
数据挖掘入门与实战 公众号: datadw
机器学习技术在应用之前使用“训练+检验”的模式(通常被称作”交叉验证“)。
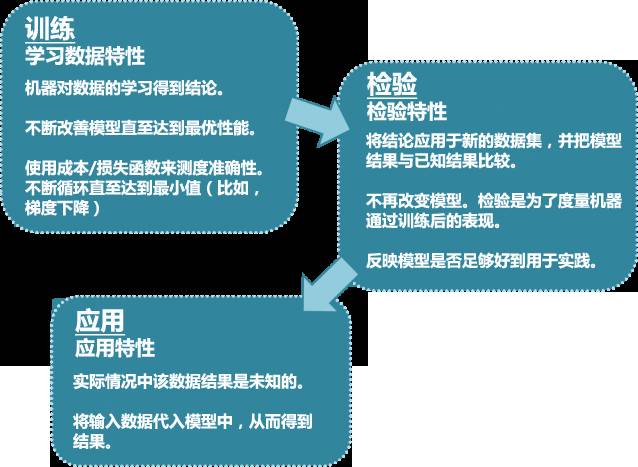
预测模型为何无法保持稳定?
让我们通过以下几幅图来理解这个问题:
此处我们试图找到尺寸(size)和价格(price)的关系。三个模型各自做了如下工作:
第一个模型使用了线性等式。对于训练用的数据点,此模型有很大误差。这样的模型在初期排行榜和最终排行榜都会表现不好。这是“拟合不足”(“Under fitting”)的一个例子。此模型不足以发掘数据背后的趋势。
第二个模型发现了价格和尺寸的正确关系,此模型误差低/概括程度高。
第三个模型对于训练数据几乎是零误差。这是因为此关系模型把每个数据点的偏差(包括噪声)都纳入了考虑范围,也就是说,这个模型太过敏感,甚至会捕捉到只在当前数据训练集出现的一些随机模式。这是“过度拟合”(“Over fitting”)的一个例子。这个关系模型可能在初榜和终榜成绩变化很大。
在应用中,一个常见的做法是对多个模型进行迭代,从中选择表现更好的。然而,最终的分数是否会有改善依然未知,因为我们不知道这个模型是更好的发掘潜在关系了,还是过度拟合了。为了解答这个难题,我们应该使用交叉验证(cross validation)技术。它能帮我们得到更有概括性的关系模型。
实际上,机器学习关注的是通过训练集训练过后的模型对测试样本的分类效果,我们称之为泛化能力。左右两图的泛化能力就不好。在机器学习中,对偏差和方差的权衡是机器学习理论着重解决的问题。
什么是交叉验证?
交叉验证意味着需要保留一个样本数据集,不用来训练模型。在最终完成模型前,用这个数据集验证模型。
交叉验证包含以下步骤:
保留一个样本数据集。--测试集
用剩余部分训练模型。--训练集
用保留的数据集(测试集)验证模型。
这样做有助于了解模型的有效性。如果当前的模型在此数据集也表现良好,那就带着你的模型继续前进吧!它棒极了!
交叉验证的常用方法是什么?
交叉验证有很多方法。下面介绍其中几种:
1. “验证集”法
保留 50% 的数据集用作验证,剩下 50% 训练模型。之后用验证集测试模型表现。不过,这个方法的主要缺陷是,由于只使用了 50% 数据训练模型,原数据中一些重要的信息可能被忽略。也就是说,会有较大偏误。
2. 留一法交叉验证 ( LOOCV )
这种方法只保留一个数据点用作验证,用剩余的数据集训练模型。然后对每个数据点重复这个过程。这个方法有利有弊:
3. K 层交叉验证 (K- fold cross validation)
从以上两个验证方法中,我们学到了:
应该使用较大比例的数据集来训练模型,否则会导致失败,最终得到偏误很大的模型。
验证用的数据点,其比例应该恰到好处。如果太少,会导致验证模型有效性时,得到的结果波动较大。
训练和验证过程应该重复多次(迭代)。训练集和验证集不能一成不变。这样有助于验证模型有效性。
是否有一种方法可以兼顾这三个方面?
答案是肯定的!这种方法就是“ K 层交叉验证”这种方法简单易行。简要步骤如下:
把整个数据集随机分成 K“层”
用其中 K-1 层训练模型,然后用第K层验证。
记录从每个预测结果获得的误差。
重复这个过程,直到每“层”数据都作过验证集。
记录下的 k 个误差的平均值,被称为交叉验证误差(cross-validation error)。可以被用做衡量模型表现的标准。
把整个数据集随机分成 K“层”
对于每一份来说:
1).以该份作为测试集,其余作为训练集; (用其中 K-1 层训练模型,然后用第K层验证)
2).在训练集上得到模型;
3).在测试集上得到生成误差,这样对每一份数据都有一个预测结果;(记录从每个预测结果获得的误差)
记录下的 k 个误差的平均值,被称为交叉验证误差(cross-validation error)。可以被用做衡量模型表现的标准
取误差最小的那一个模型。
通常。此算法的缺点是计算量较大。
当 k=10 时,k 层交叉验证示意图如下:
这里一个常见的问题是:“如何确定合适的k值?”
记住,K 值越小,偏误越大,所以越不推荐。另一方面,K 值太大,所得结果会变化多端。K 值小,则会变得像“验证集法”;K 值大,则会变得像“留一法”(LOOCV)。所以通常建议的值是 k=10 。
如何衡量模型的偏误/变化程度?
K 层交叉检验之后,我们得到 K 个不同的模型误差估算值(e1, e2 …..ek)。理想的情况是,这些误差值相加得 0 。要计算模型的偏误,我们把所有这些误差值相加。平均值越低,模型越优秀。
模型表现变化程度的计算与之类似。取所有误差值的标准差,标准差越小说明模型随训练数据的变化越小。
我们应该试图在偏误和变化程度间找到一种平衡。降低变化程度、控制偏误可以达到这个目的。这样会得到更好的预测模型。进行这个取舍,通常会得出复杂程度较低的预测模型。
Python Code
from sklearn import cross_validation
model = RandomForestClassifier(n_estimators=100)
#简单K层交叉验证,10层。
cv = cross_validation.KFold(len(train), n_folds=10, indices=False)
results = []
# "Error_function" 可由你的分析所需的error function替代
for traincv, testcv in cv:
probas = model.fit(train[traincv], target[traincv]).predict_proba(train[testcv])
results.append( Error_function )
print "Results: " + str( np.array(results).mean() )
R Code
library(data.table)
library(randomForest)
data
str(data)
#交叉验证,使用rf预测sepal.length
k = 5
data$id
list
# 每次迭代的预测用数据框,测试用数据框
# the folds
prediction
testsetCopy
# 写一个进度条,用来了解CV的进度
progress.bar
progress.bar$init(k)
#k层的函数
for(i in 1:k){
# 删除id为i的行,创建训练集
# 选id为i的行,创建训练集
trainingset
testset
#运行一个随机森林模型
mymodel
#去掉回应列1, Sepal.Length
temp
# 将迭代出的预测结果添加到预测数据框的末尾
prediction
# 将迭代出的测试集结果添加到测试集数据框的末尾
# 只保留Sepal Length一列
testsetCopy
progress.bar$step()
}
# 将预测和实际值放在一起
result
names(result)
result$Difference
# 用误差的绝对平均值作为评估
summary(result$Difference)
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注









