问题:GPU 内存限制
GPU 在深度神经网络训练之中的强大表现无需我赘言。通过现在流行的深度学习框架将计算分配给 GPU 来执行,要比自己从头开始便捷很多。然而,有一件事你会避之唯恐不及,即 GPU 的动态随机存取内存(DRAM(Dynamic Random Access Memory))限制。
在给定模型和批量大小的情况下,事实上你可以计算出训练所需的 GPU 内存而无需实际运行它。例如,使用 128 的批量训练 AlexNet 需要 1.1GB 的全局内存,而这仅是 5 个卷积层加上 2 个全连接层。如果我们观察一个更大的模型,比如 VGG-16,使用 128 的批量将需要大约 14GB 全局内存。目前最先进的 NVIDIA Titan X 内存为 12GB。VGG-16 只有 16 个卷积层和 3 个全连接层,这比大约有 100 个层的 resnet 模型小很多。

图 1: 当使用基线、全网分配策略时 GPU 内存的使用情况(左轴)。(Minsoo Rhu et al. 2016)
现在,如果你想要训练一个大于 VGG-16 的模型,而你又没有一个具有内存的 GPU,你也许有几个解决内存限制问题的选择。
-
减小你的批量大小,但这可能会妨碍你的训练速度和精确度。
-
在多 GPU 环境下做模型并行,这是另一个复杂的事情。
-
缩小你的模型,如果你不情愿做出上述两个选择,或者已经尝试但效果不好。
或者你也可以等待下一代更强大的 GPU 出现。然而将来的网络变得更大更深是大势所趋,我们并不希望物理内存的限制成为算法开发的一个障碍。
观察:什么占用内存?
我们可以根据功能性把 GPU 内存中的数据分为 4 个部分:
前 3 个功能容易理解。模型参数的意义对于所有人来说都很熟悉了。特征图是正向过程中生成的中间结果。梯度图是反向过程中生成的中间结果。而工作区是 cuDNN 库函数所使用的临时变量/矩阵的一个缓冲区。对于一些 cuDNN 函数,用户需要将缓冲区作为函数参数传给 GPU 内核函数。一旦函数返回,该缓冲区将被释放。
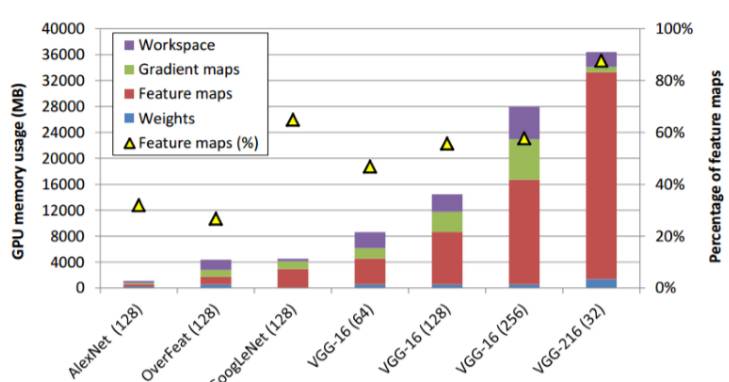
我们可以看到,一般而言,我们有的层越多,分配给特征图的内存比重就越多(由上图中的三角形表示)。我们也可以看到对于像 VGG-16 这样的更大模型来说,这一比例基本上要超过 50%。
想法:使用 CPU 内存作为临时容器
有一个关于特征图的事实:它们在正向过程中生成之后立刻被用于下一层,并在稍后的反向过程中仅再用一次。每个 GPU 内核函数仅使用与当前层(通常只有 1 个张量)相关的特征映射。这将导致绝大多数内存在几乎所有的时间上出现空置的情况(它们保有数据但不使用)。
这一想法是:如果 GPU 内存中的大部分数据出现空置,为什么不把它们保存在更便宜的 CPU 内存上呢?下图更清晰地展现了这一想法。
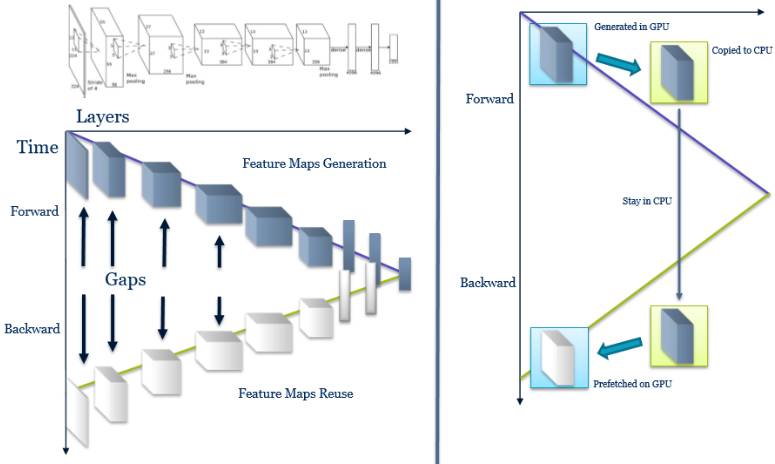
