概念:
虽然筛选器始终在选择中应用 AND 运算符,但集可以在选择中应用 OR 运算符。
数据源:
Normalized London House Price Data(1995-2018)
情景:
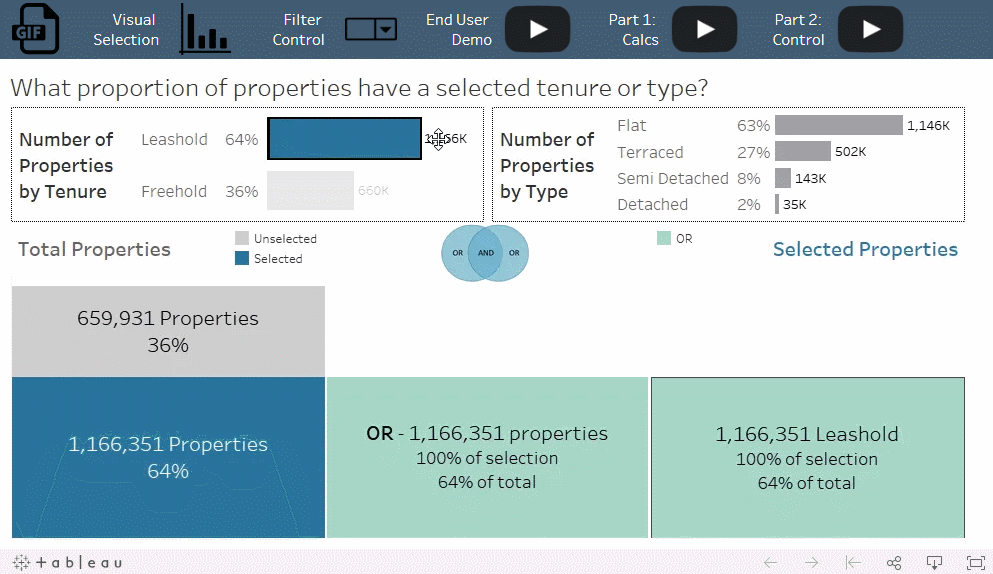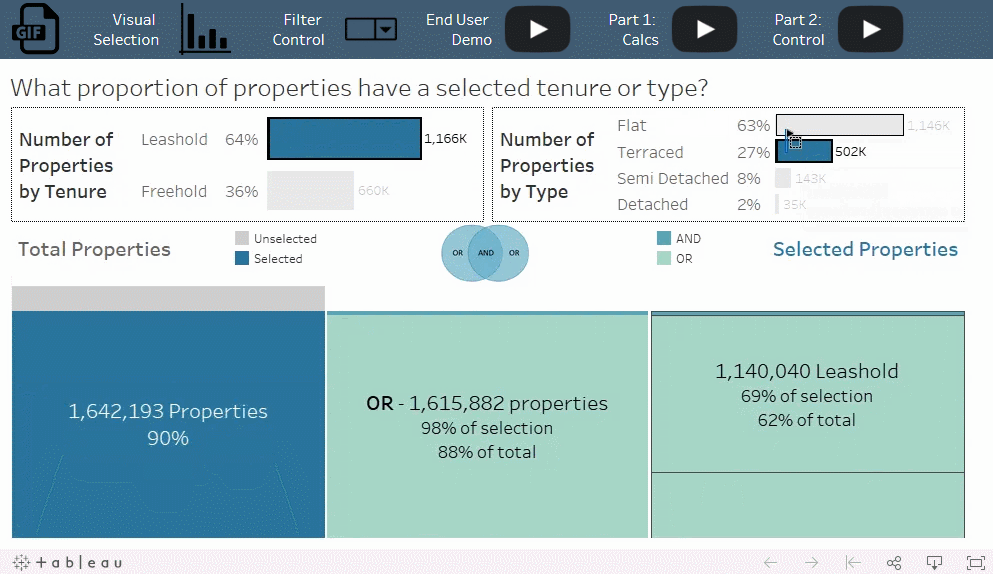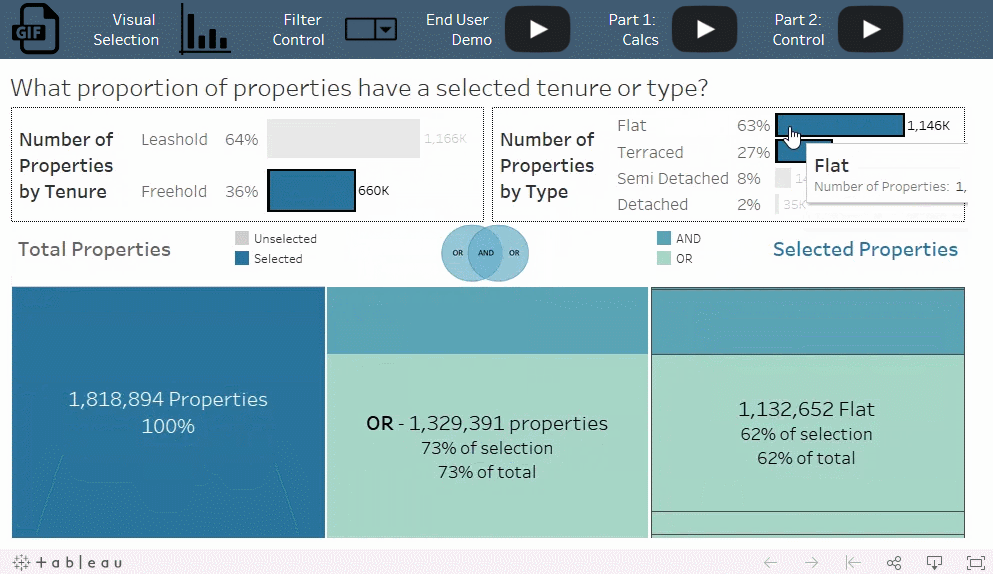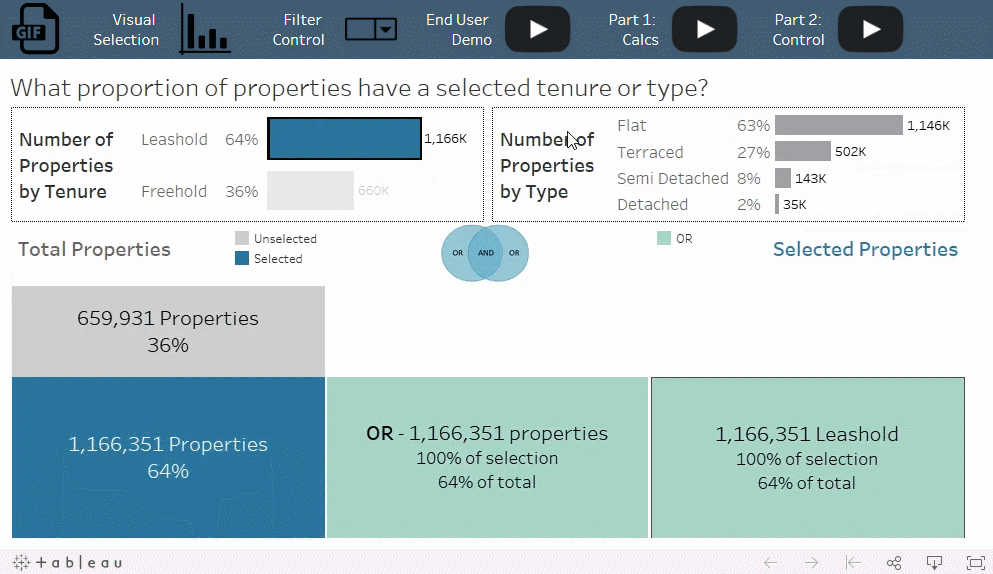
