段晓晨,写过一点爬虫,写过几篇文章。能力虽有限,会尽量把想说的东西讲清楚。
知乎ID:段小草
知乎专栏:小段同学的杂记,
https://zhuanlan.zhihu.com/666666
2.3 文本消息操作小例——查快递
上一小节我们已经完成了对文本消息最基础的操作,但是原样返回内容,并没有做任何更多的操作,这一次我们来试试快递接口。
我使用的依然是前文中提到的文章中的 kuaidi100 查快递接口,不过我在本地测试了许多次通过但是 SAE 的服务器依然无法返回正常结果,在网上搜了很久发现时 快递100 封掉了来自 SAE IP 段的请求,也就是说那个接口不能用了,那段代码也废掉了。所以我们只能退而求其次,做一个通过快递单号判断快递公司的功能。
依然是修改weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
ifmsgType == 'text':
content=xml.find("Content").text
if content[0:2] == u"快递":
post = str(content[2:])
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+post)
h = r.read()
k = eval(h)
kuaidi = k["auto"][0]['comCode']
returnself.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
elifmsgType == 'image':
pass
else:
pass
上面的功能很简单,就是判断用户消息如果前两个字为快递,则取出后面的字符串作为快递单号,通过接口查询后返回结果发送给用户。重复 git 命令更新远程代码后测试效果图如下:
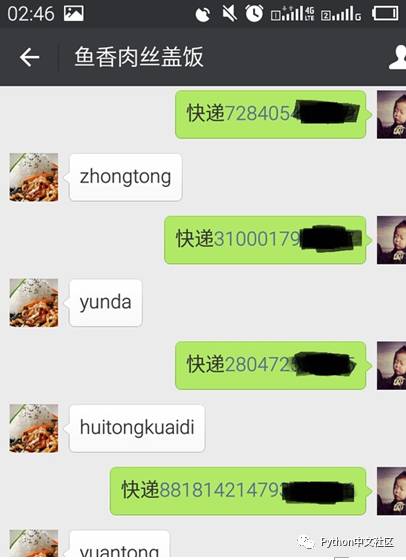
到此我们就完成了第一部分,服务器搭建和一些简单的文本消息操作。
其实对于有一定编程能力的小伙伴来讲,捅破了这层窗户纸以后,其实就能根据自己以前的兴趣和经验做出许多自己喜欢的东西来了。Enjoy coding!
3. 曲径通幽处
上面完成对文本消息的一些基础操作后,我们可以尝试做一些更有趣的事情了。这一部分我们会尝试添加第三方的依赖包,尝试通过抽出函数方法来结构化代码,最后尝试对图片消息进行处理。
3.1 添加第三方依赖包
在上面的接口调用中,我们用到了 urllib2 库,但是熟悉 Python 爬虫的都知道,我们最常用到的其实是第三方的 requests 库,那么怎么把第三方库添加到 SAE 空间中呢?参阅了开发文档以后得到答案:https://www.sinacloud.com/doc/sae/python/tools.html#tian-jia-di-san-fang-yi-lai-bao
具体做法不一定拘泥于官方给出的步骤,可以自己在本地仓库新建文件夹 vendor ,然后使用pip -t 选项指定第三方库安装地址,最后添加路径到 index.wsgi文件中。
以安装 requests 为例。

之后编辑 index.wsgi,在顶部添加代码即可。
# coding: UTF-8
importos
importsae
import web
sae.add_vendor_dir('vendor')
fromweixinInterface import WeixinInterface
有了这些第三方依赖库,我们就能更加轻松地实现需要的功能了。
3.2 函数的结构化方法
文本消息很多,我们如果不断地添加判断,作出一些操作并返回结果,代码势必变得极其臃肿,既不利于阅读,更不利于调试代码。于是我们尝试将之前已有的通过快递单号查询公司的代码改写为函数。
新建 cxkd.py
import urllib2
defdetect_com(postid):
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+postid)
h = r.read()
k = eval(h)
kuaiditpye = k["auto"][0]['comCode']
#print kuaiditpye
returnkuaiditpye
修改 weixinInterface.py,导入 cxkd.py 并修改源代码。
importcxkd
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
ifmsgType == 'text':
content=xml.find("Content").text
if content[0:2] == u"快递":
post = str(content[2:])
kuaidi = cxkd.detect_com(post)
returnself.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
