
近年来,在中文媒体世界里,新闻客户端较劲比拼谁能在第一时间抓取博人眼球的头条,自媒体和大 V 们争相对热点事件输出观点。一开始我们确实欣喜于接触到更「多元」的信息,但随着时间增长,不少人开始反思和怀疑,我们是否因为某些原因而被动接受了过于同质化的信息,并且在长期影响下
被
塑造了价值观,
被
降低了批判思考的能力?
这个时候我们才猛然惊醒:
表面上来自不同渠道的信息不必然保证信息的多元化,甚至可能让人误以为占「多数」的声音更为接近事实真相或真理
。
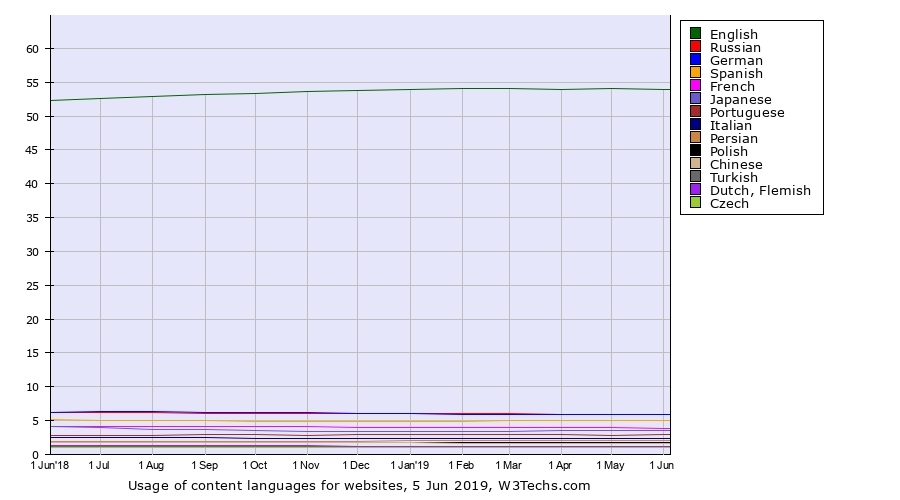
但是,当这群「意识觉醒」的人开始主动向外探寻真正不同的声音时,很快发现自己并没有在多元观点的冲击下迅速具备理性思辨的能力,反而更加茫然,更加不知道该坚持什么样的立场。这并不全是个人原因。根据 W3Techs 的统计,在全球访问量前 1000 万的网站中,中文内容语言只占 1.6%,排名第一的英文却足足占到 54%,更遑论部分中文网站尚且无法访问。长期接收少而单一的信息渠道所传输的内容,必然会影响我们甄别观点、筛选信息的能力。
互联网时代的信息量已经在淹没我们,而很快还会有数量更庞大、形式更多样、内容更难甄别的信息以更快的速率呼啸而来。如果你不想迷失在汪洋里,如果你想将信息爆炸转变为自己乘风破浪的利器,那么你必须
懂得如何选择合适的搜索路径,并对庞杂的信息进行筛选和精简,能够将有效的信息整合重构,最后完成「输入-内化-输出」的完整过程
。否则,自己以往的知识体系和秉持的观念只能不断接受被动的冲击而摇摇欲坠,提升眼界和格局将变得更加漫长而艰难。
(本文为燎原学院「学习没有方法」系列之三「如何管理好信息」的回顾文章,建议各位燎原学员搭配视频回顾阅读本文。)
◇◆◇
搜索:如何找到你不知道的信息
大多数时候我们都需要进行「搜索」以获取更详实的信息,而选择中文搜索引擎或常见的资讯 APP 在一般情况下并不严重影响我们对某个话题的实时了解
(所谓的「一般情况」是指这个话题的发生时间较近,大多数相关信息具备比较充分的透明度和讨论度,且客观事实有较高的可得性,因而通过多样化的渠道可以很好地避免片面性)
