

导读
:
法国研究机构
Leti
正在开展一项
“
后
CMOS”
计划,该计划依赖于
3
大支柱和一些具体的
研究,
如神经
网络
和量子计算
…

Leti
的纳米电子技术营销和
战略
总监
Carlo
Reita
介绍
了
这
3
大支柱。它们是:新颖的设备,
3D
堆叠和新的计算架构。
“研究这个的一个原因是为了支持我们的母公司CEA的高性能计算任务,有10MW左右的数据中心功耗需要降低,该需求已经迫在眉睫”,Reita说,“IoT将不得不在”叶节点“(leaf nodes)嵌入神经网络,而且功耗效率很重要。”
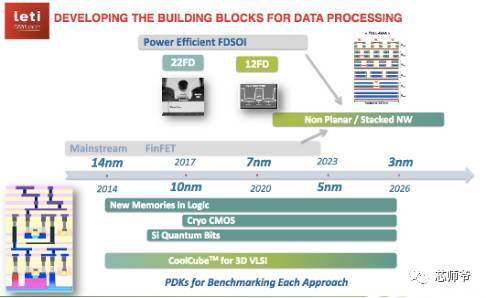
图:链接新设备,3D集成和新的计算架构路线图
目前,全耗尽绝缘体上硅(FD-SOI)是一项重要的实施技术。Reita表示:“大约4年前,我们放弃了FinFET,并专注于平面FD-SOI。三星拥有28nm FD-SOI技术,Globalfoundries公司拥有22nm的,我们正在帮助Globalfoundries演进到12nm节点。
然而,Reita认为,从中期来看, FinFET和FD-SOI之间的差异会随着晶体管制造的两个分支演变为堆叠的水平纳米线而逐渐减少,门极全面在7nm及以上。“FD-SOI可以扩展到10nm节点,即20nm间距和10nm栅极长度,但是这两个分支都会有问题,特别是有很多静电问题,还有设备老化和运行稳定性问题。
而2D微缩的这种问题,或至少是这种2D微缩对成本的影响,是Leti多年来一直在追求3D集成的原因之一,该机构已经研发出了它们自己的方法,被称为CoolCube。Rieta表示,3D堆叠——除了一些特例,如3D-NAND闪存——尚未找到商业的驱动力。

排除障碍
“我们已经排除了很多障碍,并与高通和应用材料公司合作,用14nm的FD-SOI结构进行堆叠,通过使用铜到铜键合和硅通孔(TSVs)进行两层和几层集成“,Reita说:“多层整体集成才是最终的3D制程归宿。”
在这个过程中,需要克服的一个关键性挑战是推广3D设计。EDA基本上是基于二维范式,并且被设置为针对平面的2D性能进行优化,这也反映了成本或生产的需求。EDA工具不支持3D设计,从而使3D的一些优势无从展现,例如,放置接近逻辑和显着增加带宽的内存。
Reita说:“我们与佐治亚理工学院开展联合研究工作,并与Mentor Graphics合作”,他说,“这里有一个是‘鸡生蛋,还是蛋生鸡”的问题。EDA行业不愿意投资开发工具,除非有市场,而芯片开发商无法在没有工具支持的情况下开展系统的3D电路研发工作。
“我们有一些内部工具,但3D的思维并不那么容易,当比较2D和3D设计分区时,平均线长度大致相同,但是你所做的是要减少最长的线,切断2D线长度分布的长尾,这是一件很有意义的事”,Reita说。
一般情况下,开发3D电路的进度一直很慢,然而,现在情况有了变化,因为量子计算的价值开始显现。
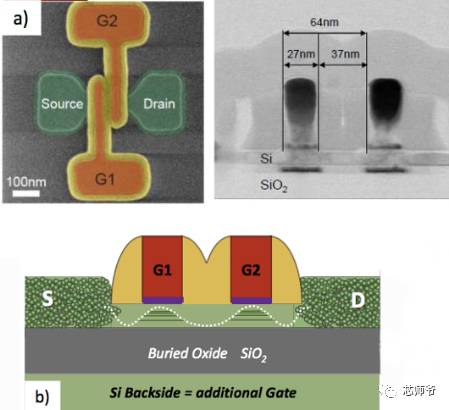
图:建立在28nm FDSOI工艺300mm晶圆上的双栅极量子位
“在过去的40年左右的时间里,量子计算的研究主要集中在III-V复合半导体的量子阱中,但是在过去的10年左右的时间里,业界已经开始研究硅基方案。Leti已经报道了使用28nm FD-SOI工艺,在一个300mm的晶圆上构建量子位,实际上是一对由隧道结耦合的量子器件。”
由于与CMOS的潜在兼容性,硅的使用提供了更实惠的量子计算和混合量子/常规计算的前景。Reita说:“硅量子计算可以重用纳米电子技术的大量工程。” 然而,量子计算不太可能取代常规计算,Reita说:“这主要是因为大多数材料需要低于100mK的低温来实现量子计算的足够长的电子 - 自旋寿命。”
不幸的是,低于4K的CMOS倾向于停止处理电子和晶格温度之间的不平衡,Reita说。“掺杂剂冻结并且连接可能变成超导或高电阻。所以Leti还在致力于低温CMOS的研究,以确保常规计算和量子计算之间的接口是可能的。”
Reita表示,挑战包括从单个和几个量子位转移到多个量子位,并了解如何限制需要量子校正的噪声水平。Reita说:“5年后,我们希望有一台量子计算机能够进行有意义的计算。”
神经网络
量子计算是业界正在追求的新型计算架构之一,而另一种在业界已经变得越来越红火,并且已经部署的是神经网络。Leti正在努力尝试为这一领域的研究伙伴提供附加值。
摩尔定律的进展和硬件架构的并行化正在允许神经网络的大幅度扩大,硬件可以模拟具有数百万个神经元和数十亿个突触的网络。到目前为止,所选的架构已经在数据中心接受了巨大的数据集训练。Reita解释说,循环神经网络对于识别诸如语音的序列是有效的,而卷积NN使用可训练的卷积滤波器进行图像识别。
尽管如此,问题和架构方法的范围也很广泛。一般来说,更为软件化的解决方案效率不高但灵活性更高。硬件导向越多,效率越高,但具体情况越多,灵活性越差。
Leti正在研究的一个方法是如何分层地解决问题。Reita说,这样的问题可以在智能手机、电视或云端解决。
Leti是CEA Tech内部多个研究机构的联合项目的一部分,包括Leti和List。List是系统和技术集成实验室。他们正在研究使用先进硅制造的专用电路和存储器上的神经网络的物理实现,这涉及到新设备和3D集成,包括CoolCube、突触元素ReRAM、FD-SOI和纳米线。
Leti开发出了一种称为N2D2的神经网络设计平台,它可以生成软件和可综合的硬件。
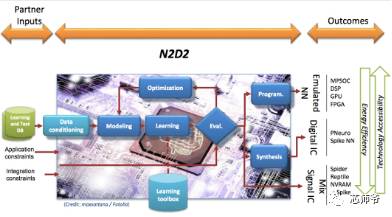
图:N2D2内部神经网络工具设计与优化
在神经网络设计方面,Leti已经转向“尖峰架构”(spiking architectures),这是一种神经元和突触通过发射一系列信号尖峰而对时间进行建模和通信的方案。神经元在每个传播周期都不会发生(像多层感知器网络一样发生),但是当神经元达到特定的值或状态时,它们会发射,尖峰会将相关神经元的状态推高或降低,并且可能存在固有的衰变功能。可以使用各种方案来编码实数值,或者依赖于尖峰的频率或尖峰之间的时序。
Reita说:“我们可以拥有一个完全异步的系统,所以当它不活跃时,没有功耗,这在模拟和spiking systems中的低功耗特性更加显著。”
欧洲的NeuRAM3
Leti是NeuRAM 3欧洲协作研究项目的一部分,该项目正在开发用于在28nm FD-SOI中实现的动态神经元异步处理器可扩展学习(DynapSEL)。该设计于2016年11月推出,预计今年7月推出芯片。

