全球机器智能峰会(GMIS 2017),是全球人工智能产业信息服务平台机器之心举办的首届大会,邀请了来自美国、欧洲、加拿大及国内的众多顶级专家参会演讲。本次大会共计 47 位嘉宾、5 个 Session、32 场演讲、4 场圆桌论坛、1 场人机大战,兼顾学界与产业、科技巨头与创业公司,以专业化、全球化的视角为人工智能从业者和爱好者奉上一场机器智能盛宴。
5 月 27 日,机器之心主办的为期两天的全球机器智能峰会(GMIS 2017)在北京 898 创新空间顺利开幕。中国科学院自动化研究所复杂系统管理与控制国家重点实验室主任王飞跃为本次大会做了开幕式致辞,他表示:「未来,人工智能将帮助人类战胜各种困难」。大会第一天重要嘉宾「LSTM 之父」Jürgen Schmidhuber、Citadel 首席人工智能官邓力、腾讯 AI Lab 副主任俞栋、英特尔 AIPG 数据科学部主任 Yinyin Liu、GE Transportation Digital Solutions CTO Wesly Mukai 等知名人工智能专家参与峰会,并在主题演讲、圆桌论坛等互动形式下,从科学家、企业家、技术专家的视角,解读人工智能的未来发展。

上午,Citadel 首席人工智能官邓力发表了主题为《无监督学习的最新进展》的演讲,他探讨分享了无监督学习的优势,并详细介绍了随机原始-对偶梯度方法(SPDG)与其优良的性能,下面我们将一起浏览邓力老师的盛宴。
首先邓力老师介绍了无监督学习的概念和强大之处,邓力表明无监督的学习范式即是深度学习当中的一种范式。也就是我们不给系统提供一个非常具体的信号,你只是告诉它一些信息,让它以无监督的方式自己学习,能够很成功地学到你让它学的东西。

邓力今天跟大家介绍的一个无监督学习主流的观点就是,以预测为中心的无监督的学习的范式,在这个范式里面我们能够直接完成机器学习的目标,无论是预测还是其他的任务。因为,我们能够直接把输入放到系统里面,然后利用无监督学习的机制(机器自己学习),而不需要人类给它一些标签、标识,利用这种范式就能做出一些非常优良的预测。
随后邓力为我们描绘了监督学习如何使用分类器处理标注问题。我们知道监督学习的特点就是有大量的标注数据集,而最新的监督模型总是表现得比无监督预训练模型更好。那是因为,监督会允许模型能够更好的编码数据集上的特征。只不过当模型应用在其他的数据集上时,监督的效果会衰减。
如下图所示,邓力首先展示的就是从成对输入-输出数据(监督学习)的分类模型。
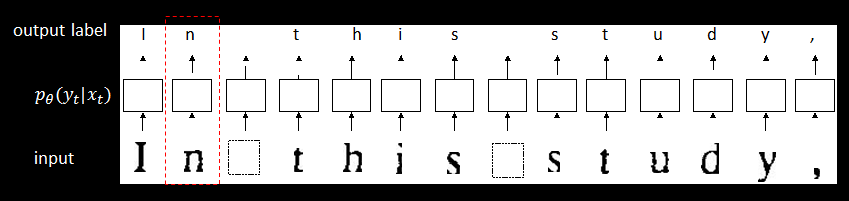
邓力老师表明监督学习,即给机器输入、输出一对数据,让它自己去学习,这种情况下它肯定有一个映射了,一对输入输出就像一个老师,老师教给这个机器如何进行识别或预测。这个范式非常地成功,在人类已经将其应用到语言识别和机器翻译等方面,最近由卷积神经网络引起的高效图像识别也是基于监督学习。这种范式十分成功,其算法都是用这种一对对映射的输入输出方式来训练整个系统。
但是另一方面我们可以看到这种方法的成本十分巨大,我们需要给系统提供输入和输出成对的数据。语音识别还好一点,但是对于其他的应用(比如翻译、医疗应用、图像识别、视频相关的任务和医学影像方面的任务),那么这种监督学习的训练方法就太贵了,成本太高了。