数据中的房产按照土地所有权分类或按照房产类型分类的比例是多少?在只符合一个分类标准的房产中,符合土地所有权分类标准的百分比和符合房产类型标准的百分比又是各多少?
解读:
OR 条件与总计算的百分比相结合,使您可以分析选择标准的重叠部分。例如, freehold 和 terraced 之间存在很大的重叠部分,而 freehold 和 flat 之间几乎没有重叠部分,尽管几乎所有的房产都符合这两个标准中的其中一个。
值得注意的是:
添加筛选器总是会减少记录数,但添加带 OR 条件的集会增加结果集中的记录数。
概念:
数据通常是在严格的层次结构中构建的,而分析则需要将不同层次的细节合并到一个字段中。例如,销售经理常常想知道团队中个人配额与其他团队平均配额相比较的情况。
数据源:
Market Value of Players and Teams in the 2018 World Cup
情景:
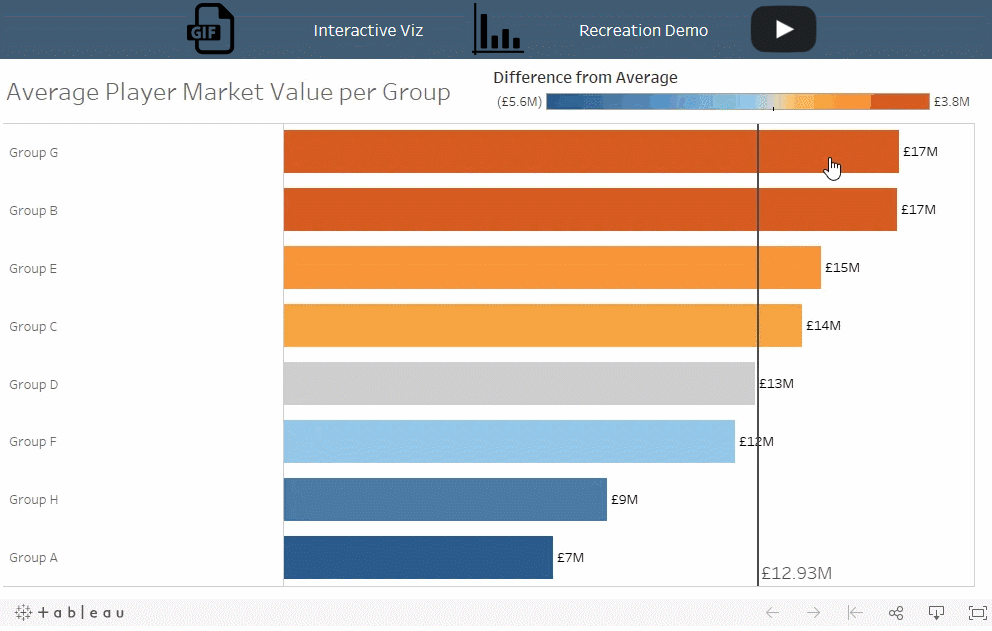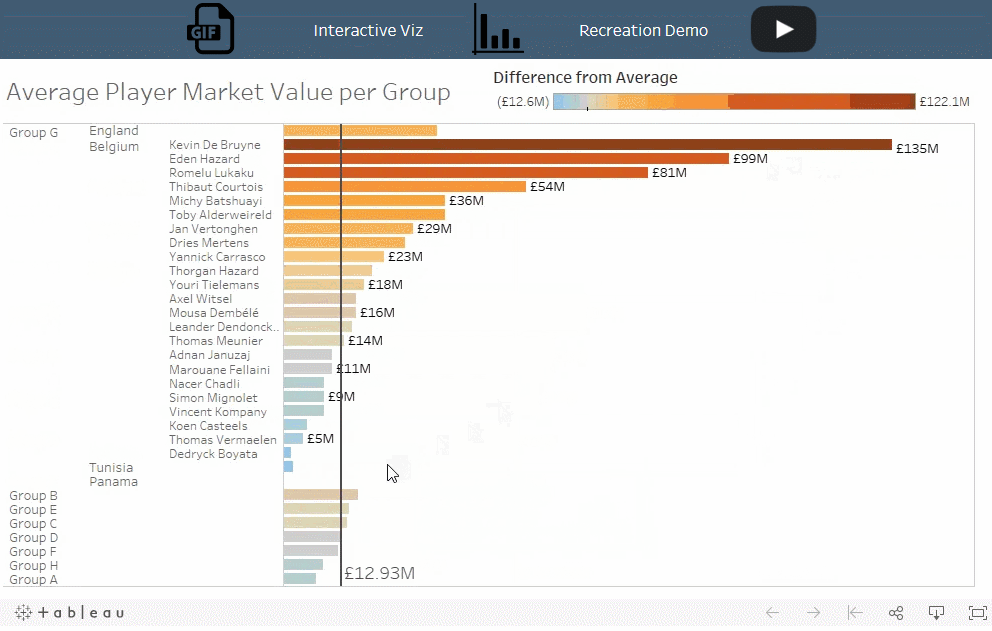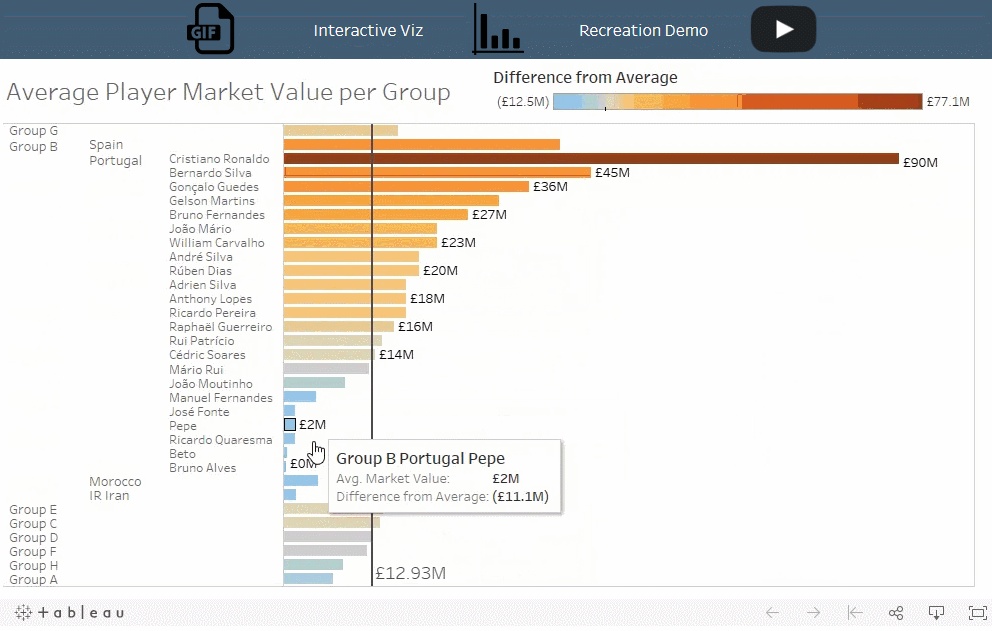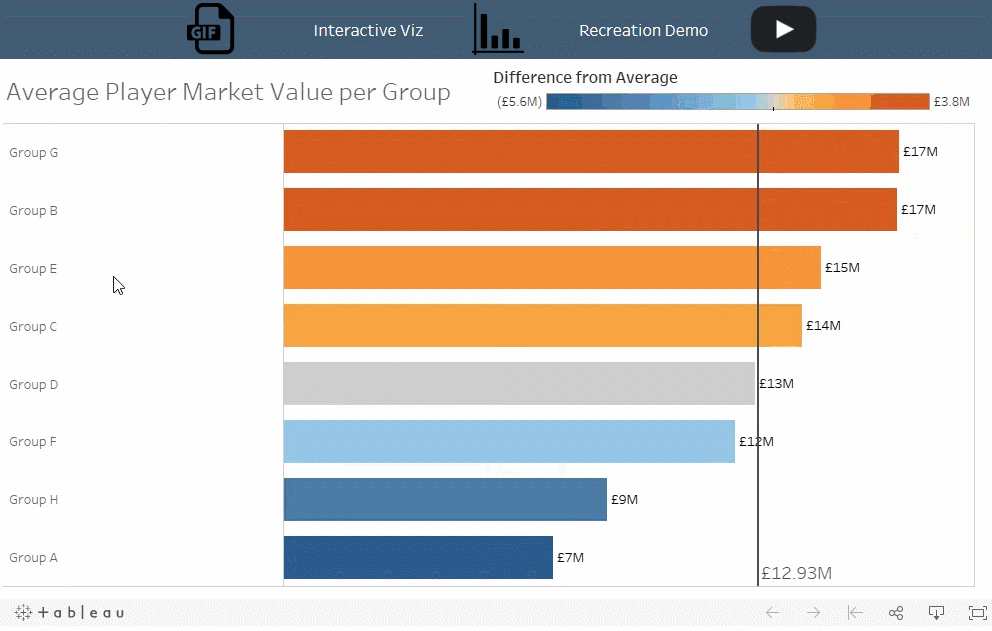
对于选定的小组,各个球队的平均球员市场价值是多少?这与其他小组的平均值相比如何?