左侧部分所示的间隙表明特征图如何在内存之中被空置。右侧部分表明这一节省 GPU 内存使用的想法:使用 CPU 内存作为那些特征图的临时容器。
权衡:时间 vs 空间
根据论文,vDNN(虚拟化 DNN,也就是原文的系统设计的名称)把 AlexNet 的平均 GPU 内存使用成功降低了 91%,GoogLeNet 的降低了 95%。但你很可能已经看到,这样做的代价是训练会变慢。例如,vDNN 可以在 12GB 的 GPU 上使用 256 的批量训练 VGG-16,但是假设我们在一块拥有足够内存的 GPU 上训练同样的模型而不使用 vDNN 来优化内存使用,我们可以避免 18% 的性能损失。
当使用 cuDNN 核时,工作区大小也会出现权衡的情况。一般而言,你有的工作区越多,你可以使用的算法就越快。如果有兴趣请查阅 cuDNN 库的参考。在后面的整个讨论中我们都将会看到有关时间空间的这一权衡。
优化策略:在前向过程中卸载,在后向过程中预取
你应该已经知道 vDNN 是如何在正向过程中优化内存分配的。基本的策略是在生成特征图后将其从 GPU 上卸下传给 CPU,当它将在反向过程中被重新使用时再从 CPU 预取回 GPU 内存。这个存储空间可被释放以作他用。这样做的一个风险是如果网络拓扑是非线性的,特征图的一个张量可能被应用于数个层,从而导致它们不能被立刻卸载。当然,这个问题可以通过简单的完善优化策略来解决。
在后向过程中,vDNN 采用一种更具侵略性的策略,这是由于相较于特征图,梯度图不存在「稍后重用」的问题。因此一旦生成了相关的权值更新,它们就可以被释放(相较于那些映射,这些权值更新是很小的)。
优化策略:内存管理器 CUDA 流
vDNN 实现的关键是使用一个 cuda 流来管理内存分配/释放、卸载和预取。以下是一些细节:
传统的 cuda 内存分配/释放(cudaMalloc & cudaFree)是同步性 API。由于这两个操作随着训练过程需要不断地被执行,同步性 API 并不够高效。
如同分配/释放操作,卸载 API 也需要是异步性的。当 vDNN 选择卸载特征图的一个张量时,vDNN 的内存管理器流(memory manager stream of vDNN)将在主机上分配一个页锁定的内存区域,并且通过 PCIe 发出一个非阻塞传输(a non-blocking transfer)将其传输至 CPU。这些特征图张量在正向过程中为只读的,因此这个传输过程可以在计算中被安全地覆盖。当依赖于其传输和计算都完成后,相关的张量可以被释放。只有当前层的卸载完成时,才能进行下一层的处理。
预取操作是在反向处理中从 CPU 返回到 GPU 以得到之前被卸载的特征图。和上面的操作类似,预取操作也需要是异步性的。由于在预取和相同层的计算之间存在数据依赖,vDNN 将同时异步开始当前层的计算以及前一层的预取。
成本:为了节省内存的性能损失在哪里?