在介绍了监督学习的解决方案后,邓力老师紧接着带我们概览了一遍传统的无监督学习算法。首先就是聚类这一大类,其又包含以下几种方法:
K-均值聚类:该方法是一种通用目的的算法,聚类的度量基于样本点之间的几何距离(即在坐标平面中的距离)。集群是围绕在聚类中心的族群,而集群呈现出类球状并具有相似的大小。K-均值聚类是最流行的聚类算法,因为该算法足够快速、简单,并且如果你的预处理数据和特征工程十分有效,那么该聚类算法将拥有令人惊叹的灵活性。
层次聚类:层次聚类最开始由一个数据点作为一个集群,随后对于每个集群,基于相同的标准进行合并,重复这一过程直到只留下一个集群,因此就得到了集群的层次结构。次聚类最主要的优点是集群不再需要假设为类球形,另外其也可以扩展到大数据集。
其次主要介绍了密度估计类的模型,其中包括:
主题模型:即在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。直观来讲,如果一篇文章有一个中心思想,那么一些特定词语会更频繁的出现。
生成对抗网络:GAN 由两个彼此竞争的深度神经网络——生成器和判别器组成的。生成模型可以被看作是一队伪造者,试图伪造货币,不被人发觉,然而辨别模型可被视作一队警察,努力监察假的货币。博弈中的竞争使得这两队不断的改善方法,直到无法从真实的物品中辨别出伪造的。
变分自编码器:VAE 是一类重要的生成模型,现在广泛地用于生成图像。与 GAN 不同的是,我们是知道图像的密度函数(PDF)的,而 GAN 并不知道图像的分布。
邓力老师随后探讨了如果没有输入、没有一个学习材料系统该怎样学习,所以说机器还得需要一些学习材料,而又不需要人类提供那些成本非常昂贵的输入输出映射。那么在这样一个无监督学习里,我们该怎样训练模型。
邓力老师随后表明,在这个世界上有充分的、多元的一些知识,我们可以把它整合到一个整体的知识体系中,然后将其提供给系统和机器。这是一个非常大胆的想法,怎么把世界上既有的多元化信息分类到各个知识领域是一个有效而困难的问题。
无监督学习分类器
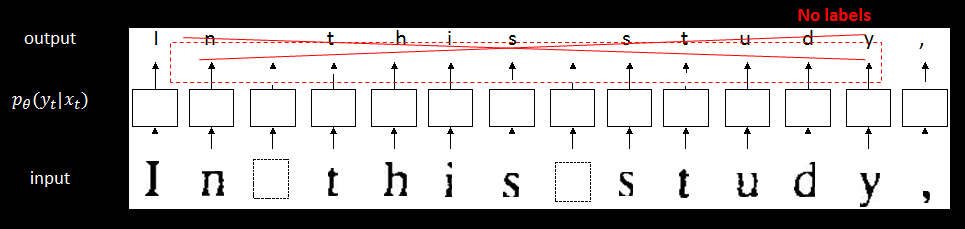
语言模型能从分离的语料库中训练,这样就移除了成对数据(标注数据)的需求,也就不需要耗费大量人力进行标注。
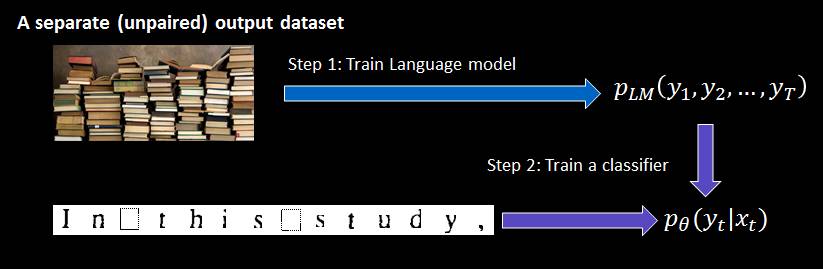
邓力老师是这样做的,因为我们在这个实验里面使用的是语言模式的信息,既使是我们提供的序列作为输入给这个机器,输出还是不能给出一个明确的标签,它只能给出一个非常泛泛的人类语言的标签。所以我们用真实的语言作为机器学习的指导。虽然自然语言的数据可以是一个很困难的东西,但是我们可以单独拿出来使用,不把自然语言和任何的手写图象进行配对。为此我们就极大地降低了训练机器的成本。
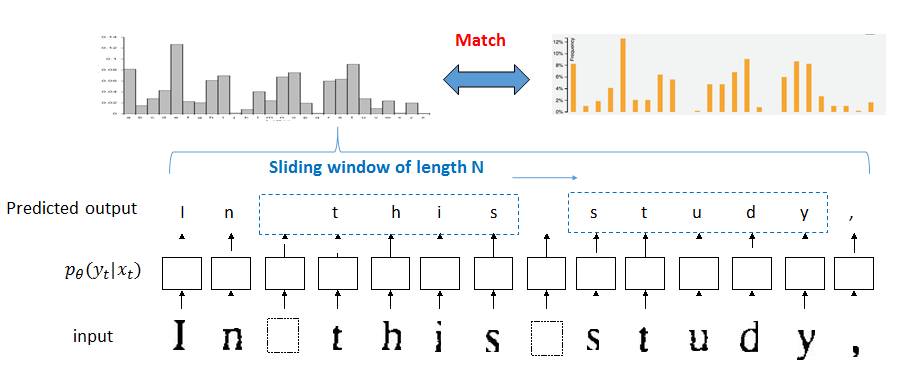
上述问题可以形式化为以下最优化问题:
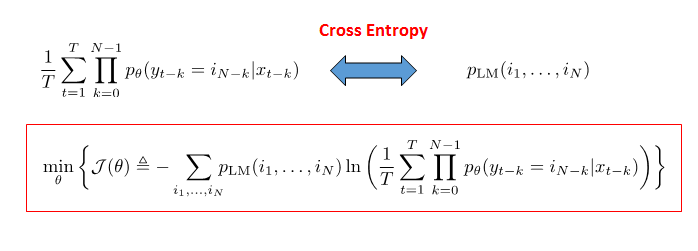
原始问题的成本函数即:
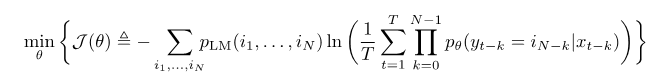