解读:德国的平均球员市场价值高于所有其他小组的平均值,而其他球队 - 瑞典,墨西哥和韩国 - 均低于所有小组的平均值。墨西哥和瑞典在第 16 轮击败德国的比赛中表现出色!
值得注意的是:
这个技术允许您同时将组内的方差与组之间的方差进行比较。
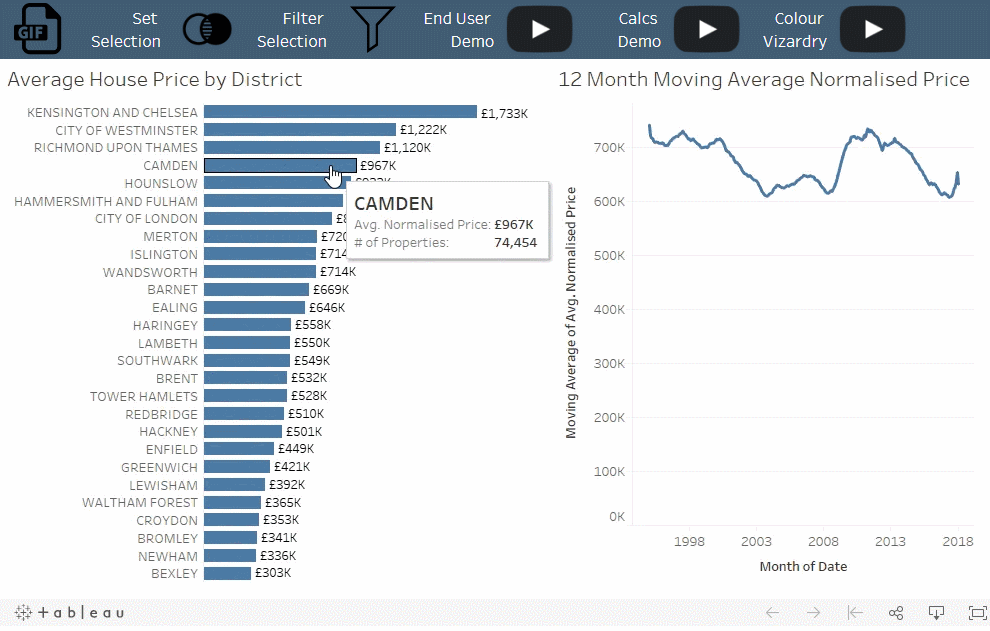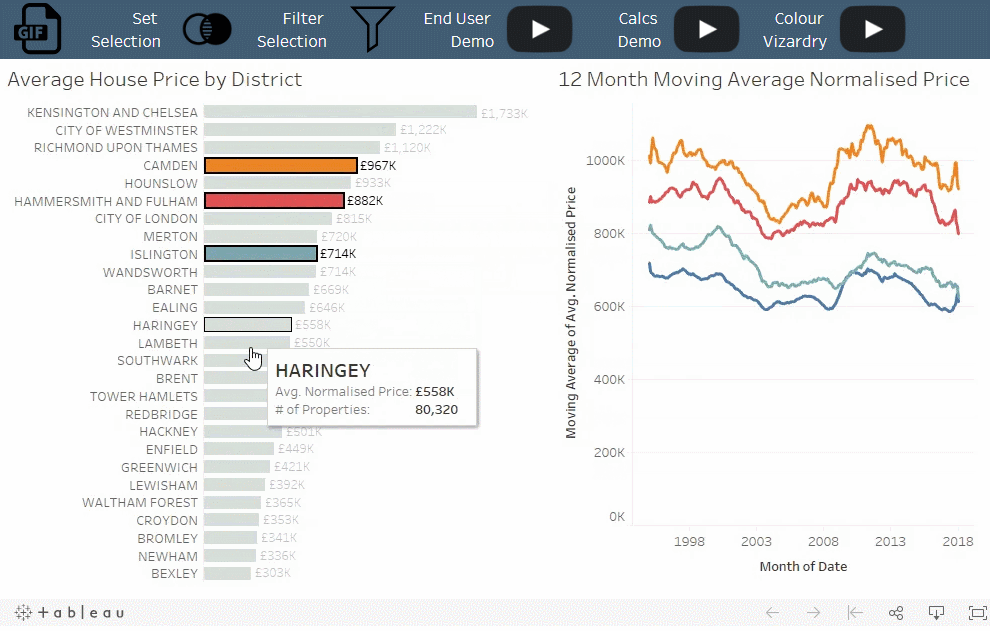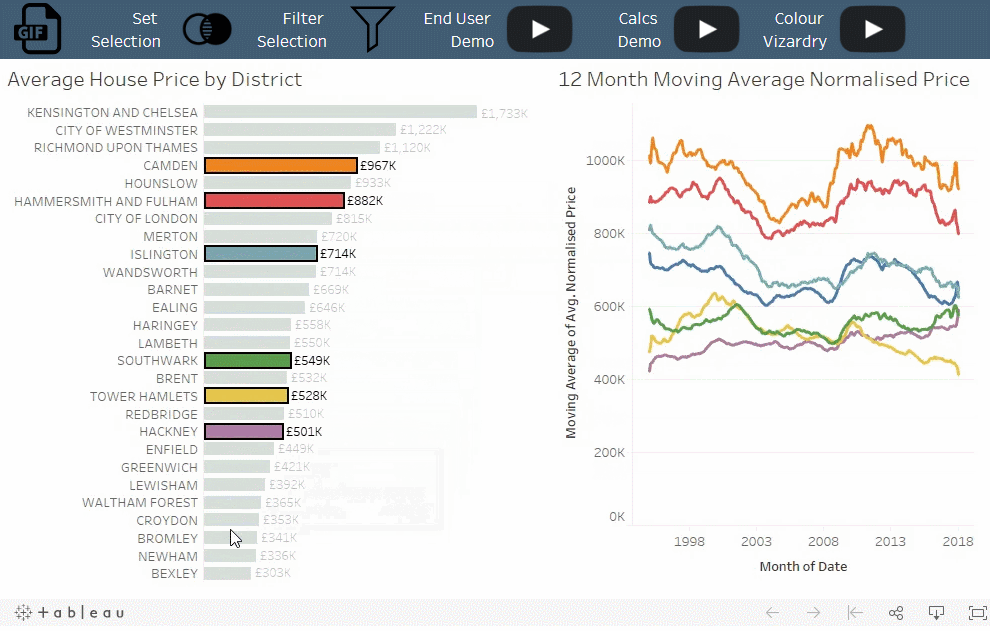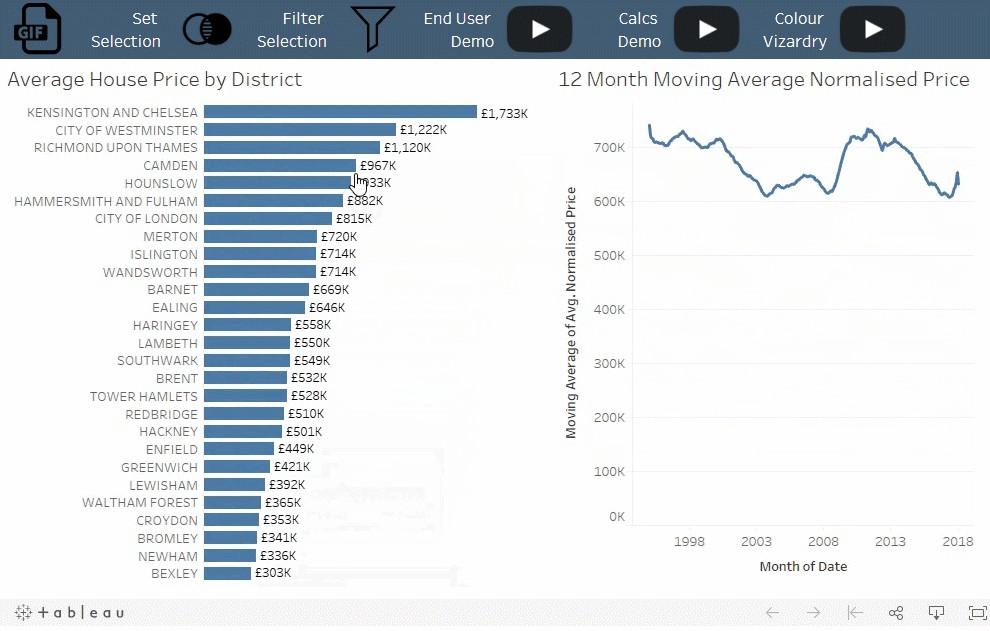