。但当你想要或需要对非一般性的话题(如某个争议性事件、某个重大历史事件、某个抽象概念)进行更深入了解时,选择合适的信息检索渠道就变得尤为重要。
这是因为信息检索有一个悖论:
你几乎无法主动搜索你不知道的信息
。举个例子,如果我从来不知道历史是可以且可能被扭曲的,我如何去搜索「distorting history」这个关键词呢?但一旦我知道了这个事情,相关概念如 historical negationism(历史否定主义)就非常容易在关联页面中找到。更 tricky 的是,如果我搜索「historical negationism examples」,我可以很容易了解到相关史实,进而再度扩展知识边界;但反过来,我在不知道这个概念的情况下先去搜索某个事件,如 Holocaust denial(否认大屠杀),可能得浏览不少网页并对其仔细筛选甄别,才能知道此话题下更深入的讨论处于哪个层面,而了解更深入的讨论如何进行对我们提升知识水平和分析能力更有益。
(如果你对例子感兴趣,可阅读
《这场时间之旅还请继续》
。)
如果你感到自己大多数时候处于后者,即对于不怎么熟悉的话题常常停留在「只能找到流于表象的信息」的阶段,那么这个时候你就需要知道
如何主动找到更有深度的信息
。
在第一阶段,放弃零门槛的搜索引擎,转向高质量信息密集度和广度更高的学术网站
,如维基百科(en.wikipedia.org)、谷歌学术(scholar.google.com)、JSTOR(一个学术期刊在线收集系统,www.jstor.org)。希望各位抛掉「只有做学术才需要看学术文章」的刻板印象,因为在这三个网站你可以很容易地搜索到话题相关的深度信息。之所以优先使用这三个网站作为了解话题的第一步,是因为我们在初期就可以通过客观且多角度的研究大致勾勒出这个话题的宏观图景,从而避免被良莠不齐、夹带私货严重却无法判断的个人网站带到「沟」里。
如果有看学术文章的新手,也请不用过于担心语言和专业性会对自己的理解造成严重障碍。牢记我们的目的是了解话题的大图景,所以我们的信息处理量完全可以浓缩为「
标题+目录或摘要(abstract)」
