我的运营策略是否有效?活动规则是否合理?这些问题抛给数据分析师,让他们从数据库中去扒信息回答你,其实是值得画问号的。最合理的方式就是做测试,或者说『对比实验』。通过测试中落下来的数据,才能形成合理的判断。
撰写本文的目的在于,从最近我团队所尝试的若干个运营测试中,抽象出一套更普适的方法论,帮助大家更『聪明的』做运营。
-
运营测试的步骤
我将运营测试的执行步骤概括为下图。我将有选择地对图中的各个步骤进行讲解。
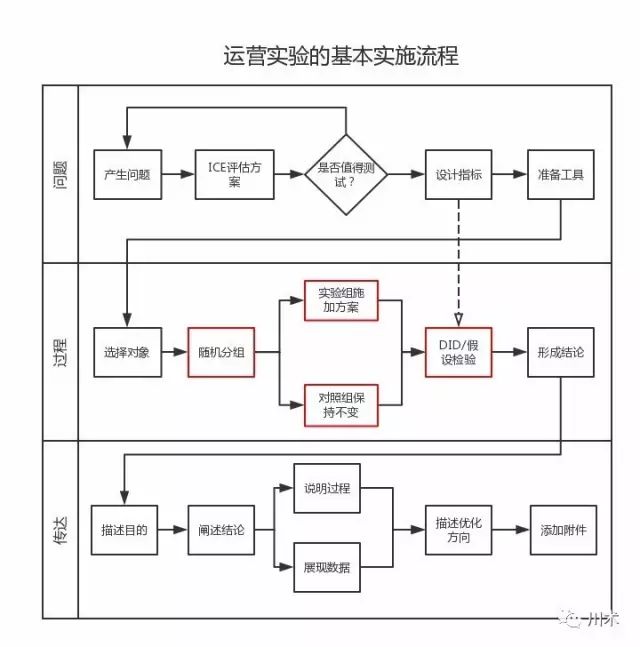
-
运营测试步骤详解
我将运营测试过程分为『问题』、『过程』、『传达』三个步骤。我们测试来源于业务问题的提取,测试过程贯穿着统计学的思想和方法,测试结果需要有效地传达给别人;只有这三个环节都完成,才能称为一个完整的运营测试。
-
产生问题
毫无疑问,问题一定来源于业务。我们
测试的目的就是找到解决业务问题的有效方案
。因此在产生问题这个环节,我们需要去调研各种各样的业务困难,然后针对不同的困难先想出大致可执行的方案。所谓的『产生问题』中的『问题』,其实是『这个方案有效吗?』这样的『是/否』问题。
我个人是倾向于将业务问题都不断地拆解,最终转化为『是/否』问题。这样的二元问题,可以比较容易量化。
-
利用ICE方法评估方案
ICE方法告诉我们,评估方案的可测试性,或者说测试的优先顺序,需要从
Impact(影响面的大小)、confidence(提出者对执行效果的信心)、easy(执行的难易度)三个角度来评估。
每一项都进行0-10分整数打分,三项得分求和后,得分最高的方案先进行测试。影响面即我们的测试方案能多大面积地影响我们的用户。影响面越大,分数越高。提出者对于测试成功的信心越足,则confidence这一项得分越高。对于执行的难易度,我们需要从是否需要产研参与?是否需要外部条件?需要多少金钱花费?需要多少时间?等角度考虑,执行难度越低,得分越高。
ICE方法为我们提供了一种思路。不过目前我所经历的测试并没有参考这个方法进行打分评估。以后需要往这个方向进行优化。
-
设计指标
指标是运营目的的量化。通俗得说,我们的方案实施后,解决了某个问题,那么就要从我们设计的指标上能反映出来。重要的是,
指标要对问题的改善敏感(信度和效度都要好)
。因此我们不能机械地盯着几项KPI指标。针对测试,需要找到更敏感更细节的指标。当然,若KPI指标能够胜任,再好不过了。
-
准备工具
明确的计划+自动化的运营工具+人工的操作方法+人员配备+资金预算+合适的时间+风险控制=准备工具。
-
选择对象
首先,实验对象一定是我们能操纵的事物。可能是我们的客户,也可能是某种资源。目前,我们给力的产研团队已经提供了灵活的segment工具,因此我们可以针对用户进行圈群组的方式,来选择实验对象。
-
随机分组
这点在实验过程中万分重要,
若没有随机分组的保证,后续所有的步骤和结论都将不可靠
。如何实施呢?我们圈选了我们的实验对象后,要将他们随机地分到实验组和对照组。在大家熟悉的Excel中,可以使用RAND()函数给每个用户生成一个随机数,然后按这个随机数排序,排序后取出前一半人作为实验组,后一般人作为对照组。
我们实验的目的是量化某个运营动作带来的效果。通过随机分组,给实验组施加这个运营动作,对照组不施予任何动作;然后对比实验组与对照组在实验指标上的变化,进而形成判断。这样的横向对比,效果是好于时间维度的纵向对比的。前提是实验组与对照组在除了『是否施予运营动作』之外的其他条件上都是相同的。而随机抽样就是对这种一致性的保证。
-
DID方法
我这里用一个图来说清楚DID,即双重差分测量法。

运营实验必然会在时间上有一个跨度。所以有人就会挑战:在时间变化后,实验组和对照组的数据可比性如何保证呢?答案就是应用DID。通过如上图的一个双重差分过程,我们就可以将两个组在时间维度上的指标变化剔除掉。
上图中的表格,大家去填满了,即完成了DID方法的过程。我们需要在两个时间段(测试前和测试实施后),计算两个群体(实验组和对照组)的一个指标(用户购买率),这样就先有了表哥中左上部分的4个数字。由这4个数字,我们能算出4个差值,最后,竖排两个差值相减和横排两个差值相减,结果一样,都是我们右下角的DID值。这个就是双重差分法的实施过程,右下角的这个『0.25%』,就是我们对实验效果的量化值。
需要补充一点,观察实验组合对照组在测试实施前的数值差距,我们可以判断随机分组是不是有效。
若两者差距很大,说明我们分组的随机性很值得怀疑,需要重新分组。
合理的随机性分组应该使得这两个数字差距不太大。但这种做法在统计学上是不严谨的,这里面水有点深,暂时不展开讨论。
-
假设检验
实验中的假设检验方法引申为方差分析方法。这部分我觉得暂时不掌握没关系,因为方差分析的适用条件比较苛刻,对统计学理论的要求也比较高。大家把DID用好之后,我会另外撰文介绍。
-
形成结论
这部分主要从DID数值中来。主观的说,DID数值若能占到测试实施前数值的5%以上,我们有充足的理由去判断实验方案是有效。