概念:
当筛选器移除未选择的类别时,集可以将未选择的类别分组为“其他”。
数据源:
Normalised London House Price Data(1995-2018)
情景:
选定地区的房价趋势与所有其他地区的平均房价趋势的比较。
解读:
每次选择某一区域时,它都会从“其他”类别中移除。
值得注意的是:
使用筛选器时,清除选择会为每个类别显示单独的时间序列。使用集合,清除选择将显示汇总数据。当选择中具有大量类别时,该技术特别有用。
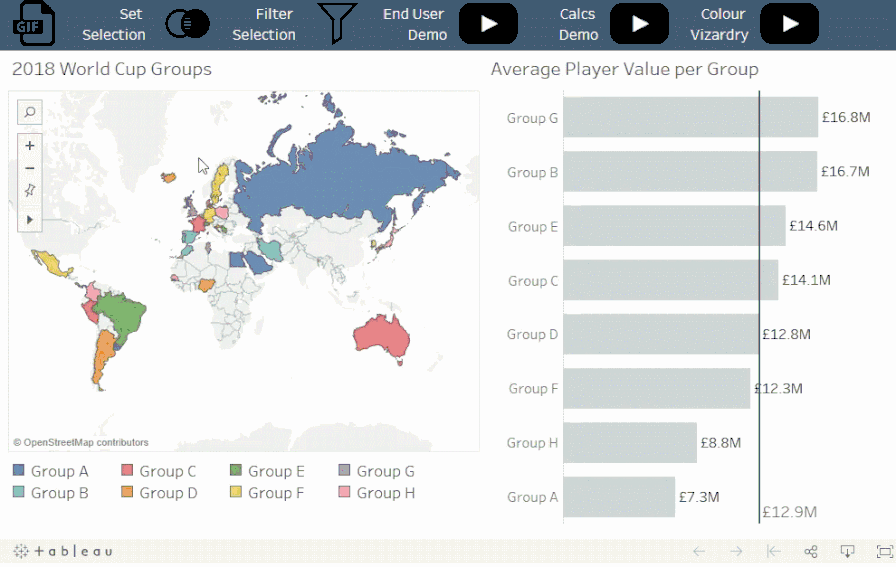