。而使用谷歌学术和 JSTOR 时,「
引用量
」也是一个非常好的参考标准,可以优先浏览那些建设性比较高的内容。至于语言问题,各位可以善用谷歌浏览器的自动翻译功能。而对于不方便获取电子版的书籍和文章,可以参考下图所示途径:直接谷歌「文章标题 pdf」,或前往图中的几个网站查找资源。
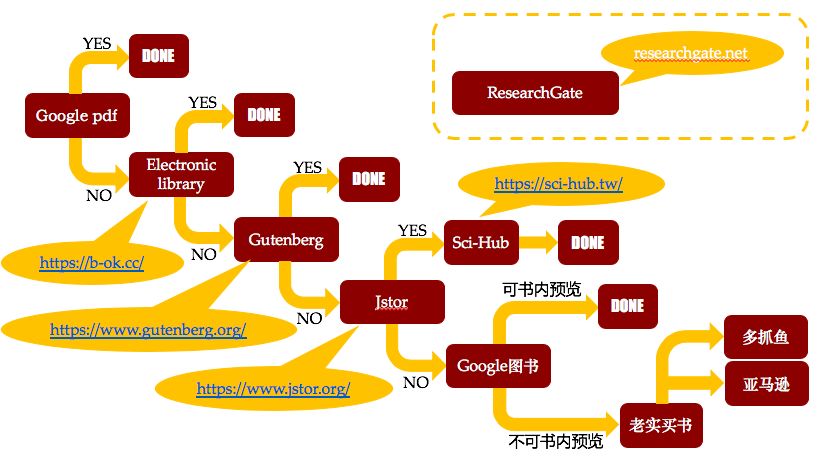
(图为分享人林丹琦的独门信息搜索秘籍「蜈蚣图」)
在第二阶段,
找到大图景下自己感兴趣的切入点,谷歌关键词,以点带面
。由于这个阶段的关键词对话题进行了更精准且深入的定位,搜索引擎显示的结果可以筛选掉大量低质内容,而内容的语言难度和专业性都有所降低,会出现社论、问答、视频等更丰富的形式,可读性大大提高。
◇◆◇
精简:有目的地断舍离
按照上述方法,信息的质量的确得到了很大程度的优化,但是信息数量仍然是绕不过去的一个「坎」——高质量的信息太多了。如果我们的目的不是停留在「看」更多的信息,而是
利用有质量的信息对自己已有的观点和知识体系进行修正或补充
,那必须对获取到的信息进行筛选和甄别,挑选出最有利于我们达到这一目的的内容。
信息量由三个维度构成:数量、内容复杂度和实际偏离度。前两个比较容易理解,数量越多、单位信息的复杂程度越高,必然导致信息量越大。而
实际偏离度
是
指以为
可以用到
的信息量和最终
实际
用到的信息量之差
——自己囤积了大量「可能派得上用场」和「有趣」的信息,而最终只使用到了其中很小一部分。
那么思路就变得非常清晰:只要在三个维度上对信息进行合理压缩,就可以获得少而精的信息。
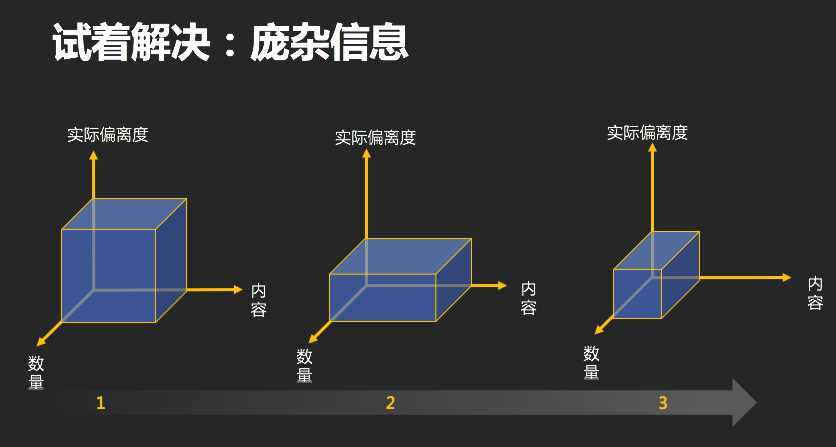
(图为分享人戴雨晴的信息精简三维示意图)
为什么大量优质且多元的信息最终难逃「收藏夹宿命」?有人可能因为被信息量吓倒了,不知从何处看起;有人可能因为时间和能力有限,无法在短期内掌握全部信息,挑战知识边界的不适感逐渐让人丧失了学习的动力。这些现象背后的根源都在于
目标模糊
,也就是需求不明确。因为不知道自己要什么,想要达到什么,所以很容易变得像一个莫得感情的信息抓取机器,信息过眼不过脑。
