
互联网消费金融时代,如何科学合理地利用大数据进行风险控制,建立基于大数据的互联网金融整体解决方案?
一、 消费金融现状
我国消费结构正在从吃、穿等生存型消费向教育、旅游等发展型和品质型消费过渡,消费升级使得消费金融迎来爆发时刻。互联网消费金融能够通过“消费金融化、金融生活化”,实现金融资源跨期、错期配置,还可为消费尤其是电子商务提供良好的金融服务环境。风控对于金融来说永远是核心,无论是传统金融还是互联网消费金融。所谓风控,无外乎就是在一大堆看似正常的用户中将一小撮“坏人”揪出来,因此这当中就会有“求真去伪”的问题。而谈到风控,就一定要讲数据,因为巧妇难为无米之炊。因此本文想和大家一块来谈谈数据与风控的那些事儿,毕竟这是一件痛苦并快乐的事情。
传统金融的风险控制,主要是基于央行的征信数据及银行体系内的生态数据依靠人工审核完成。而央行征信系统里真正有信贷记录的自然人数仅有3.7亿人(2015年数据),因此对于其他人就需要靠其他数据来进行信贷风险的判断。互联网的发展和大数据的崛起,有效地将征信数据范围做了很大的延伸,使得我们可以利用更多的非金融机构数据进行风险控制,这些数据可以更加全面地预测小额贷款的风险,这也是现如今大数据征信市场一片火热的主要原因之一。

二、 征信数据的构成
互联网消费金融征信数据来源可以分为如下三部分:场景内数据、平台自身数据和外部征信数据。申请贷款时,用户需要提供部分申请信息,如工作信息、学历信息、收入信息等,除此之外合作的平台或
场景方也可提供部分信息,如贷款申请时的行为信息等,这些数据我们称之为场景内数据。
如果贷款平台较大较成熟,且有足够的数据积累,风控对外部征信数据的依赖就较小。但实际情况是,互金平台都比较小,场景内数据又有造假嫌疑以及出于用户体验的考虑,不会有太多,因此会较多依赖外部征信数据,这也是现在第三方征信数据市场火爆的原因。
三、大数据风控
谈到如何更好的利用外部数据?很多人浮现在脑海里的肯定是大数据风控或大数据风控模型。而提到大数据风控(模型),很多人会想到AI、机器学习、数据挖掘,甚至会把Deep Learning(深度学习)也搬出来。大家潜意识都认为,大数据风控如果不提应用了DBDT、xgboost、神经网络等复杂模型,则默认这风控做得很low。个人感觉,“大数据风控“这个词现在有点被神化了。从实际风控业务来讲,当前还无法直接将AI或很复杂的数据挖掘算法直接应用到风控业务中来。受制于数据、正负样本、征信成本、产品体验等各方面原因,很复杂的模型或AI往往在实际业务中不能有效地跑起来。当然并不是否认AI或机器学习等在大数据风控中的应用价值,我相信未来AI、机器学习等将在大数据风控中发挥至关重要的作用。
在这方面,我想和大家分享下我们在大数据风控上的一些小小心得。我们没有一味地去追求建立或运用复杂的模型,但是我们的风控策略或风控模型却又一直灌注着机器学习和AI的思想。举例来说,黑名单数据深得各家互金公司的宠爱,几乎是来者不拒。但因数据污染等问题的存在,市面上各家黑名单的质量参差不齐,而且整体质量有不断下降的趋势。因此如果还遵循命中黑名单就拒绝这种强规则逻辑肯定不适合,且会将很多本质上优质的客户拒之门外。
在这里我们可以借助Adaboost算法思想更好地挖掘黑名单的价值,集众家之所长。
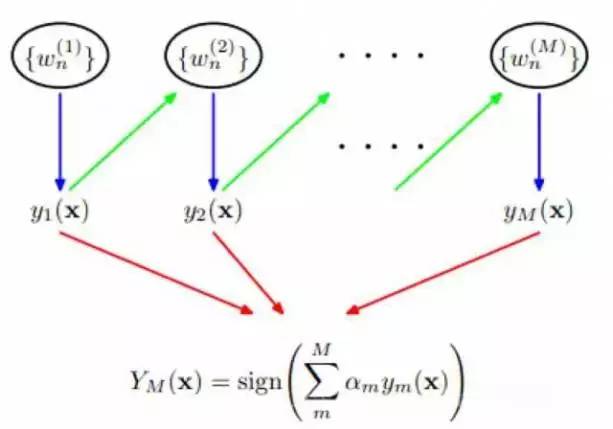
图1:Adaboost算法结构
借助这个算法原理,可以把每家黑名单当成一个弱分类器,随着接入外部黑名单数据源的不断增加,根据各家黑名单的表现赋予一定的权重,最终构成一个强的分类器。并根据不同的场景设置不同的阈值去判定某个用户是否准入。
四、消费金融风控体系
聊完了征信数据的构成和数据的使用,那互联网消费金融的风险来源主要有哪些,如何防范这些风险呢?
互联网消费金融因其虚拟性,主要风险集中在两方面,一是欺诈风险,一是信用风险。