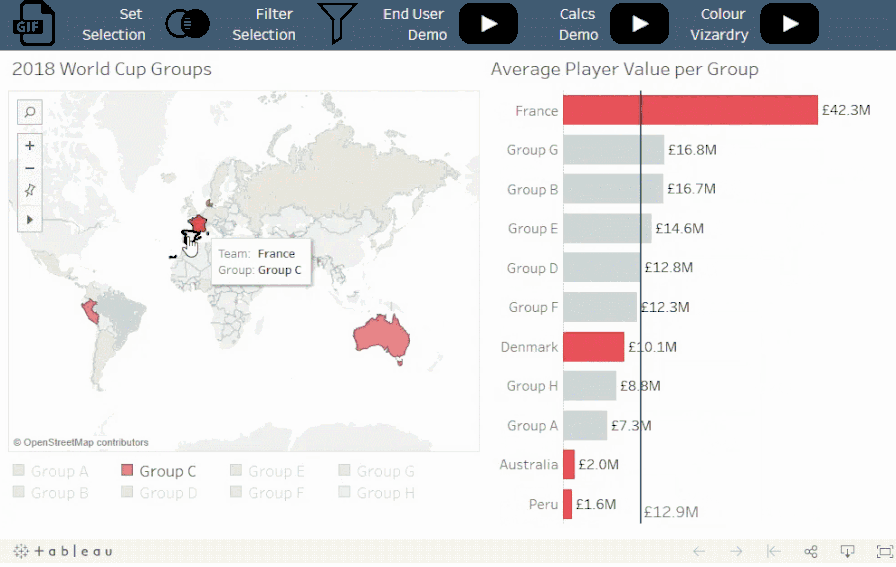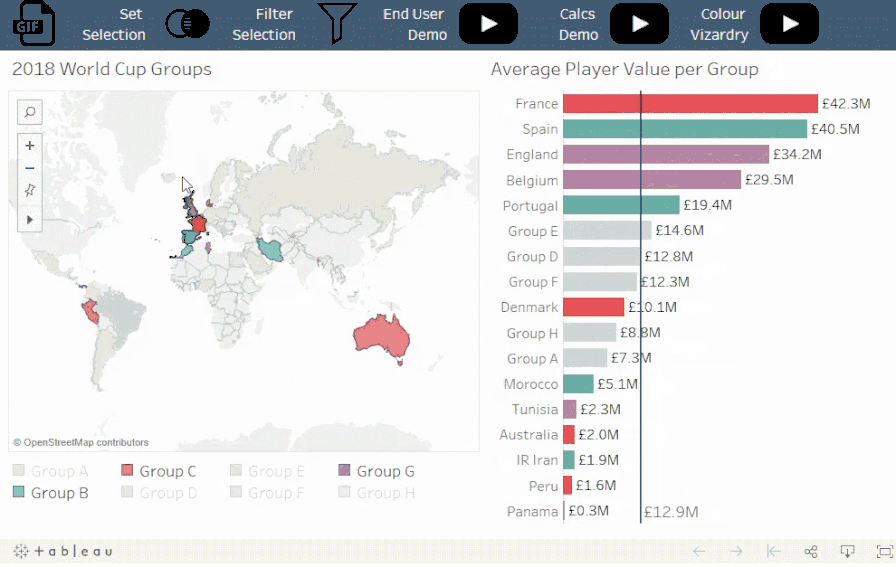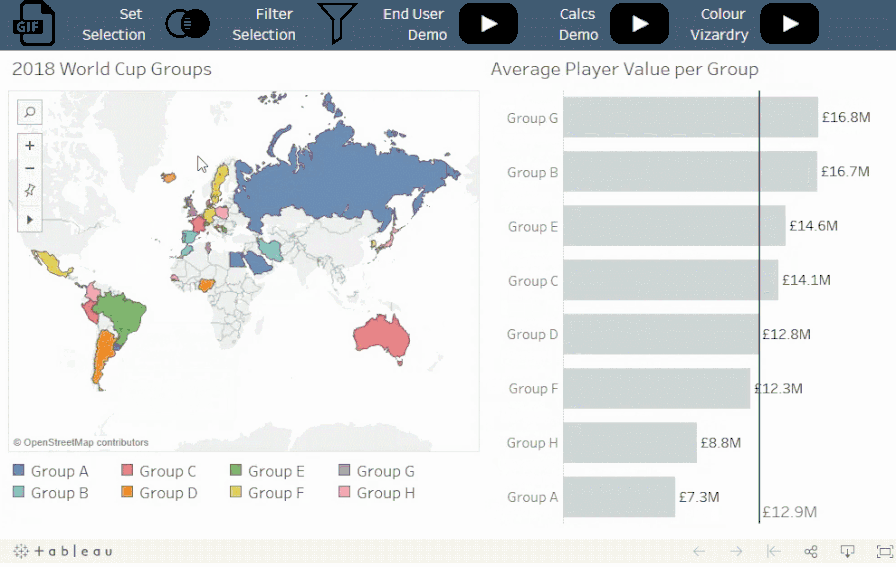
概念:
扩展类别子集使您可以在单个比例上对不同级别的详细信息进行比较。
数据源:
Market Value of Players and Teams in the 2018 World Cup
情景:
Viz 展示了在选定小组中的某个球队或具体运动员的平均球员市场价值与其他小组的平均值相比的情况。
值得注意的是:
比率在不同的层次结构上是可比较的,而大小和数量通常不可以。例如,将个人的价值与团队的总价值进行比较的情况并不常见,除非需要强调特殊的个人。例如,梅西的市场价值高于整个俄罗斯队的市场价值。使用此技术时,请务必考虑要测量的类型和分析的意图。
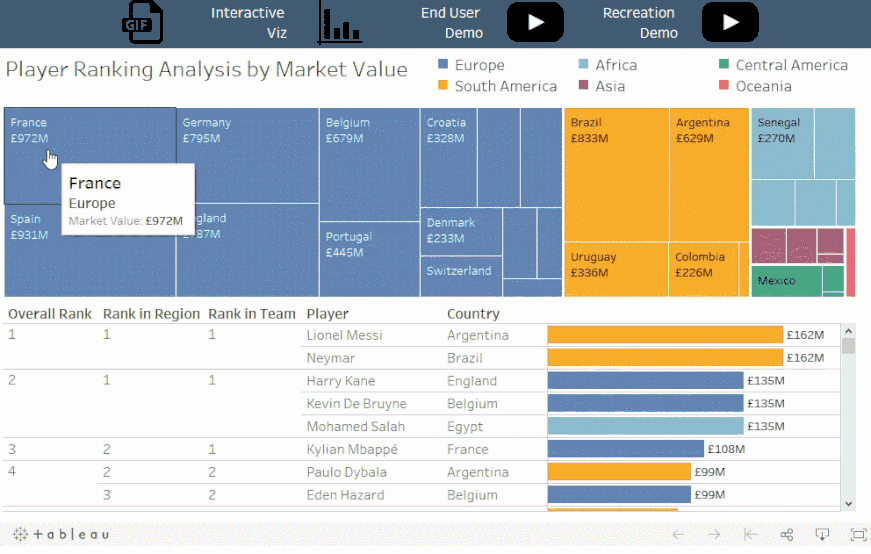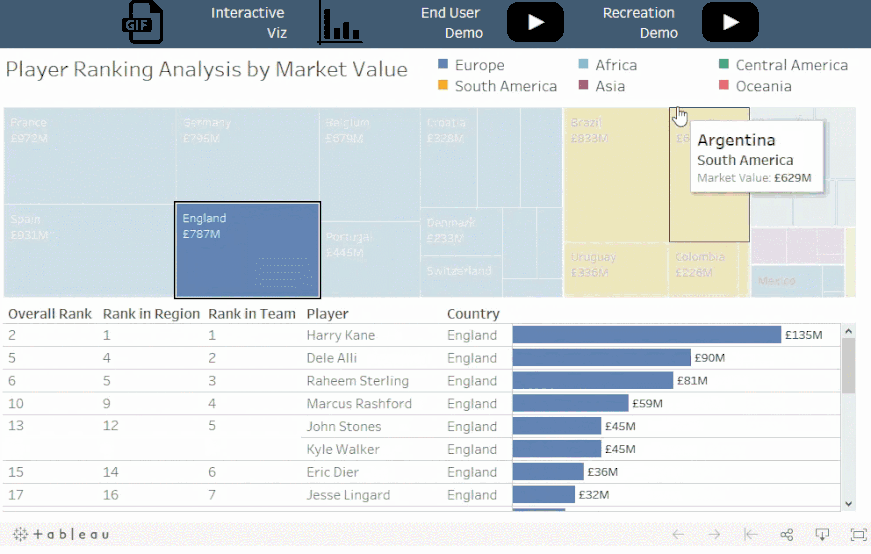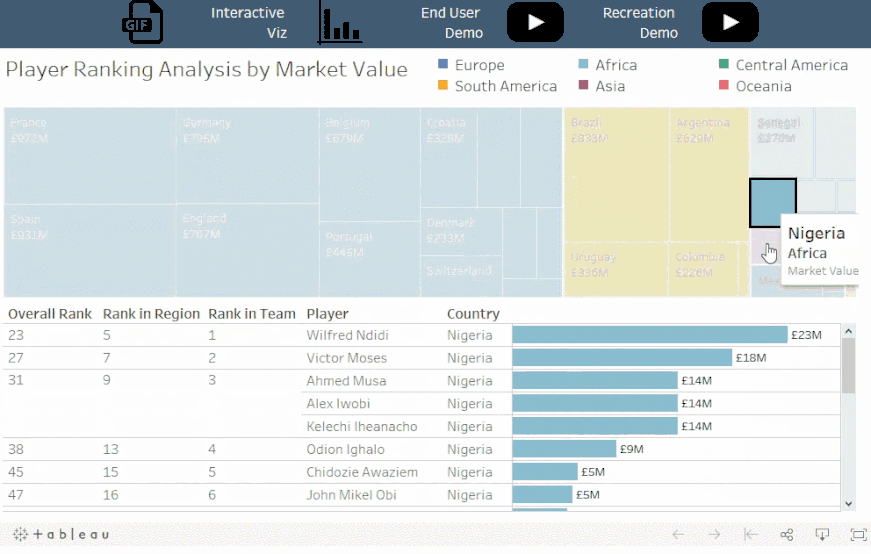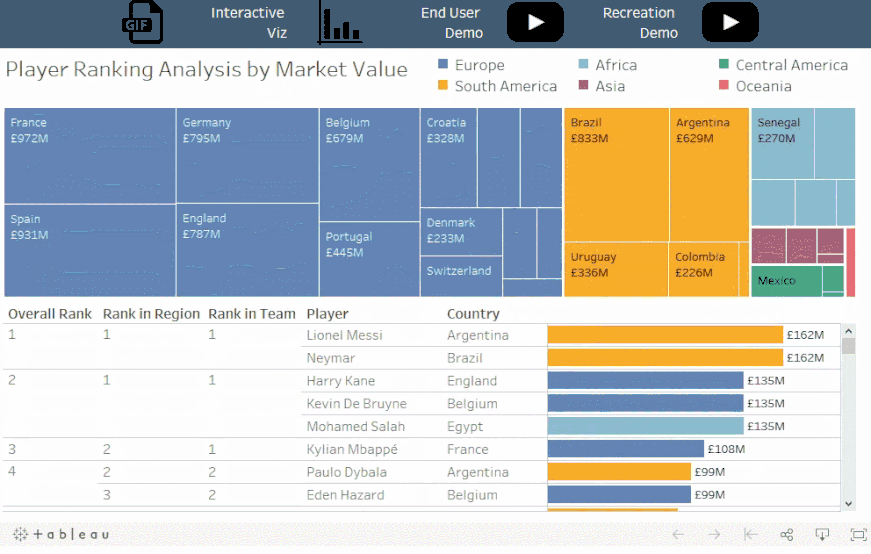
概念:
像排序函数之类的表计算总是在筛选器之后应用,但在某些情况下,您可能希望在筛选之前进行表计算。
数据源:
Market Value of Players and Teams in the 2018 World Cup
情景:
对于选定的国家,每个球员在其球队内,地区,和世界上的排名各是如何?
解读:
梅西在阿根廷,南美和全球都排名第一。哈里凯恩在英格兰排名第一,在欧洲排名第一,但在全球排名第二。而姆巴佩在法国排名第一,在欧洲排名第二,在全球排名第三。
值得注意的是:
这里并没有对所选的队伍进行筛选,而是对所有数据排序并隐藏不在集合中的国家。这可以确保 Viz 是根据所有数据所计算的排名,而不仅仅是筛选后的可见数据。