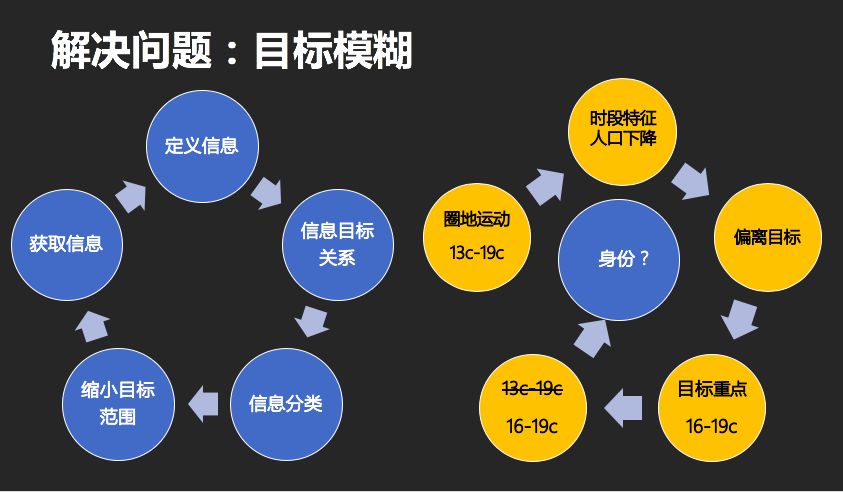
(图为分享人戴雨晴的「目标导向五步曲」)
而目标模糊的问题也很好解决。在获取信息和定义信息两个阶段,也就是上一部分阐述的搜索阶段,我们从对话题知之甚少到图景越来越清晰,这个过程中我们想要继续延伸的切入点是一定会出现的,或者出于自己的兴趣,或者出于某个任务的要求。此时,我们就需要思考已有的信息和目标之间的关系:
明确关系之后,再对已有的信息进行分类。分类标准因需求而异,比如有人可能按照目标相关性分类,有人可能按照具体的话题分类,有人可能按照学科分类,等等。分类之后,我们会进入新一轮的信息搜索,沿着更确切的方向去扩充主线。切记只纳入最需要的信息,先暂时放弃或搁置相关性低的信息,这样我们基本上可以避免沦陷在标签页「密集恐惧」里。
◇◆◇
体系化:搭建个人的信息体系
在前面的两个阶段,我们通过检索和精简信息使自己对某个话题有了比较深刻的了解,这种程度足以满足我们「开阔眼界、提升知识水平」的需求了。但是这两个阶段后,信息多以话题为核心被物理打包在一起(比如放在同一个文件夹里),话题与话题之间的关联性却很弱,某个话题下的具体信息经常要靠本人灵光一现才能被关联到另一个话题里。换句话说,我们还没有
把这些东西变成「自己的」
。
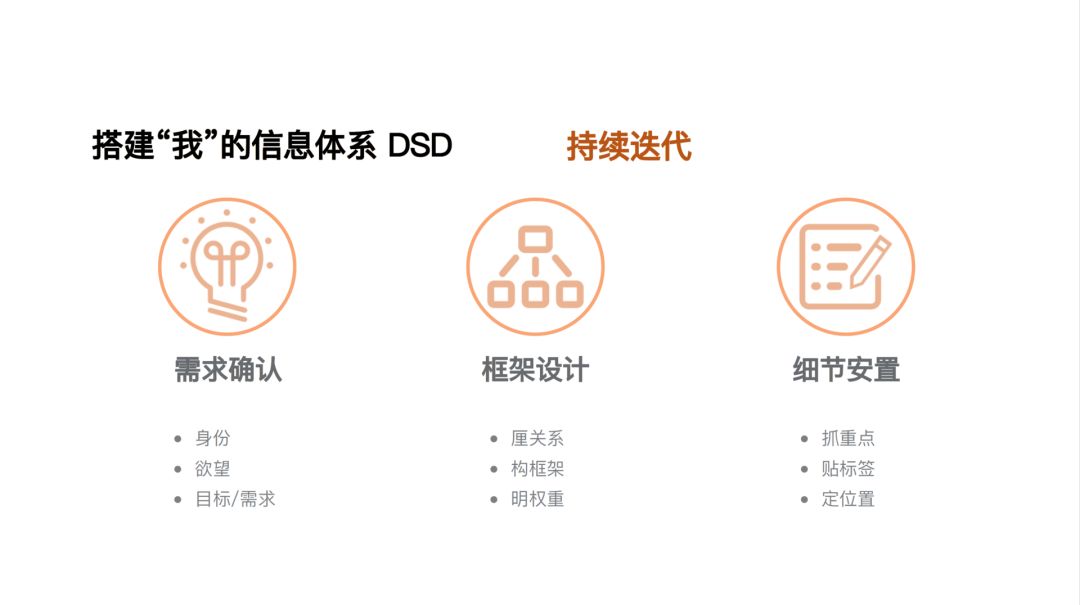
(图为分享人郭佳桦的信息体系搭建 DSD 模型)
既然是搭建属于自己的信息体系,自然就要
从个人需求出发,想一想自己为何要搭建信息体系、想实现什么目的、能否实现以及如何实现
,不要盲目地追求「体系化」这个 buzzword。
(这部分在第二期回顾视频「如何管理好时间」和回顾文章《
「管」不好时间?我还可以抢救一下
》中有详细讲解,此处不再赘述,感兴趣的同学可以跳转了解。)
基于需求,我们再去设计一个比较完整的框架体系。这个框架可以是大框架,涵盖自己职业发展和兴趣爱好;大框架之下也可以有小框架,比如围绕某个话题向外延伸,尝试关联到不同的领域、不同的话题,寻找交叉点。不管多大的框架,最重要的是
