这些示例的正确性 (作为测试运行)。有关示例, 请参见 doctest 文档。
2、参数文档 (通常是描述参数及其在函数中的作用的一部分)
3、返回类型文档 (除非您的函数没有返回任何内容!)
Sphinx是一个用于生成和管理项目文档的广泛使用的工具,它提供了许多方便的功能, 可以减少您编写标准文档的工作。此外, 您可以免费阅读文档, 这是为项目提供文档的最常见方式。Hitchiker 关于 Python 文档的指南包含一些有趣的信息, 这在写文档时可能对您有用。
练习4:加快代码运行速度
多进程,而不是多线程
在改进多任务代码的执行时间时, 您可能希望利用 CPU 中的多个内核同时执行多个任务。它可能看起来很直观地产生了几个线程, 让它们同时执行, 但是, 由于 Python 中的全局解释器锁, 你所做的一切就是让你的线程在同一内核上依次执行。要在 python 中实现实际的并行化, 您可能需要使用 python 多进程模块。另一个解决方案可能是将任务外包给:
1、操作系统 (通过多进程)
2、一些调用您的 Python 代码的外部应用程序 (例如, Spark或 Hadoop)
3、python 代码调用的代码 (例如, 您可以让 python 代码调用一个多线程的 C 函数)。
除了多进程, 还有其他的方法来提高代码性能,其中一些包括:
1、使用最新版本的 Python: 这是最直接的方式, 因为新的更新通常包括对现有功能的性能的增强。
2、尽可能使用内置函数: 这也与原则相一致,内置函数由世界上一些最好的 Python 开发者精心设计和审查, 所以它们通常是最好的方法。
3、考虑使用 Ctypes: Ctypes 提供了一个接口, 可以从 Python 代码中调用 C 共享函数。C 是一种接近机器级别的语言, 与 Python 中的类似实现相比, 它使您的代码执行得更快。
4、使用 Cython: Cython 是一个超集 Python 语言, 它允许用户调用 C 函数并具有静态类型声明, 这最终会导致一个更简单的最终代码, 它可能会执行得更快。
5、使用 PyPy: PyPy 是另一个具有 JIT (实时) 编译器的 Python 实现, 它可以使代码执行得更快。虽然我从来没有尝试 PyPy, 它也声称减少你的程序的内存消耗。像 Quora 这样的公司实际上在生产中使用 PyPy。
6、设计和数据结构: 这适用于每种语言。确保您使用的是正确的数据结构, 在正确的位置声明变量, 明智地使用标识符范围, 并在任何有意义的地方缓存结果。
我可以给出一个语言的具体例子, Python 通常在访问全局变量和解析函数地址时比较慢, 因此将它们分配给范围中的局部变量并访问它们会更快。
练习5:分析你的代码
分析代码的覆盖率、质量和性能通常很有帮助。Python 附带 cProfile 模块来帮助评估性能。它不仅给出了总的运行时间, 也给出每个函数独立运行的时间。然后它会告诉您每个函数被调用了多少次, 这可以确定在哪里进行优化更有效果。以下是 cProfile 的示例分析:
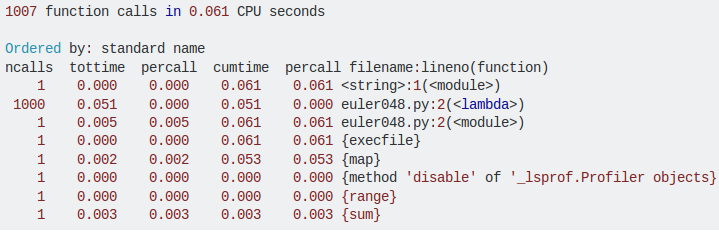
1、memory_profiler 是一个 python 模块, 用于监视进程的内存消耗, 以及对 python 程序的内存消耗进行逐行分析。
2、objgraph 允许您显示占据我们的 Python 程序内存的前 N 个对象、在一段时间内删除或添加的对象, 以及脚本中对给定对象的所有引用。
3、resource 提供了测量和控制程序使用的系统资源的基本机制,这个模块的两个主要用途包括限制资源的分配和获取有关资源当前使用情况的信息。
练习6:测试和集成
测试:
编写单元测试是一个很好的做法,如果您认为编写测试不值得努力, 请看一下这个 StackOverflow 讨论。最好在编码之前或期间编写测试,Python 提供单元模块来为您的函数和类编写单元测试,以下是一些框架:
1、nose-可以运行单元测试和并且有一些简洁的样板。
2、pytest-也可运行单元测试,有简洁的样板, 更好的报告, 和许多其他额外的功能。为了得到一个很好的比较, 可以在这里阅读更详细的内容:
http://pythontesting.net/start-here
不要忘记 doctest 模块, 它使用内嵌文档中演示的交互式示例测试源代码。
测量覆盖率:
Coverage是用来测量 Python 程序代码覆盖率的工具,它监视您的程序, 注意代码的哪些部分已被执行, 然后分析源代码以确定可能已执行但未完成的代码。覆盖率测量通常用来衡量测试的有效性,它可以显示你的代码的哪些部分是由测试来行使的, 哪些不是。通常最好有100% 分支覆盖, 这意味着您的测试应该能够执行和验证项目的每个分支的输出。
持续集成:
从一开始就为您的项目提供 CI 系统对您的项目长远发展来看是非常有用的,您可以使用 CI 服务轻松地测试代码库的各个方面,CI 中的一些典型检查包括:
1、在真实的世界环境中运行测试。有些情况下, 测试通过某些体系结构而失败。CI 服务可以让您在不同的系统体系结构上运行测试。
2、在代码库中强制执行覆盖率限制。
3、生成代码并将其部署到生产中 (您可以跨不同的平台完成此工作)
目前有几种可用的 CI 服务,其中一些最受欢迎的是Travis, Circle( OSX 和 Linux) 和 Appveyor (Windows),比较新的如Semaphore CI 也比较可靠。Gitlab (另一个 Git 存储库管理平台 (如 Github) 也支持 CI, 不过您需要像使用其他服务一样显式配置它。
更新:
这篇文章完全是基于我个人的经历,可能有很多事情遗漏了 (或者我不知道)。如果你有什么有趣的东西要分享, 请在评论中告诉我。
英文原文:https://www.codementor.io/satwikkansal/python-practices-for-efficient-code-performance-memory-and-usability-aze6oiq65
译者:Mr Chen