最显著的潜在性能损失来自于由卸载/预取引入的隐式依赖(implicit dependency)。我们考虑这样一种情况:当数据传输比正向计算需要花费更长的时间时,卸载/预取操作将会带来性能损失。下图表清晰地表明这种情况(图 9:卸载和预取的性能影响 (Minsoo Rhu et al. 2016))
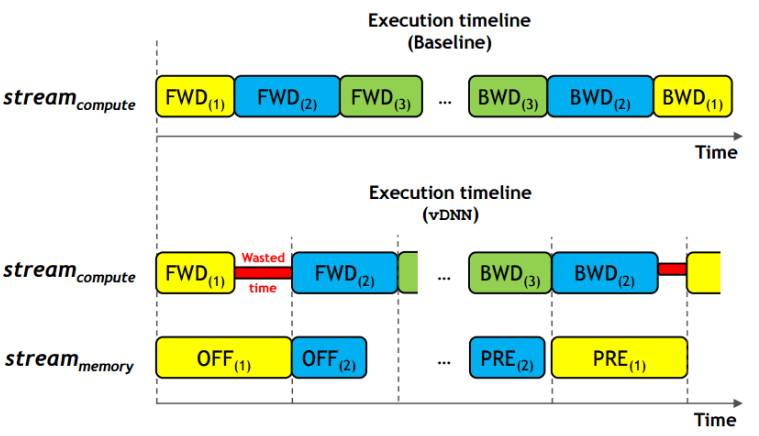
相似情形也可能在反向过程中发生。
问题的形式化:在限制内存预算的情况下,如何获得最佳性能?
如上所述,在时间和空间之间有一个权衡,并且在前的章节中我们已经看到这个权衡是产生作用的。想象一下你正在 12GB 的 GPU 上使用 128 的批量(这需要 14GB 内存如果没有使用卸载/预取)训练 VGG-16。假设我们可以使用上面提到的想法,把内存使用压缩到只有 2GB,那么仅使用了大约 2GB 的内存也许很浪费,因为你本可以利用空闲的 10GB 空间来减少性能损失(这里忽略能耗方面的成本)。因此,我们可以这种方式重新形式化这个问题:在限制内存预算的情况下,如何获得最佳性能?
配置时间-空间权衡:决定一个层是否应该被卸载/预取(offloaded/prefetched),以及应该选择哪种卷积算法。
从这个问题的形式化中我们可以看出,我们往往并不需要把内存使用压缩到极致,有些层完全可以不被卸载/预取。为了取得最佳配置,我们需要为每个层决定两件事:一个是我们是否需要卸载/预取,一个是我们在前向/反向传播过程中该选择哪个算法(更快收敛的算法需要更大的存储空间)。
通常,靠近输入的层有较长重用度(reuse)距离。因此,首先卸载/预取这些层比较好。于是,我们并不需要为每一层决定是否使用(这个选择总量随层级数成指数增长)。我们只需要选择一层作为基准,与之相比更加靠近输入层的都进行卸载/预取,其余层将其张量保留在 GPU 上。
为每层决定算法也并不可行(同样选择总量随层级数成指数增长)。我们可以通过例如强制多层使用相同的算法(gemm 或 fft 等算法)来缩小我们的可选备用空间。这将原本指数级大小的选择数降为线性大小。
经过上面的处理,现在我们的配置选择空间已经足够小,这样我们可以尽情搜索以确定最佳配置方案。下面的图表说明了我们的配置空间:
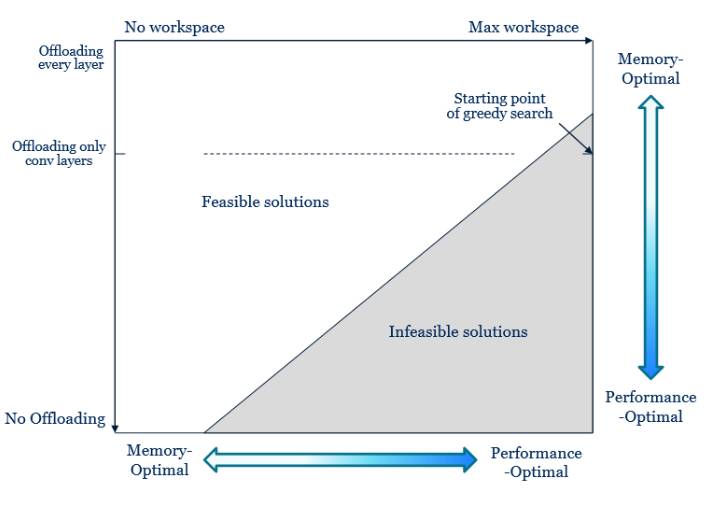
左上角表示最节省内存的配置(卸载/预取每一层,并使用最慢的算法),右下角表示性能最优的配置(当然,真实的配置空间应该是网格,可行模型与不可行模型之间的边界应改成阶梯状,不过这一图表足以表明整个搜索空间的大致分布特征)。