厘清框架与目标的关系、框架与框架的关系,并且随着需求变更持续迭代,使其适应新的阶段。

(图为分享人郭佳桦的个人信息体系)
由于我们精力有限,所以更要评估好信息体系的权重,而不是埋头苦「建」。信息体系本身是必要的,否则我们刻意输入的那些优质信息只能被「乱堆」在文件夹和头脑中,在需要的时候调取困难。但是
信息体系下每个部分的主次、先后和投入量,都要做到心中有数
。比如,分享人佳桦正处于职业瓶颈,所以会优先学习符合她职业规划的内容,在燎原外她会看市场研究相关的书籍,在燎原内会选择更有利于训练研究和分析能力的 PBL。
相比于前面两个阶段我们围绕一个既定话题去输入信息,在这个阶段我们将变得更主动,开始基于自己的需求和兴趣寻找适配的信息,然后再次搜索和精简,获得高质量且满足目标的内容。这些内容经过加工处理、提取精华后,放置在体系内相应的位置,贴上简介标签,在需要调取的时候通过文件夹内检索就可以快速定位。

(图为分享人郭佳桦的框架细节示例)
信息体系的外在形式并不影响本质,所以不必太过纠结于用哪种 APP 来。越到后期,依靠文字搭建体系的场合会越少,「框架」更像一个隐形的网,连接起各部分被打包起来的信息,文件夹的排列结构只是一个外显成果,此时迅速从「体系」中提取与某个新话题关联的信息的能力会变得越来越重要。
◇◆◇
输出:高效输入的不二法门
我们在大量输入的同时,很容易产生「我也好想这么有逻辑地写东西啊」类似的想法。而结构化输出能力的确是可以训练的。
学术论文
作为常见的论述性文本,要求写作者围绕一个非常明确具体的话题整合已有信息并对其进行讨论,能够非常有效地训练写作者的结构化和逻辑论证能力。其实 PBL 的项目产出基本上都是「拥有有趣灵魂」的学术论文,都是在提升逻辑输出能力。
经过信息搜索和精简两个阶段,我们基本已经可以筛选出数量有限的关于某个话题的高质量信息,在此基础上,我们就可以尝试寻找一个合适的切入点「从零开始」写论文。
首先,挑出一篇文献作为你即将完成的论文的初始框架
。选哪篇呢?一个有效的方法是选择你在阅读过程中产生最多 active questions(主动疑问)的那一篇,因为这意味着你理解了原作者的文本,你和对方没有太多的知识鸿沟,而你的 active questions 恰好可以转变为论文框架。
