(点击
上方公众号
,可快速关注)
译文:yexiaobai
英文:Marina Mele
链接:segmentfault.com/a/1190000002400160
当运行一个复杂的 Python 程序,它需要很长时间来执行。你或许想提升它的执行时间。但如何做?
首先,你需要工具来查明你代码的瓶颈,比如,那部分执行花费的时间长。用这个方法,你可以首先专注于提升这部分的速度。
而且,你也应该控制内存和 CPU 使用率,因为它可以为你指出的代码可以改进的新的部分。
所以,在本文中,我将对 7 个不同的 Python 工具发表意见,给你一些关于你函数执行时间和内存以及 CPU 使用率的见解。
1. 使用一个装饰器来测量你的函数
测量一个函数最简单的方式就是定义一个装饰器来测量运行该函数的运行时间,并打印该结果:
import time
from functools import wraps
def fn_timer
(
function
)
:
@
wraps
(
function
)
def function_timer
(
*
args
,
**
kwargs
)
:
t0
=
time
.
time
()
result
=
function
(
*
args
,
**
kwargs
)
t1
=
time
.
time
()
print
(
"Total time running %s: %s seconds"
%
(
function
.
func_name
,
str
(
t1
-
t0
))
)
return
result
return
function
_
timer
这时,你已经在你想测量的函数之前添加了装饰器,像:
@
fn_timer
def myfunction
(...)
:
...
例如,让我们测量下排序一个 2000000 个随机数的数组会花费多长时间:
@
fn_timer
def random_sort
(
n
)
:
return
sorted
([
random
.
random
()
for
i
in
range
(
n
)])
if
__name__
==
"__main__"
:
random_sort
(
2000000
)
如果你运行你的脚本,你将看到:
Total time running
random_sort
:
1.41124916077
seconds
2. 使用 timeit 模块
另外一个选项是使用 timeit 模块,它给你测量一个平均时间。
为了运行它,在你的终端执行以下命令:
$
python
-
m
timeit
-
n
4
-
r
5
-
s
"import timing_functions"
"timing_functions.random_sort(2000000)"
timing_functions 是你脚本的名字。
在输出的最后,你会看到一些像这样的东西:
4
loops
,
best
of
5
:
2.08
sec per
loop
表明了运行这个测试 4 次(-n 4),并在每个测试中重复平均 5 次(-r 5),最佳的结果是 2.08 秒。
如果你没有指定测试或者重复,它默认是 10 次循环和 5 次重复。
3. 使用 Uinx 的 time 命令
尽管如此,装饰器和 timeit 模块都是基于 Python 的。这就是为什么 unix time 工具或许有用,因为它是一个外部的 Python 测量。
为了运行 time 工具类型:
$
time
-
p
python
timing_functions
.
py
将给出如下输出:
Total time running
random_sort
:
1.3931210041
seconds
real
1.49
user
1.40
sys
0.08
第一行来自于我们定义的装饰器,其他三行是:
-
real 表明了执行脚本花费的总时间
-
User 表明了执行脚本花费在的 CPU 时间
-
Sys 表明了执行脚本花费在内核函数的时间
因此, real time 和 user+sys 相加的不同或许表明了时间花费在等待 I/O 或者是系统在忙于执行其他任务。
4. 使用 cProfile 模块
如果你想知道花费在每个函数和方法上的时间,以及它们被调用了多少次,你可以使用 cProfile 模块。
$
python