elifmsgType == 'image':
pass
else:
pass
经过测试这种写法是可行的。显然代码量较大的情况下,这样的写法可以使代码更加简洁易懂,便于修改调试。
3.3 旧瓶装新酒——再谈人脸识别
在我很久一篇的专栏中(Python 爬虫笔记(2):插播——我也来做Facemash! - 小段同学的杂记 - 知乎专栏)曾经提到过微软的 How-old.net 人脸识别的接口,当然那个接口是我自己通过抓包拿到的,那篇文章赞数寥寥,平时好像也没见谁拿那个接口实现过什么功能,这次想起来要处理图片消息,我第一个便又想起来那个接口。
旧瓶装新酒,能饮一杯无。
接口的详情可以到上文的链接中查看,这里直接给出代码好了。
新建 imgtest.py
# -*- coding: utf-8 -*-
import requests
import re
defimgtest(picurl):
s = requests.session()
url = 'http://how-old.net/Home/Analyze?isTest=False&source=&version=001'
header = {
'Accept-Encoding':'gzip, deflate',
'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0",
'Host': "how-old.net",
'Referer': "http://how-old.net/",
'X-Requested-With': "XMLHttpRequest"
}
data = {'file':s.get(picurl).content}
#data = {'file': open(sid+'.jpg', 'rb')}
#此处打开指定的jpg文件
r = s.post(url, files=data, headers=header)
h = r.content
i = h.replace('\\','')
#j = eval(i)
gender = re.search(r'"gender": "(.*?)"rn', i)
age = re.search(r'"age": (.*?),rn', i)
ifgender.group(1) == 'Male':
gender1 = '男'
else:
gender1 = '女'
#print gender1
#print age.group(1)
datas = [gender1, age.group(1)]
returndatas
修改 weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
ifmsgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
kuaidi = cxkd.detect_com(post)
returnself.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
returnself.render.reply_text(fromUser,toUser,int(time.time()), content)
然后 git 提交到远程仓库。
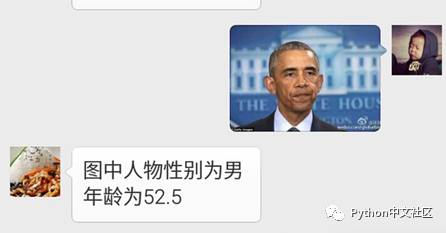
4. 鱼香肉丝盖饭
You share rose get fun.
赠人玫瑰,手有余香。
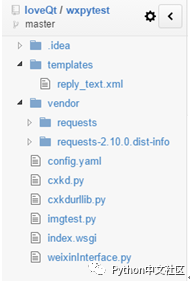
我把这次的所有代码贴到 Github 了。
GitHub - loveQt/wxpytest
也可以看出来这次的所有文档结构:(Chrome插件 Octotree)
在下期Python开发微信公众号后台(系列三)中,将会谈到如何对一个聊天机器人进行抓包分析接口以及如何将现成的聊天机器API 部署到自己的公众号上
⊙生成器:
关于生成器的那些事儿
⊙爬虫代理:
如何构建爬虫代理服务
⊙地理编码:
怎样用Python实现地理编码
⊙nginx日志:
使用Python分析nginx日志
⊙ 淘宝女郎:
一个批量抓取淘女郎写真图片的爬虫
⊙ IP代理池:
突破反爬虫的利器——开源IP代理池
⊙ 布隆去重:
基于Redis的Bloomfilter去重(附代码)
⊙ 内建函数:
Python中内建函数的用法
⊙ QQ空间爬虫:
QQ空间爬虫最新分享,一天 400 万条数据
⊙ 对象:
Python教你找到最心仪对象
⊙ 线性回归:
Python机器学习算法入门之梯度下降法实现线性回归
⊙ 匿名代理池:
进击的爬虫:用Python搭建匿名代理池
⊙ 发射导弹:
Python发射导弹的正确姿势
在公众号底部回复上述关键词可直接打开相应文章

Python 中 文 开 发 者 的 精 神 家 园
— Life is short,we use Python —