然后,仔细阅读这篇文献,找出它的逻辑结构
。这样做的好处是,一方面可以梳理作者的观点和行文逻辑,另一方面可以发掘出更多认同或反驳的观点或者研究缺失之处,这个过程非常有助于训练论证能力。标准的学术论文通常都会有非常清晰的结构和明确的关联词,所以阅读学术文献并不像大家想象得那么困难。
最后,围绕自己找到的可以攻击或补充这篇文献的点,开始有针对性地查找新的资料,对这些点进行论证或修正,最终形成自己的逻辑结构。
我们不可能每次输出都完全基于自己已知的内容,尤其是在学术论文中,「我认为」、缺乏论据及其来源的结论都是相当无力的论述,这反过来会「逼迫」写作者把漏洞都补上,甚至要提前设想可能被攻击的地方并作封堵或让步。
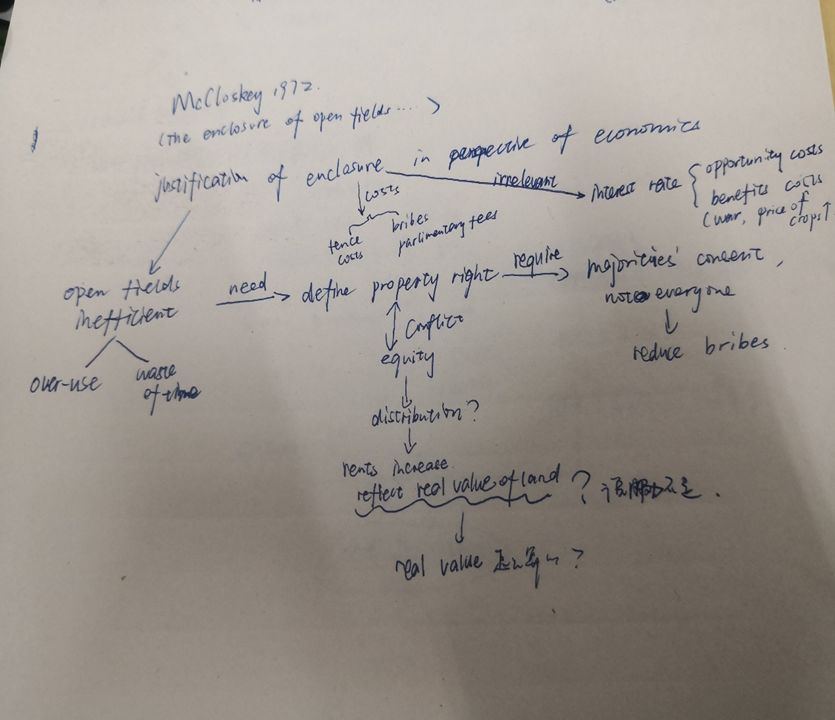
图为分享人张菀庭绘制的 Enclosure of open fields (McCloskey, 1972) 的思维导图
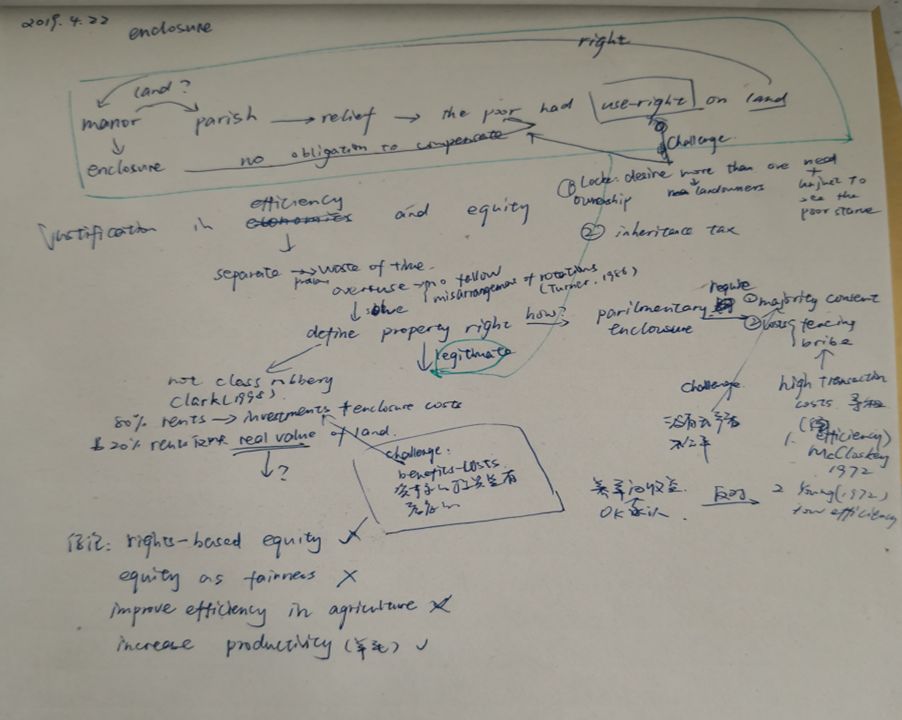
(图为分享人张菀庭自己撰写的论文 The justification of enclosure in perspective of efficiency and equity 的思维导图)
大家不要认为只有提出「新」的观点才能写学术论文,也不要坚持先具备逻辑论证能力再完成一篇「完整」的文章。
训练结构化输出的能力是一个长期过程
,所以每一次的结果并不是最重要的,因为我们的确很难只用一两次的训练就从输出困难蜕变为顺畅表达,只有经过反复的练习,每次反馈给自己进步和发现的问题,再在下一次尝试中巩固和改进,从 1 到 10 到 20 到 50,不断加速提升。
(所以各位千万不要因为一次 PBL 产出不满意就放弃了整片大森林啊!)
如何让信息爆炸成为我们自我提升的利器呢?这个问题到此已经基本回答完毕:
-
对于要了解的话题有一个
明确且具体的目的
,不要只说「出于兴趣」或「出于完成任务」,要思考清楚自己可以投入多少时间和精力,想要并且可以达到哪种程度;
