
原文地址:
在 Go 中恰到好处的内存对齐
问题
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
在开始之前,希望你计算一下
Part1
共占用的大小是多少呢?
func main() {
fmt.Printf("bool size: %d\n", unsafe.Sizeof(bool(true)))
fmt.Printf("int32 size: %d\n", unsafe.Sizeof(int32(0)))
fmt.Printf("int8 size: %d\n", unsafe.Sizeof(int8
(0)))
fmt.Printf("int64 size: %d\n", unsafe.Sizeof(int64(0)))
fmt.Printf("byte size: %d\n", unsafe.Sizeof(byte(0)))
fmt.Printf("string size: %d\n", unsafe.Sizeof("EDDYCJY"))
}
输出结果:
bool size: 1
int32 size: 4
int8 size: 1
int64 size: 8
byte size: 1
string size: 16
这么一算,
Part1
这一个结构体的占用内存大小为 1+4+1+8+1 = 15 个字节。相信有的小伙伴是这么算的,看上去也没什么毛病。
真实情况是怎么样的呢?我们实际调用看看,如下:
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
func main() {
part1 := Part1{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
}
输出结果:
part1 size: 32, align: 8
最终输出为占用 32 个字节。这与前面所预期的结果完全不一样。这充分地说明了先前的计算方式是错误的。为什么呢?
在这里要提到 “内存对齐” 这一概念,才能够用正确的姿势去计算,接下来我们详细的讲讲它是什么。
内存对齐
有的小伙伴可能会认为内存读取,就是一个简单的字节数组摆放。

上图表示一个坑一个萝卜的内存读取方式。但实际上 CPU 并不会以一个一个字节去读取和写入内存。相反 CPU 读取内存是
一块一块读取
的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为
内存访问粒度
。如下图:
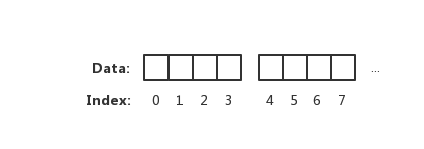
在样例中,假设访问粒度为 4。 CPU 是以每 4 个字节大小的访问粒度去读取和写入内存的。这才是正确的姿势
为什么要关心对齐
另外作为一个工程师,你也很有必要学习这块知识点哦 :)
为什么要做对齐
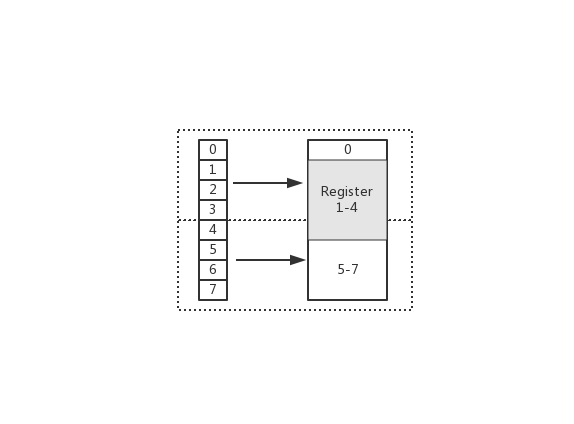
在上图中,假设从 Index 1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。因此 CPU 会做一些额外的处理工作。如下:
-
CPU
首次
读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
-
CPU
再次
读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
-
合并 1-4 字节的数据
-
合并后放入寄存器
从上述流程可得出,不做 “内存对齐” 是一件有点 "麻烦" 的事。因为它会增加许多耗费时间的动作。
而假设做了内存对齐,从 Index 0 开始读取 4 个字节,只需要读取一次,也不需要额外的运算。这显然高效很多,是标准的
空间换时间
做法。
默认系数
在不同平台上的编译器都有自己默认的 “对齐系数”,可通过预编译命令
#pragma
pack
(
n
)
进行变更,n 就是代指 “对齐系数”。一般来讲,我们常用的平台的系数如下:
另外要注意,不同硬件平台占用的大小和对齐值都可能是不一样的。因此本文的值不是唯一的,调试的时候需按本机的实际情况考虑。
成员对齐
func main() {
fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
fmt
.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
}
输出结果:
bool align: 1
int32 align: 4
int8 align: 1
int64 align: 8
byte align: 1
string align: 8
map align: 8
在 Go 中可以调用
unsafe
.
Alignof
来返回相应类型的对齐系数。通过观察输出结果,可得知基本都是
2
^
n
,最大也不会超过 8。这是因为我手提(64 位)编译器默认对齐系数是 8,因此最大值不会超过这个数。
整体对齐
在上小节中,提到了结构体中的成员变量要做字节对齐。那么想当然身为最终结果的结构体,也是需要做字节对齐的。
对齐规则
-
结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为
编译器默认对齐长度
(
#pragma
pack
(
n
)
)或
当前成员变量类型的长度
(
unsafe
.
Sizeof
),取
最小值作为当前类型的对齐值
。其偏移量必须为对齐值的整数倍
-
结构体本身,对齐值必须为
编译器默认对齐长度
(
#pragma
pack
(
n
)
)或
结构体的所有成员变量类型中的最大长度
,取
最大数的最小整数倍
作为对齐值
-
结合以上两点,可得知若
编译器默认对齐长度
(
#pragma
pack
(
n
)
)超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
分析流程
接下来我们一起分析一下,“它” 到底经历了些什么,影响了 “预期” 结果。
|
成员变量
|
类型
|
偏移量
|
自身占用
|
|
a
|
bool
|
0
|
1
|
|
字节对齐
|
无
|
1
|
3
|
|
b
|
int32
|
4
|
4
|
|
c
|
int8
|
8
|
1
|
|
字节对齐
|
无
|
9
|
7
|
|
d
|
int64
|
16
|
8
|
|
e
|
byte
|
24
|
1
|
|
字节对齐
|
无
|
25
|
7
|
|
总占用大小
|
-
|
-
|
32
|
成员对齐
第一个成员 a
-
类型为 bool
-
大小/对齐值为 1 字节
-
初始地址,偏移量为 0。占用了第 1 位
第二个成员 b
第三个成员 c
第四个成员 d
第五个成员 e
整体对齐
在每个成员变量进行对齐后,根据规则 2,整个结构体本身也要进行字节对齐,因为可发现它可能并不是
2
^
n
,不是偶数倍。显然不符合对齐的规则。
根据规则 2,可得出对齐值为 8。现在的偏移量为 25,不是 8 的整倍数。因此确定偏移量为 32。对结构体进行对齐。
结果
Part1 内存布局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
小结
通过本节的分析,可得知先前的 “推算” 为什么错误?
是因为实际内存管理并非 “一个萝卜一个坑” 的思想。而是一块一块。通过空间换时间(效率)的思想来完成这块读取、写入。另外也需要兼顾不同平台的内存操作情况。
巧妙的结构体
在上一小节,可得知根据成员变量的类型不同,其结构体的内存会产生对齐等动作。那假设字段顺序不同,会不会有什么变化呢?我们一起来试试吧 :-)
type Part1 struct {
a bool
b int32
c int8