-
m
cProfile
-
s
cumulative
timing_functions
.
py
现在你将看到你的代码中每个函数被调用多少次的详细描述,并且它将通过累积花费在每个函数上面的时间来排序(感谢 -s cumulative 选项)
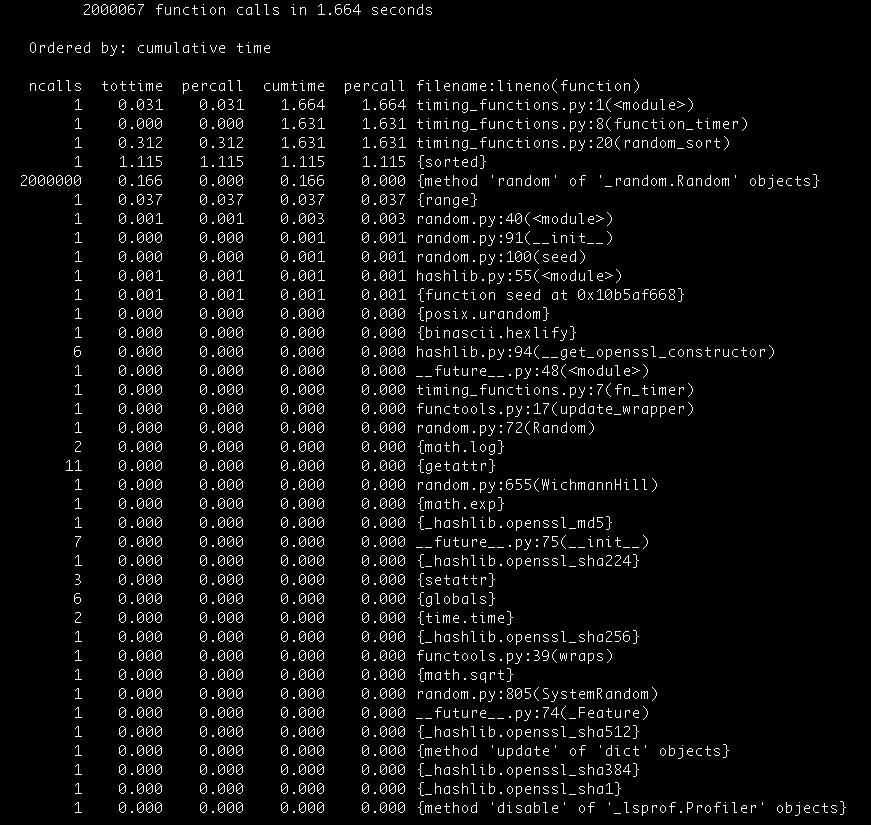
你将看到花费在运行你的脚本的总时间是比以前高的。这是我们测量每个函数执行时间的损失。
5. 使用 line_profiler 模块
line_profiler 给出了在你代码每一行花费的 CPU 时间。
这个模块首先应该被安装,使用命令:
$
pip install
line
_
profiler
下一步,你需要指定你想使用装饰器 @profile 评估哪个函数(你不需要把它 import 到你的文件中)。
@
profile
def random_sort2
(
n
)
:
l
=
[
random
.
random
()
for
i
in
range
(
n
)]
l
.
sort
()
return
l
if
__name__
==
"__main__"
:
random_sort2
(
2000000
)
最后,你可以通过键入以下命令取得 random_sort2 函数逐行的描述:
$
kernprof
-
l
-
v
timing_functions
.
py
-l 标识表明了逐行和 -v 标识表明详细输出。使用这个方法,我们看到了数组结构花费了 44% 的计算时间,sort() 方法花费了剩余的 56%。
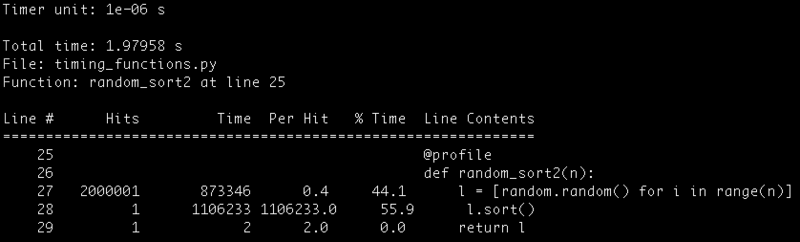
你也将看到,由于时间测量,这个脚本执行花费的或许更长。
6. 使用 memory_profiler 模块
memory_profiler 模块被用于在逐行的基础上,测量你代码的内存使用率。尽管如此,它可能使得你的代码运行的更慢。
安装:
$
pip install
memory
_
profiler
也建议安装 psutil 包,使得 memory_profile 模块运行的更快:
$
pip install
psutil
类似 line_profiler 的方式,使用装饰器 @profile 来标记哪个函数被跟踪。下一步,键入:
$
python
-
m
memory_profiler
timing_functions
.
py
是的,前面的脚本比之前的 1 或 2 秒需要更长的时间。并且,如果你不安装 psutil 模块,你将一直等待结果。
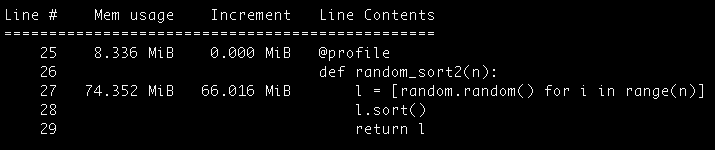
看上面的输出,注意内存使用率的单位是 MiB,这代表的是兆字节(1MiB = 1.05MB)。
7. 使用 guppy 包
最后,使用这个包,你可以跟踪每个类型在你代码中每个阶段(字符, 元组, 字典 等等)有多少对象被创建了。
安装:
$
pip install
guppy
下一步,像这样添加到你的代码中:
from guppy import hpy
def random_sort3
(
n
)
:
hp
=
hpy
()
print
"Heap at the beginning of the functionn"
,
hp
.
heap
()
l
=
[
random
.
random
()
for
i
in
range
(
n
)]
l
.
sort
()
print
"Heap at the end of the functionn"
,
hp
.
heap
()
return
l
if
__name__
==
"__main__"
:
random_sort3
(
2000000
)
并且这样运行你的代码:
$
python
timing_functions
.
py
你将看到一些像下面的输出:

通过配置 heap 在你的代码的不同地方,你可以在脚本中学到对象的创建和销毁。
如果你想学习更多提升你 Python 代码的知识,我建议你看看 2014 年 11 月出版的 High Performance Python: Practical Performant Programming for Humans 这本书。
关注「Python开发者」
看更多精选Python技术文章
↓↓↓