我们可以最优化这个目标函数,求出最优参数,然后就可以求出我们所需要的模型。所以邓力老师跟大家来分享了一下这个成本函数,我们可以看到刚才已经讲过了这个目标函数,最开始它是不好的,但是最后迭代以后它会越来越好。我们可以看到从网站里面它跟你的数据训练是不同的,所以这是很容易建造的,但是却很难优化。
该成本函数存在的巨大问题,因为即使是线性模型也高度非凸性,因此我们很难对其优化,也不可能下降到全局最优解。
SPDG
在邓力老师的演讲中,非常重要的就是采用 SPDG 在没有标注的情况下学习如何做预测。那么我们一起来看看邓力老师如何将前面我们形式化的原始问题转化为极小极大对偶问题,并采用随机梯度下降来求得最优参数。(注:以下参考自邓力等人今年发表的论文:An Unsupervised Learning Method Exploiting Sequential Output Statistics)
为了正确地将随机梯度下降应用到前面我们形式化问题所得到的损失函数,即最小化损失函数:
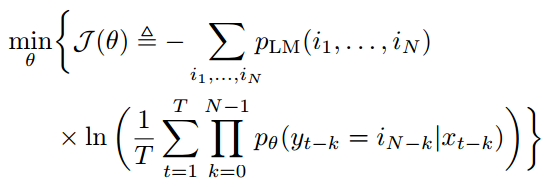
我们需要转换该损失函数以保证其随 t 的累和为对数损失。为此,我们首先需要引进凸共轭函数这一概念。给定一个凸函数 f(u),那么其凸共轭函数 f * (ν) 就定义为:
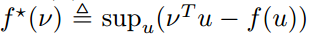
此外,也可以表示为:
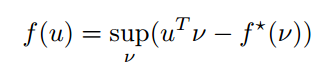
若有函数 f(u) = − ln u,其中标量 u>0,那么其共轭函数为 f* (ν) = −1 − ln(−ν),其中标量 v<0。因此根据上式定义,我们的函数和共轭函数有以下关系:
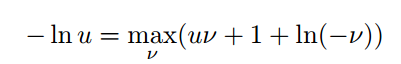
其中,sup 由 max 替代,因为上确界是可以用最大化达到的。随后我们可以将上面的函数代入最开始的损失函数中,而根据拉格朗日对偶性,原始问题的对偶问题是极大极小问题,因此求解原始问题就等价于求解以下极小极大问题(min-max problem):
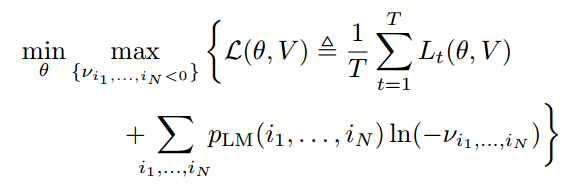
其中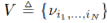 即 V 定义为所有对偶变量的集合
即 V 定义为所有对偶变量的集合 。
。
Lt(θ, V ) 为第 t 个分量函数:
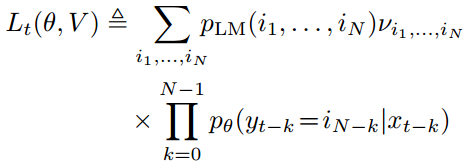
极小极大问题方程的最优解 (θ*,V*) 即称之为函数 L(θ,V ) 的鞍点。一旦求得最优点 (θ*,V*),我们就能保留原始变量θ*作为模型学到的参数。
随机原始-对偶梯度方法(Stochastic primal-dual gradient method /SPDG)
在上式极小极大问题等价优化式中,我们先关于θ极小化 L(θ, V ) 和关于 V 极大化 L(θ, V ) 以求得最优解 (θ*,V*)。这样求得的参数θ即原始问题的最优化解。我们更进一步注意到原始问题的等价式极小极大问题现在是分量函数 Lt(θ, V ), t = 1, . . . , T 从 1 到 T 的累和。

