引子
当我在 Notion 里下这一行文字时:
我的思想被神经元序列化成一句句要表达的语言,进而推动我的双手将其序列化成在蓝牙键盘上有节奏的敲击出的字符流。
随即,机械运动产生的字符流被序列化成电信号,进而通过蓝牙协议序列化成一系列包含着 KeyDown/KeyUp 事件的比特流,传输到旁边合着屏幕的笔记本电脑上。
这些 KeyDown/KeyUp 事件流,被我的 Notion 的 window 时间循环捕捉到,序列化成保存在文本缓存区的 utf8 字符串。
一切都是序列化
想想你写的代码。比如 Rust。Rust 代码是一种序列化的格式,它可以在 Rust 程序员间进行正常的交流。当它保存在磁盘上时,它被序列化成 utf8 字符串。
然而它不能被计算机识别。假设要让这代码跑在 iPhone 上,我们需要 Rust ARM 编译器,将其序列化成中间状态的 ARM 汇编(我们略过 LLVM 的部分不谈),然后再进一步序列化成机器可以读懂的 ARM Instruction。

(google image 搜的,来源见:[1])
在这里软件和硬件像湘江注入长江一样,开始交汇。CPU 将一条条指令反序列化,指挥相应的部件做对应的操作,最后把结果序列化到内存中。
不光如此,计算机的所有组成部分,都是一个个数据驱动的组件,它们像拉特尔指挥下的柏林爱乐乐团,通过流动的数据完美地联动着,把生涩的曲谱转化成优雅的乐章。
让我们把目光稍稍拉回,毕竟钻到 CPU ABI(Application Binary Interface)里折腾指令太 low~~ level,我们往上爬一点。
我们看看函数之间是怎么沟通的。
众所周知,函数之间通过栈来交流:调用者把参数序列化到栈上,被调者将其反序列化出来。
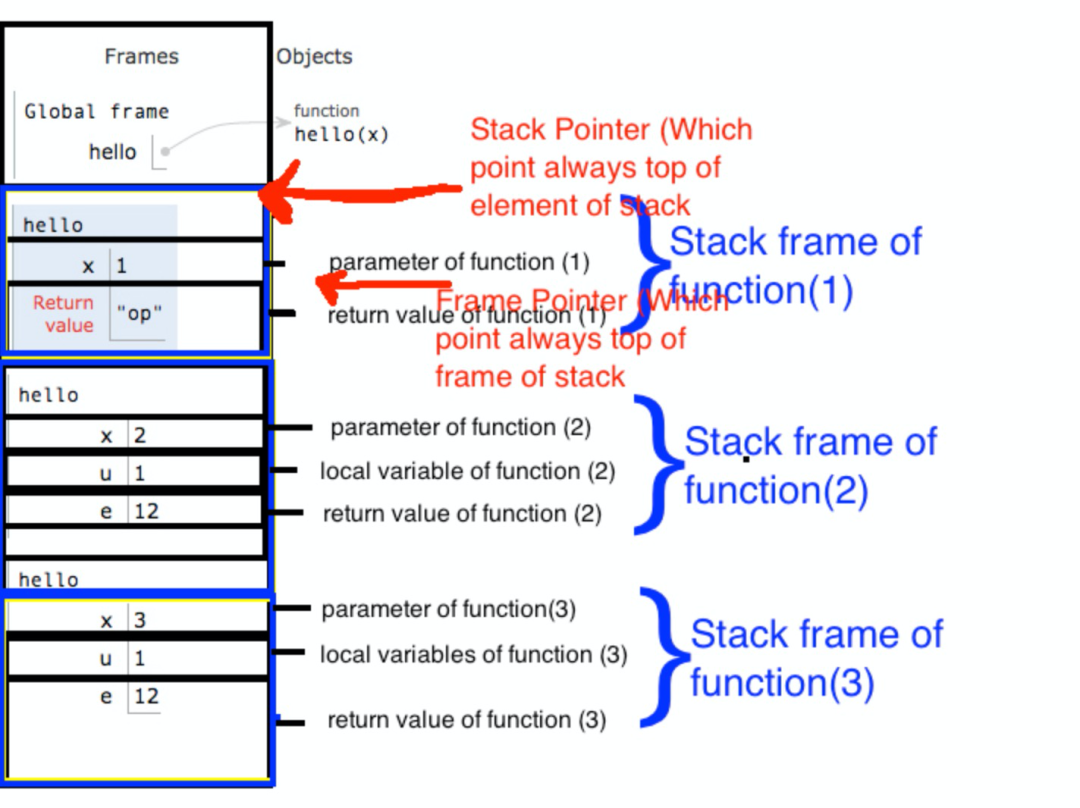
(google image 搜的,来源见:[2])
还是有点太 low~~ level?
还记得 ISO/OSI 七层协议么?我们看看你的某个基于 HTTP 的 RPC 调用,是如何一步步序列化的:
-
RPC 数据被包裹上 RPC 头(如果需要),交给 HTTP
-
HTTP 添加对应的 HTTP 头,交给 TLS
-
TLS 根据上下文把整个 HTTP payload 加密,然后添加 TLS 头,交给 TCP
-
TCP 根据 MSS 对 payload 进行切片,添加 TCP 头(源和目的的端口),交给 IP
-
IP 添加 IP 头(源和目的地址,协议等),交给 ETH(对于这个场景一般来说 IP 层不需要再分片)
-
ETH 添加 ETH 头(源 MAC 和目的地 MAC),并计算 CRC,交给网卡
-
网卡为这个 frame 添加合适的 preamble,序列化成电信号,传输出去
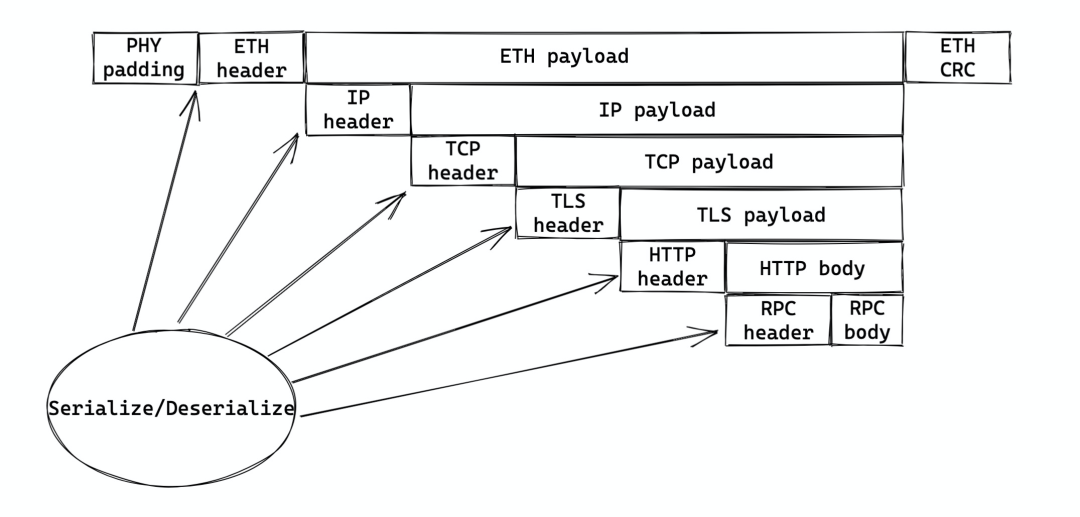
(搜不到合适的,我自己 excalidraw 画的)
我想你大概明白我的意思了。一切和信息相关的活动,都离不开序列化和反序列化。软件如此,硬件如此,序列化无处不在。
我们看:
不光是纯粹的通讯本身,就连我们写代码最基础的方法论:抽象,都离不开序列化。上文我们所谈的函数就是一个例子。函数是一切抽象的基础,而栈上的序列化和反序列化是函数得以正常执行的基础。对象也是如此,其成员函数被序列化进 vtable:
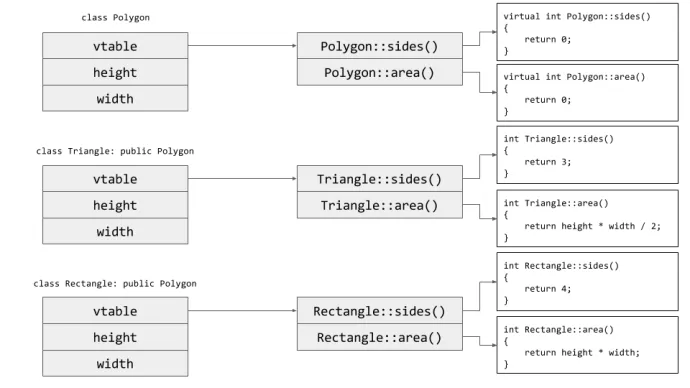
(还是 google image 搜出来的结果,来源见[3])
现在我们再想想整个软件产品,是不是感觉我们写的代码不外乎在做这样的事情:反序列化(Deserialize)信息,加工(Transform)之,然后再序列化(Serialize)传递给下一个调用者。函数如此,服务如此,应用程序也如此。我们管这个 Deserialize-Transform-Serialize 的过程叫 DTS。
其中加工的过程,往往又是一组新的 DTS。就像上面的 RPC 例子的一层层处理。就连 RPC 自己的内部的处理,也往往是向另一个数据源(比如数据库)发送序列化好的指令(如 SQL statement),然后数据源获取数据返回。
大部分时候,序列化反序列化自然而然发生,我们不需要关心,就像我们不用去亲自撸起袖子计算栈针,来保证函数调用的正常。
但,当我们要和文件,网络这些 IO 交互时,或者跨语言,跨进程传递数据时,我们需要进行合适的序列化和反序列化。
什么是好的序列化方案
这意味着要找到合适的序列化方案,或者说数据结构。好的结构应该是易于解析的,什么叫易于解析?数据是自描述的,并且我们清楚地知道数据的长度,比如 Erlang 的 external term format(ETF)中字符串的定义:
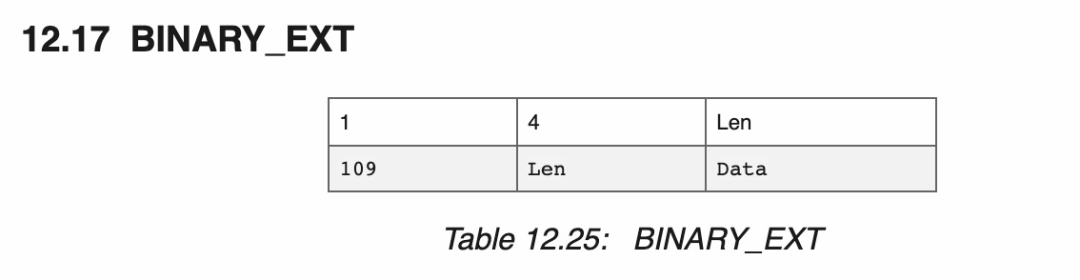
(图片来源:Erlang External Term Format,见 [4])
其中一个字节代表了这是哪种类型(Type),不同的类型数据格式不同,对于 erlang 字符串,之后是 4 个字节的长度(Length),通过这个长度,我们可以读取之后 len 这么多的数据,它是字符串的内容(Value)。一般读完 Type 和 Length 之后,我们就可以找到下一个 token,继续解析。这种 Type-Length-Value 序列化的方式叫 TLV,很容易解析。
但它有些浪费存储空间。
更好的方式是 Variable Length Encoding(VLE):Type 的长度和 Length 的长度都是可变的,且最常用的我们用最小的比特位为其序列化。比如 protobuf 就采用了 VLE 的方式,对于这样一个消息:
message Person { string user_name = 1; int64 favorite_number = 2; string interests = 3;}
实际的序列化方案要比 TLV 省很多空间。下面的例子字符串 Martin 长度为 6,用 4 个字节表述太浪费,这里仅用了一个字节就搞定。因为 protobuf 定义的字段是可选的,所以这里光靠 TLV 还不够,还需要每个字段的 tag,这就是为什么 protobuf 需要为每个字段提供序号,并且序号不可重复:
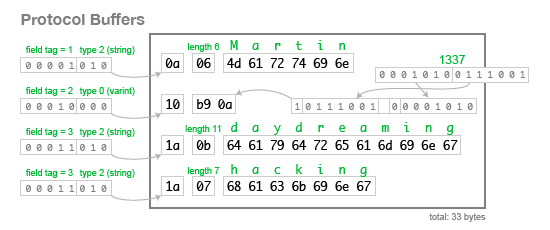
(图片来源:google image search,见:[5],可能有点老,但思想应该差不多)
以上两种方案都让反序列化或者说解析器撰写起来非常简单高效,但互联网时代大多数程序员平日里熟悉的 JSON 却并非如此。别看 JSON 长着一副憨憨的,很好对付的样子,我敢打赌,如果不用 flex/bison 这样的工具,或者 nom/NimbleParsec 这样的 parser combinator,在座的各位(包括我)一天之内很难写出一个合格的,效率并不差的 JSON 解析器。
这是因为 JSON 是上下文极其相关的,在上一个 token 解析完成之前,你无法解析下一个 token。
从这一点上,我们大概也能推断,JSON 的解析效率是非常低效的,令人发指的低效。
因而如果你能在任何需要序列化的场合尽量减少对 JSON 的使用,你的系统的性能会大大提升。即便你不得不使用 JSON,也尽量使用一门强类型的语言,为 JSON 定义好类型,然后用这个类型去辅助 JSON 的解析。Rust 中的 serde_json,如果你用
Value
(一个比较通用的数据结构)去解析而不是用某个定义好的
Struct
去解析 JSON,效率会相差一倍。
在之前的《前端中的后端 - 实现篇》,我做过类似的实验,发现 1.3M 的 JSON,用 Value 解析,竟然需要 8.96ms,而 Struct 解析,尽管快一倍,也需要 4.22ms:
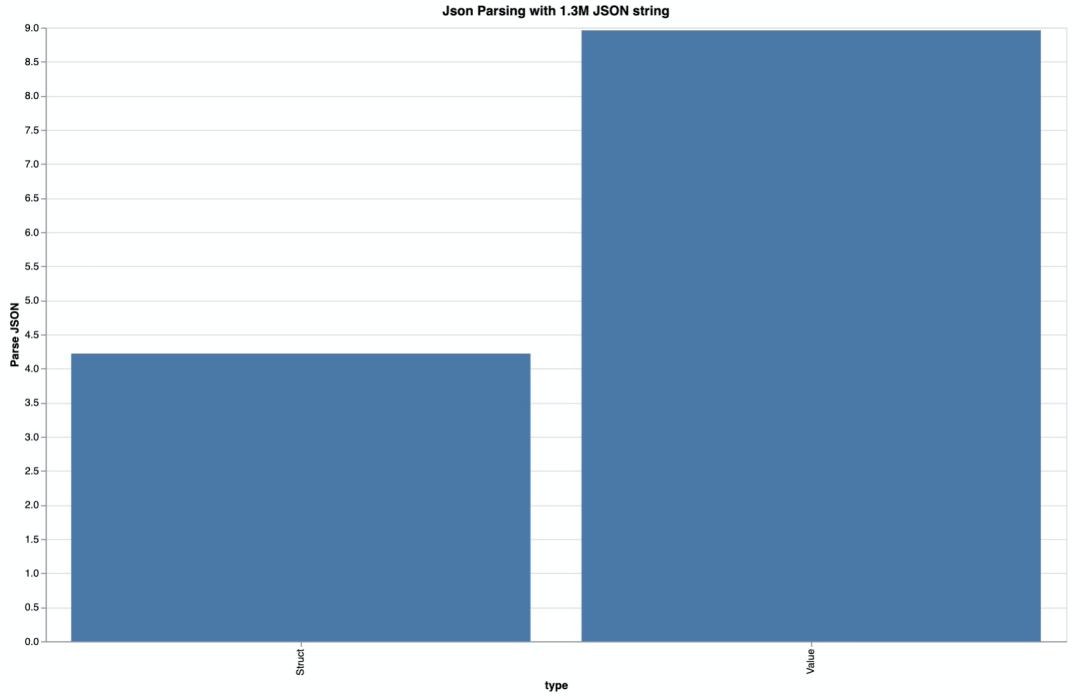
如果不用 JSON 的话,我们还有什么选择?
很多。protobuf 已经说过了,和它类似的 avro / Thrift 也可以考虑。还有 FlatBuffer,Cap'N 等 zero-copy 的序列化/反序列化方案。
等等,你说 zero-copy?
是的。protobuf 在反序列化的时候,需要 1) 反序列化整个数据,2) 对原始数据拷贝。
这是因为内存中的 数据结构无法和序列化出来的 buffer 一一对应,它有一个 VLE 处理的过程。而 FlatBuffer 这样的解决方案,它内存中的表现形式和序列化后的表现形式基本一致,只是多了一个描述 metadata 的头。这是为什么 FlatBuffer 几乎没有序列化和反序列化的时间:
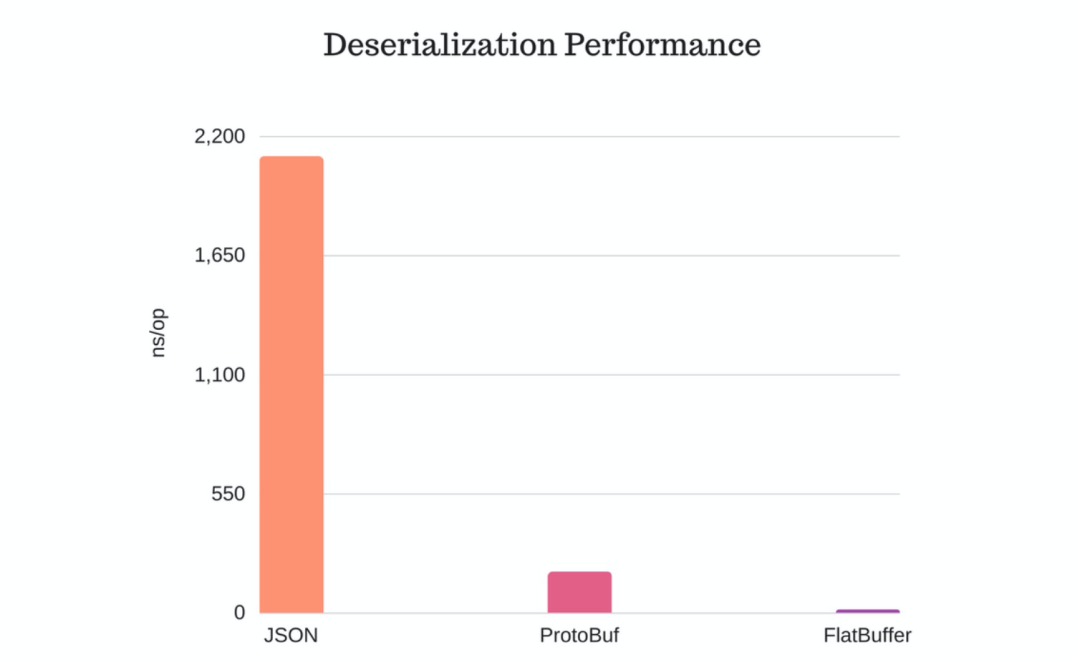
(图片来源:JSON vs Protocol Buffers vs FlatBuffers [6])
那 FlatBuffer / Cap'N 这样的方案岂不是任何情况下都是最优?
不是。
FlatBuffer 生成的数据结果可能比 protobuf 要大。即便内部不做进一步的压缩,protobuf 某种程度上已经附带了一点点压缩算法 —— 其 varint 实现就是对整数的压缩。想象一下,一个包含很多u64 的 vector,protobuf 显然要比 FlatBuffer 省更多的内存。
所以,好的序列化方案应该是:
这三者在不同的场合有不同的需求。当你需要数据能够被非常高效地读写时,选支持 zero-copy 的方案,如 FlatBuffer;当你需要不错的性能且节省内存时,选类似 Protobuf 这种什么都略好一点的方案;当你需要非常节省存储,比如序列化大量的结构化数据到磁盘上,选择压缩率高且易解析的方案,比如 parquet;除非在需要 human-readable 或者语言本身性能就很差的情况下,你才应该考虑 JSON/YAML。
序列化方案对架构的影响
很多时候,序列化方式的变换,会影响我们如何去做 transformation,而 transformation 的变化,几乎不会影响我们如何做序列化。
在这一点上,GPU 给我们做了非常好的榜样。GPU 接受的数据是 vertex buffer,它的数据结构是定长的向量。这种序列化方案很容易让成千上万个 CUDA 参与到运算当中,最大程度并行:
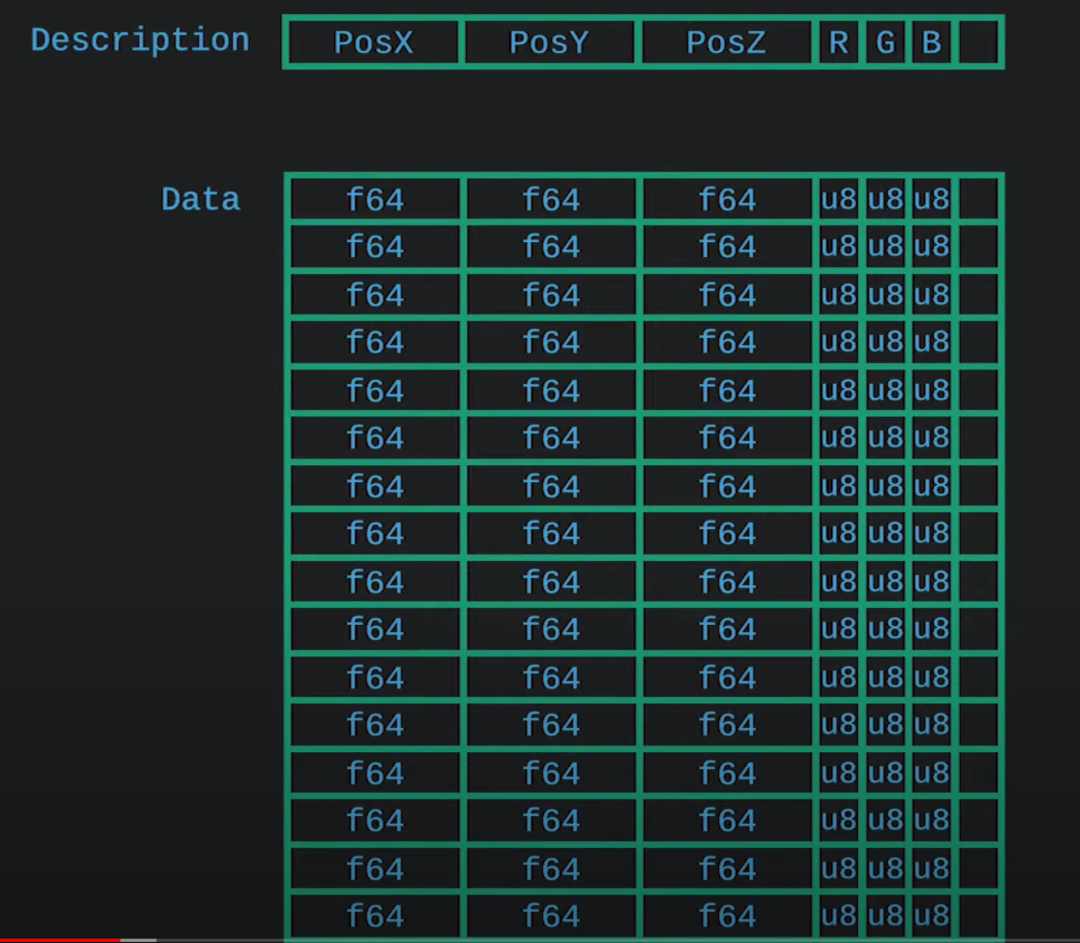
(截图见 Everything is serialization [9])