图:DynapSEL芯片的平面图和规格。资料来源:苏黎世大学神经信息学研究所(G.Indiveri教授)和NeuRAM3项目
现在,DynapSEL有一块SRAM。具有非易失性存储器的低功耗版本将在程序的第二阶段,即到2018年底交付。至于它是什么样的非易失性存储器,Reita表示还没有最终决定。
有不同的成熟度水平,易于集成的选择以及对突触行为的适用性。Reita表示,像氧化铪这样的条状OxRAM是实现一体化的最佳选择。导电桥接RAM(CBRAM)也是设计的理想选择,因为电压电平与CMOS匹配,且电流最低。最终,基于硫族化物的相变存储器(PCM),似乎是英特尔推出的3D Xpoint存储器的最爱。
结语
Reita总结指出,摩尔定律在过去几年面临的挑战不断加强,这正是我们进行以上研究的意义所在。令Rieta感到高兴的是,4年前Leti的一些选择现在开始有所回报。
“我们现在决定研究的方向正在逐渐被广泛接受,微缩工艺仍然是主流,但也有很多可能的替代方案。我们正在进入系统优化的时代,这就是系统公司要重新整合资源的原因“。
来源 | Leti
芯师爷独家整理
各位小伙伴们好,芯师爷致力于为产业人士搭建最强人脉圈,在这里除了能收获产业优质文章,更能加入高端人脉群。
加群方法:
长按二维码,加群主为好友,备注:入群。

行业群:
物联网IOT、电子代工厂SMT、机器人与人工智能、充电桩行业、工业自动化与4.0、无人机群、汽车电子科技、智能可穿戴
新能源汽车产业、VR/AR虚拟现实、
安防与监控系统、IC设计与原厂、半导体材料设备晶圆、半导体封测、半导体代理分销、半导体投融资群、元器件撮合交易1群
职能群:
市场销售、
采购、供应链管理、设计工程师、AE.FAE、品牌公关媒介、人事招聘
群规:
1、所有群都是实名制,入群即修改群昵称:昵称+公司+职位;
2、欢迎群友交流,自我介绍资源,杜绝刷屏广告;
3、鼓励多多讨论产业相关话题,禁止使用粗俗、恶意词汇。
回复
“
报告
”
可查看所有半导体产业研究报告
往期精彩回顾
(
点击蓝字 直接阅读
)
:
你问我上半年集成电路情况如何?我说你看完这篇文便晓得!
JDI将在中国等地裁员4000人;上半年各省市IC产量,看看谁最强
闷声赚钱,那些悄悄将自动驾驶技术商业化的中国公司