下一步即找到具有最佳性能的可行配置。我们可以沿可行性边界搜索配置。如果你对该搜索过程的实现细节感兴趣,请参阅原论文(搜索过程在第 3.C 节中进行了描述)。
论文连接:https://arxiv.org/pdf/1602.08124.pdf
推荐者介绍:
Hongyu 毕业于上海交通大学 09 级 ACM 班,多伦多大学在读博士,现从事关于深度神经网络训练过程的一些 profiling 的工作。
加入机器之心 ML 系统与架构小组:
近些年人工智能的突破不仅仅是机器学习算法的努力,更有包含了其所依赖的系统和架构领域的进步。如果你想更加全面的了解机器学习这个领域,对其依赖的上下游领域的了解会很有帮助。系统和架构就是这样一个下游领域。这个方向的工作极大方便了其上游算法的开发,或许你也是现在诸多 ML 系统产品的用户之一。但面对一个这样重要的跨领域的方向,你可能会感到这样一些困境:
-
找不到合适的学习资料
-
有学习动力,但无法坚持
-
学习效果无法评估
-
遇到问题缺乏讨论和解答的途径
不论你是想要获得相关跨领域的更全面大局观,还是你只是想对手中的 ML 系统工具更加了解,你都是机器之心想要帮助和挖掘的对象。基于这个方向现在越来越成为众多研究人员关注的焦点,
机器之心发起了一个互助式学习小组——「人工智能研学社· ML 系统与架构小组」。本小组将通过优质资料分享、教材研习、论文阅读、群组讨论、专家答疑、讲座与分享等形式加强参与者对强化学习和深度学习的理解和认知。
1)添加机器之心小助手微信,并注明:加入系统与架构学习组

2)完成小助手发送的入群测试(题目会根据每期内容变化),并提交答案,以及其他相关资料(教育背景 、从事行业和职务 、人工智能学习经历等)
3)小助手将邀请成功通过测试的朋友进入「人工智能研学社· ML 系统与架构学习组」
入群测试 QUIZ
1)教育背景 2)从事行业和职务 3)人工智能经历 4)人工智能系统或架构经历
-
数据并行和模型并行的区别在于哪里?
-
在训练过程中,数据并行和模型并行很难达到线性的 scale-up,你认为瓶颈会在哪?有没有办法突破这样的瓶颈?这些突破的方法又会造成什么样的副作用?
©本文为机器之心原创,
转载请联系本公众号获得授权
。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





