来源: arXiv
编译:张易 刘小芹
【新智元导读】这是一项从图像的文字描述合成出图像的研究,在自然语言表征和图像合成研究的基础上,研究者开发了简单有效的 GAN 架构和训练策略,实现了从人类对花和鸟的描述中合成图像。
论文地址:https://github.com/zsdonghao/text-to-image

根据图像的文本描述自动合成出现实风格的图像既有趣又有用,但目前的 AI 系统离实现这一目标还很远。然而,近年来出现了通用且强大的循环神经网络架构,可以学习判别性的文本特征表征。同时,深度卷积生成对抗网络(GAN)也已经开始生成特定类型的图像,如面孔、专辑封面和房间内饰等,十分引人注目。在本研究中,我们开发了一种新颖的 GAN 架构,有效地桥接了文本和图像建模中的这些进展,将视觉概念从字符转换为像素。研究展示我们提出的架构从详细的文字描述中产生鸟和花的合理图像的能力。
研究中,我们将人类书写的、单句形式的图像描述直接转换成图像像素。例如,“这只小鸟有一个短而尖的橙色的喙和白色的肚子”,或者“这朵花的花瓣是粉红色的,另一朵是黄色的”。从视觉描述中生成图像一直是研究兴趣点之一,但还远未解决。

图1.文本描述生成的图像示例。左:描述来自零样本数据,是系统从未见过的文字;右:描述来自训练集。
用 attribute 表示属性很好,但问题在于 attribute 可能需要特定的领域知识。相比之下,自然语言提供了通用且灵活的交互界面,来描述任何视觉类别空间中的对象。理想情况下,我们应该将文本描述的通用性和 attribute 的判别性结合起来。
为了解决这个具有挑战性的问题,需要解决两个子问题:首先,学习指向重要视觉细节的文本特征表征; 第二,使用这些特征来合成以假乱真的图像。幸运的是,在过去几年里,深度学习已经在这两个子问题——自然语言表征和图像合成方面取得了巨大的进步,我们的努力将以此为基础展开。
然而,深度学习尚未解决的一个难题是,以文本描述为条件生成的图像分布是高度多模态的,在某种意义上说,某一种文字描述可能对应许多正确的像素配置。从图像到文本的转化也受到这个问题的影响。
这种多模态对于生成对抗网络来说是非常自然的应用,其中生成网络被优化以愚弄用于对抗训练的判别器。通过调节生成器和判别器,我们可以自然地为这种现象建模,因为判别网络是一个能够“智能地”自适应的损失函数。
我们的主要贡献是开发简单有效的 GAN 架构和训练策略,使得从人类对花和鸟的描述中合成图像。我们主要使用了 Caltech-UCSD Birds 数据集和 Oxford-102 Flowers 数据集,每个图像我们收集了5 个文本描述,作为我们的评估设定。我们的模型在训练类别的一个子集上进行了训练,并在训练集和测试集(即零样本从文字合成图像)上展示了其性能。除了鸟和花之外,我们还将模型应用于MSCOCO 数据集中更一般的图像和文本描述上。
生成对抗网络(GAN)由发生器 G 和判别器 D 组成,它们在极小化极大算法中竞争:判别器尝试区分将合成图像和真实训练数据区分开来,而生成器试图愚弄判别器。D和G的博弈在V (D,G)上展开:
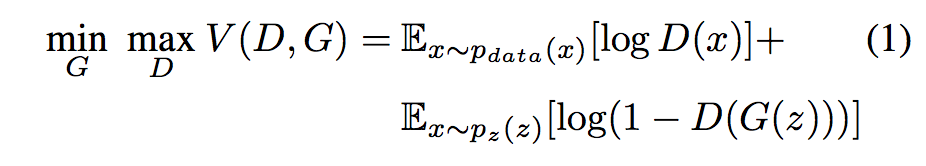
我们的方法是基于由混合字符级卷积循环神经网络编码的文本特征,训练一种深度卷积生成对抗网络(DC-GAN)。

算法1 我们的训练过程
网络架构
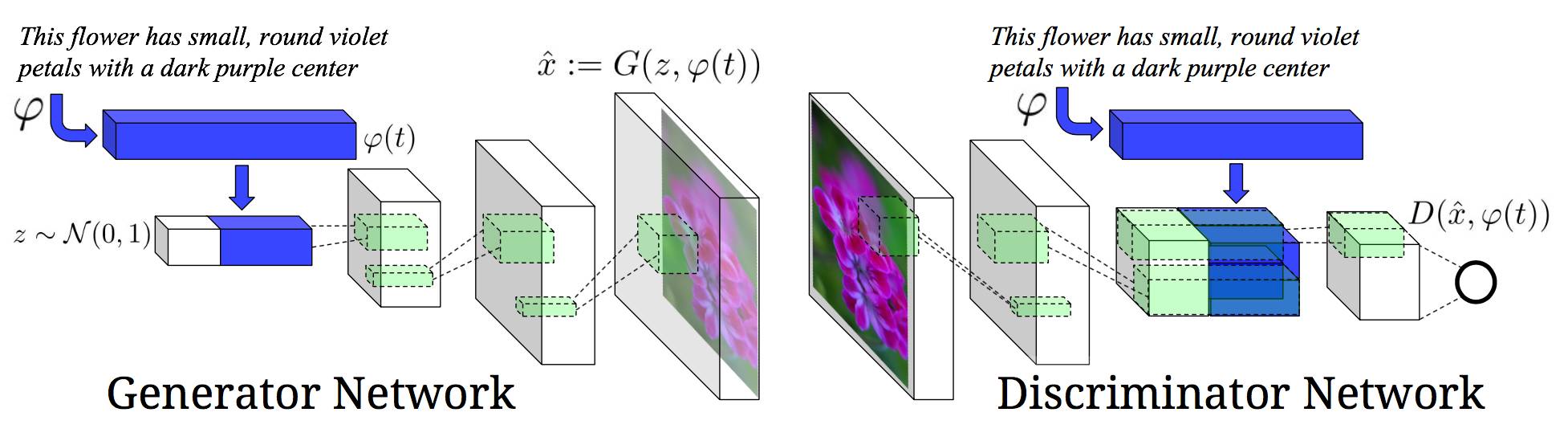
图2:我们的文本-条件卷积GAN架构,文本编码φ(t) 同时用于生成器和鉴别器。
 图3:Zero-shot(来自未知测试集类别的文本)生成的鸟的图像,使用GAN,GAN-CLS,GAN-INT和GAN-INT-CLS。
图3:Zero-shot(来自未知测试集类别的文本)生成的鸟的图像,使用GAN,GAN-CLS,GAN-INT和GAN-INT-CLS。

图4:Zero-shot 生成花的图像,使用GAN,GAN-CLS,GAN-INT和GAN-INT-CLS。所有变量都生成了合理的图像。虽然在训练期间没有展示某些测试类别的形状(例如第3列和第4列),但保留了颜色信息。