-
如果对这个话题并不了解,但又希望自己并不流于表面事实而可以更深入地了解这个话题,那么建议优先选择
高质量信息密集度和广度高的学术网站
,如维基百科、谷歌学术、JSTOR,以初步搭建起这个话题的宏观图景;
-
在检索过程中牢记自己的目的,逐渐确立更细致的方向,根据目的和方向
对搜索结果进行甄别和筛选
,只考虑符合目的的内容,果断放弃「离题万里但很有兴趣」的信息;
-
对于了解得比较深入的话题,可以对其进行压缩打包,贴上标签,
纳入自己的信息体系
,并且尝试将其与已有的信息进行关联,成为随用随取、属于自己的知识;
-
如果想要输出自己对于话题的见解,可以尝试
写一篇短小的学术论文
,训练自己提取观点、找出逻辑漏洞、形成自己的观点并进行论证和捍卫的结构化输出能力。
虽然信息爆炸客观上增加了我们获取优质信息和高效处理信息的难度,但实际上我们欠缺的一些能力才是造成问题无法被有效解决的根源,比如主动学习、目标-路径规划、体系化和结构化、逻辑论证等等。前两个「学习没有方法」的专题中也都非常清晰地反映了这个现象:我们有时会过度追求解决表面的一个小问题,却忽视了去解决造成这个小问题以及其他诸多小问题的根源,但恰恰是这种找出、分析、解决根源问题的思维模型才是我们无往不利的神器。
所以,下周一开始,我们将用四节直播课为所有受此困扰的学生们,找到最根本的解决路径。而经历过多个 PBL 实践的燎原学员们,结合自己的实践经历,将清晰地知道如何在燎原学院零成本试错的环境下,利用燎原加速提升问题解决能力!

直播地点:CCtalk 燎原学院总群(81609340)
转播地点:CCtalk 孤独的阅读者总群(911911)
◇◆◇
燎原小报·系列文章
第1期:燎原学院的作业是逛菜市场?
第2期:韭菜的自我成长指南
第3期:燎原大陆的笔记圣典
第4期:
每逢看展懵三圈
第5期:读书三境界
第6期:西伯利亚帝国
第7期 营销天团秘密大起底
第8期:相信科学,真的就科学吗?
第9期:时间管理术
第10期:「伟大的女性」主题策展
第11期:今天你被 qiáng 了吗
第12期:
时空局萌新试探案
第13期:










