谷歌旗下DeepMind研发的阿尔法狗(AlphaGo)刚以“Master”的名义战胜了“当今围棋第一人”柯洁,宣告人工智能针对人类的又一轮胜利,引起轩然大波。紧接着,人工智能在扑克游戏中的捷报似乎又已经发出。
来自加拿大和捷克的几位计算机科学研究者近日在 arXiv 上贴出论文,介绍了一种用于不完美信息(例如扑克)的新算法,DeepStack 结合使用循环推理来处理信息不对称,使用分解将计算集中在相关的决策上,并且使用一种深度学习技术从单人游戏中自动学习的有关扑克任意状态的直觉形式。
研究者在论文中称,在一项有数十名参赛者进行的44000手扑克的比赛中,DeepStack 成为第一个在一对一无限注德州扑克中击败职业扑克玩家的计算机程序。

游戏长久以来都被认为是用来测量人工智能进步的一个基准。在过去的20年间,我们见证了许多游戏程序已经在许多游戏上超越了人类,比如西洋双陆棋、跳棋、国际象棋、Jeopardy 、Atari 电子游戏和围棋。计算机程序在这些方面的成功涉及的都是信息的对称性,也就是对于当下的游戏状态,所有的玩家能够获得的确定性信息是相同的。这种完美信息的属性也是让这些程序取得成功的算法的核心,比如,在游戏中的局部搜索。
现代游戏理论创建者、计算机先锋 von Neumann 曾对无完美信息游戏中的推理行为进行过解释:“现实世界与此不同,现实世界包含有很多赌注、一些欺骗的战术,还涉及你会思考别人会认为你将做什么。” von Neumann 最痴迷的一个游戏是扑克,在这个游戏中,玩家在得到自己的牌后,会轮流下注,让对手跟注,他们或跟注或弃牌。扑克是一种非完美信息游戏,玩家只能根据自己手上的牌提供的非对称的信息来对游戏状态进行评估。
在一对一对战(也就是只有两位玩家)的有限下注德州扑克中,AI 曾经取得了一些成功。但是,一对一有限注的德州扑克,全部的决策点(decision points)只有不到10的14次方个。作为对比,计算机已经在围棋上完胜人类专业棋手,围棋是一个完美信息的游戏,约包含有10的170次方个决策点。
非完美信息游戏要求更复杂的推理能力。在特定时刻的正确决策依赖于对手所透露出来的个人信息的概率分布,这通常会在他们的行动中表现出来。但是, 对手的行为如何暗示他的信息,反过来也要取决于他对我们的私人信息有多少了解,我们的行为已经透露了多少信息。这种循环性的推理正是为什么一个人很难孤立地推理出游戏的状态,不过在完美信息游戏中,这是局部搜索方法的核心。
在非完美信息游戏中,比较有竞争力的AI 方法通常是对整个游戏进行推理,然后得出一个完整的优先策略。CFR ( Counterfactual regret minimization)是其中一种战术,使用自我博弈来进行循环推理,也就是在多次成功的循环中,通过采用自己的策略来对抗自己。如果游戏过大,难以直接解决,常见的方法是先解决更小的、浓缩型的游戏。最后,如果要玩最初的大型的游戏,需要把原始版本的游戏中设计的模拟和行为进行转移,到一个更“浓缩”的游戏中完成。
虽然这一方法让计算机在 HUNL 一类的游戏中进行推理变得可行,但是,它是通过把HUNL下的10的160次方个场景压缩到10的14次方缩略场景的来实现的。这种方法有很大的可能性会丢失信息,所有这类的程序离专业的人类玩家水平还差得很远。
2015年,计算机程序 Claudico 输给了一个专业扑克玩家团队,并且是以较大的劣势输掉的比赛。此外,最近,在年度计算机扑克竞赛中,人们发现,基于“浓缩”的计算机程序有着大量的缺点。其中4个使用了这一方法的计算机程序,其中包括从2016年来一直位列前茅的程序,被认为使用了一个局部最佳响应的技巧,使得在一个策略能输掉多少这一决策上,产生一个更加接近下限的答案。所有这四个基于“浓缩”方法的程序都可能会输得很惨,用量化来表示,是每局都弃牌所属的四倍。
DeepStack 采用了一个完全不同的方法。它持续地使用CFR中的循环推理来处理信息不对称的问题。但是,它并不会计算和存储一个完整的优先策略用于博弈,所以也不需要进行简要的提炼(浓缩)。反之,在游戏中,它会在每一个具体的场景出现时就进行考虑, 但是并不是独立的。
通过使用一个快速的近似估计来代替某一种深度的计算,它能避免对整个游戏的剩余部分进行推理。这种估计可以被看成是 DeepStack 的直觉:在任何可能的扑克情境下,持有任何可能的个人牌的牌面大小的直觉。
最终,从某种程度上来说与人类的很像的 DeepStack 的直觉,是需要被训练的。我们使用了随机生成的扑克情景用深度学习进行训练。最终,我们证明了,DeepStack从理论上来说是可行的,比起基于“浓缩”的方法,它能产生从实质上需要更少地探索的策略,同时,它也是世界上首个在HUNL游戏中击败人类专业玩家的计算机程序,平均赢率超过450 mbb/g。(mbb/g,milli-big-blinds per game ,是用于衡量扑克玩家表现的指数,50 mbb/g 可以就认为是一个较大的优势,750mbb/g 就是对手每局都弃牌的赢率。)
跟职业选手对抗结果
为了把 DeepStack 跟人类专家相比较,我们雇用了国际扑克联盟(International Federation of Poker)里的专业扑克选手。选手们在4周中完成3000局比赛。为了激励选手,给排名最高的前三(以AIVAT计)分别予以 5000加元、2500加元和1250加元的奖励。比赛在2016年11月7日和12月12日之间在线上举行,扑克选手可以选择最多同时玩4局,这在线上很常见。总共有来自17个国家的33名选手跟 DeepStack 进行了较量。DeepStack 跟每个人比赛的表现如表 1:
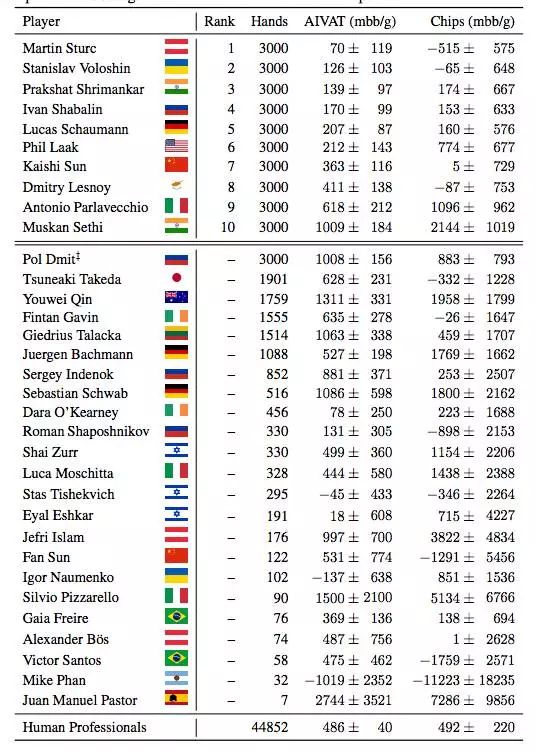
表 1:跟职业扑克选手较量结果,以 AIVAT 和所赢得的筹码进行衡量,以 mbb/g 为单位。

表 2:向前分解根据在哪一轮而具体分析。F, C, 1/2P, P ,2P 和 A 分别是如下的缩写:弃牌(Fold),跟进(Call),二分之一底池押注(half of a pot-sized bet),底池押注(a pot-sized bet),双倍底池押注(twice a pot-sized bet)以及全注(All in)。最后一列表示当超过深度限制的时候用到了哪个神经网络:flop 网络, turn 网络,或者辅助网络。
比赛速度
分解计算和神经网络评估在一个 GPU 上实现。这使得它可以一次快速批量调用反事实价值网络上多个子公共树。这是让 DeepStack 变快的关键。在 Torch7 中开发,在 NVIDIA GeForce GTX 1080 显卡上运行。很多以上的实现手段都是为了让 DeepStack 快速运行,理想上是像人打牌一样快。表 3 展示了 DeepStack 和人类在前一步骤的之后和提交下一个步骤之前的平均间隔时间。平均看来,DeepStack 比起人类选手快很多。不过我们要记住人类选手同时可以进行4局比赛(虽然很少有人同时进行两局以上),所以当轮到人类选手比赛时,它可能正在另外一盘比赛上。
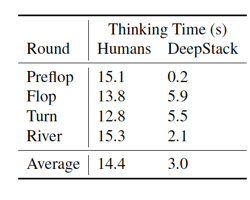
表 3: 人类和 DeepStack 的思考时间,DeepStack 在第一轮叫注(Pre-flop)平均时间超级快,这表明第一轮叫注时的状态通常能命中缓存。
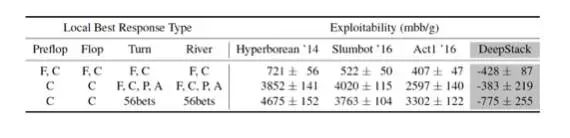
表 4: 不同程序使用局部最佳反馈(LBR:local best response)的最低程度。LBR 仅仅评估每一轮在下表中所列出的动作。F, C, 1/2P, P ,2P 和 A 缩写意义同上。
最佳反馈估值(Best-response Values) vs 自玩估值(Self-play Values)
DeepStack 在持续分解计算中采用自玩估值而非最佳反馈估值。之前的预测试用 CFR-D 解决更小的比赛,这表明自玩估值产生的策略通常攻击性更小,与最佳反馈估值产生的策略相比,在和测试智能代理一对一的表现更好。图 5 展示了一个例子,关于 DeepStack在特定第五张牌的博弈中有着不同数字的分解迭代的攻击性。除了缺少对它稳固性的理论评价,用自玩估值看上去就像最佳反馈估值一样最终收敛至低攻击性策略。

图 5:DeepStack 在第五张牌开始前特定公共状态下的攻击性和分解迭代数量之间的方程。
DeepStack 是一大类的序列不完美信息博弈的通用算法。我们将解释 DeepStack 在 HUNL(heads-up no-limit,一对一无限注)德州扑克中的作用。
扑克游戏的状态可以分为玩家的私人信息,即两张牌面朝下的手牌,以及公共状态,包括牌面朝上的公共牌和玩家的下注顺序。游戏中公共状态的可能序列形成公共树,每个公共状态有一个相关联的子公共树。见下图6:

图6:HUNL公共树的一部分。红色和湖蓝色代表玩家的动作。绿色代表被翻开的公共牌。
DeepStack 算法试图计算玩游戏的低利用率策略,即,求解一个近似的纳什均衡(Nash equilibrium)。DeepStack在玩牌期间计算这个策略,公共树的状态如图7所示。这种本地的计算使得 DeepStack 在对现有算法来说规模太大的游戏中可推理,因为需要抽象出的游戏的10的160次方决策点下降到10的14次方,这让算法变得易处理。
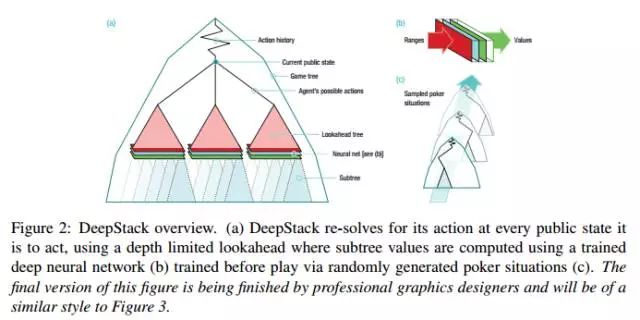
图7:DeepStack 概览图。(a)DeepStack 对在每个公共状态的动作进行 re-solves,使用 depth-limited lookahead,其中子树值的计算用训练好的深度神经网络(b)通过随机生成的扑克状态在玩牌前进行训练(c)最终状态如图3.
DeepStack 算法由三个部分组成:针对当前公共状态的本地策略计算(local strategy computation),使用任意扑克状态的学习价值函数的 depth-limited lookahead,以及预测动作的受限集合。
连续 Re-Solving
Limited Lookahead 和 Sparse Trees
连续re-solving在理论上是可行的,但实际使用上不现实。它没有维持一个完整的策略,除非游戏接近结束,re-solving本身就很棘手。例如,对于第一次动作的re-solving需要为整个游戏临时计算近似解决方案。
Deep Counterfactual Value Networks
深度神经网络(DNN)已被证明在图像和语音识别、自动生成音乐以及玩游戏等任务上是强有力的模型。DeepStack 使用DNN和定制的架构作为它的 depth-limited lookahead其的价值函数。如图8。训练两个独立的网络:一个在第一次三张公共牌被处理(flop网络)后估计反事实值,另一个在处理第四张公共牌(turn网络)后估计反事实值。一个辅助网络用于在发任意公共牌之前加速对前面的动作的re-solving。

图8:Deep Counterfactual Value Networks。网络的输入是pot的大小,公共牌和玩家范围,玩家范围先被处理为bucket ranges。输出来自七个完全连接的隐藏层,被后处理以保证值满足零和限制(zero-sum constraint)。
被称为“人脑 vs 人工智能:跟不跟 ” 的赛事将于1月11日在匹兹堡的 Rivers 赌场启幕。比赛期间,职业扑克手 Jason Les, Dong Kim, Daniel McAulay 和 Jimmy Chou 将在20天的时间和 CMU 计算机程序玩120000手一对一不限注的德州扑克。
CMU的人工智能系统名叫 Libratus ,相比去年失败的 Claudico,其终于策略发生了改变。 Libratus 会用 Bridges 计算机实时计算新的终局解决方法和算法,而不是像 Claudico 那么依赖终局。
另外,Claudico 常用的策略是 limping,这是一个扑克术语,指跟注混进去看看,而不是加注或者放弃。而 Libratus 偶尔也会这样。
可以看到,和上文中提到的 DeepStack一样,他们希望攻克的也是一对一(两个选手)不限注的的德州扑克难题,这是一个极度复杂的游戏,有10的160次方信息集——每个集合都根据出牌方的理解有不同的路径。这个巨大的信息集比整个宇宙的原子数还多。
而综合两个机构的介绍,其使用的方法也有相似性,即采用实时计算。CMU的比赛于11日举行,而这边论文已经发布在arXiv上,看起来,CMU又被截胡了。
来源:arXiv,翻译:弗格森 刘小芹 序媛,新智元(ID:AI_era)编译

·
END·

专注互联网、移动互联网、O2O、电商、P2P领域。
提供深入独到趋势分析、干货、观察。
搜索公众账号“
hlwgcw
”关注