因此,关于θ的极小化和关于 V 的的极大化可以由随机梯度下降解出,即 L(θ, V ) 关于原始变量θ执行随机梯度下降、L(θ, V ) 关于对偶变量 V 执行随机梯度下降。这样重复迭代的方式,即随机原始-对偶梯度(SPDG)方法。为了计算随机梯度,我们先将 L(θ, V ) 的全批量梯度表示为:
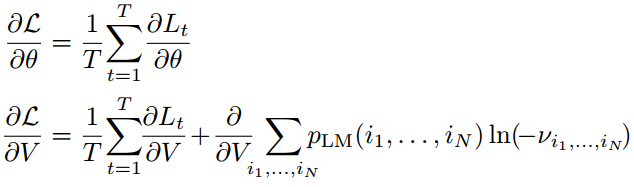
为了计算随机梯度,我们将每个样本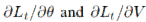 的平均值由各自的随机抽样分量
的平均值由各自的随机抽样分量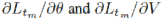 (或其小批量均值)替代,如此迭代重复下去(其中 tm 为集合 {1, . . . , T} 中的均匀随机变量)。在上述算法一中,我们使用小批量梯度概述了 SPDG 方法,其中梯度可以在 TensorFlow 实现中自动计算。此外,对偶变量
(或其小批量均值)替代,如此迭代重复下去(其中 tm 为集合 {1, . . . , T} 中的均匀随机变量)。在上述算法一中,我们使用小批量梯度概述了 SPDG 方法,其中梯度可以在 TensorFlow 实现中自动计算。此外,对偶变量 的负约束(negative constraint)由于在极大极小问题中的内在 log-barrier
的负约束(negative constraint)由于在极大极小问题中的内在 log-barrier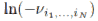 而能被自动执行。因此,我们不需要独立的方法来实现约束条件。
而能被自动执行。因此,我们不需要独立的方法来实现约束条件。
随后,邓力老师分析了对偶问题成本函数的损失表面,它表明对偶问题的损失表面具有更优良的性能,执行随机梯度下降也能得到一个很好的最优解。
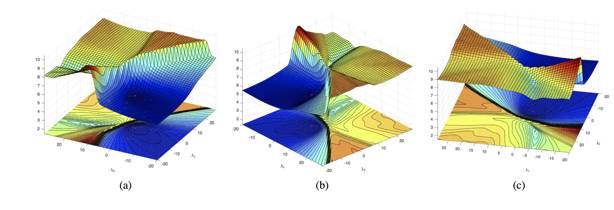 原始域具有崎岖的损失表面(tough loss surface)和高障碍(high barriers)
原始域具有崎岖的损失表面(tough loss surface)和高障碍(high barriers)
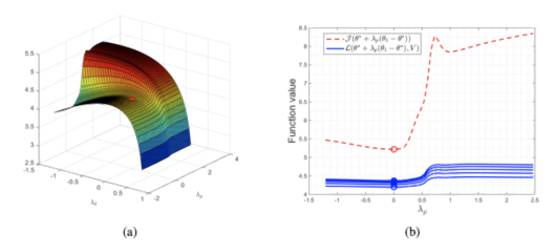
原始-对偶域拥有平滑得多的损失表面
最后,邓力老师总结了本场演讲的精要信息点:

最后邓力老师表明,无监督学习比监督学习更有趣,但是也更困难。我们可以使用更多的一些数据来进行学习,比如说像我刚才所说的 SPDG 方法,该方法不需要进行标记,但它可以直接进行学习来听声音的识别或者说做一些翻译。这样的一个线性的方式,我们也需要很多的发明来使无监督学习更加地有效。
邓力说:「其实我们人类还是很有希望的,因为在未来有越来越多的技术以后,人类就可以有更多的价值。」他认为虽然监督学习很有希望,但未来的趋势还是无监督学习。
点击阅读原文,查看机器之心 GMIS 2017 大会官网↓↓↓











