2018年9 月 9 日-14 日,DeepMind主办的Deep Learning Indaba 2018 大会在南非斯泰伦博斯举行。会上,牛津大学教授Nando de Freitas和其他15位专家做了《深度学习: AI革命及其前沿进展》的报告
。

Nando de Freitas

Nando de Freitas是一名来自牛津大学的拥有高声望和优良业界口碑的机器学习教授。在2000年拿到Trinity College的博士学位后,1999至2001年他在 UC Berkeley担任博后,2001至2014年在 University of British Columbia担任教授,他还是加拿大高级科研学会(CIFAR)的一员,并拿到了许多学术类的奖项。Nando本人在其网站上这样简洁地描述他的兴趣:我想明白智能以及思考的机理。我的工具有计算机科学,统计学,数学和无尽的思考。2015年12月26日,Nando de Freitas加入了由Reddit管理的AMA(Ask Me Anything)平台。
报告导读
、

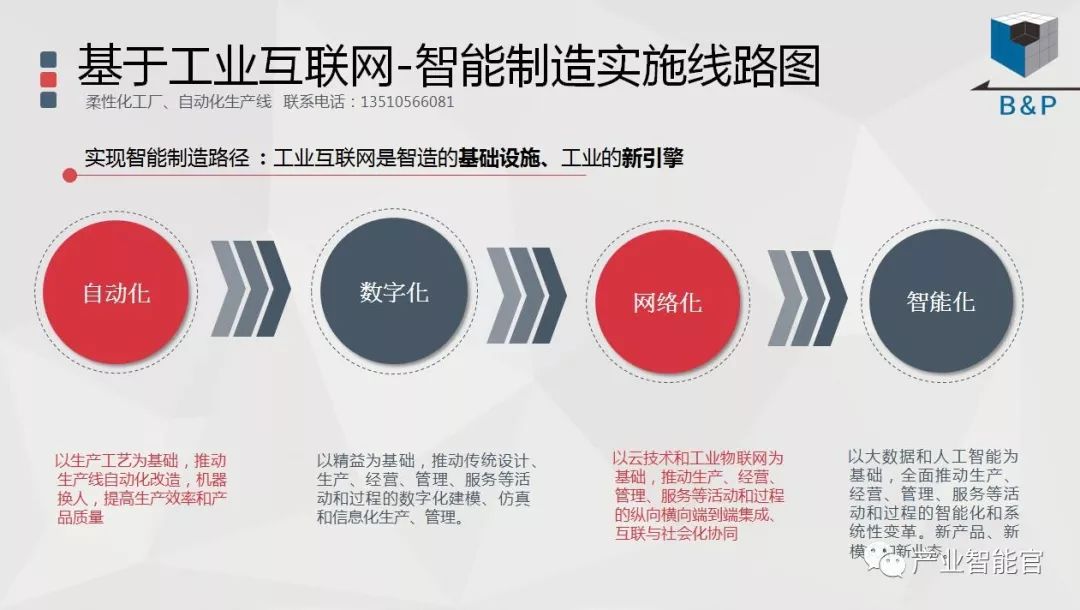
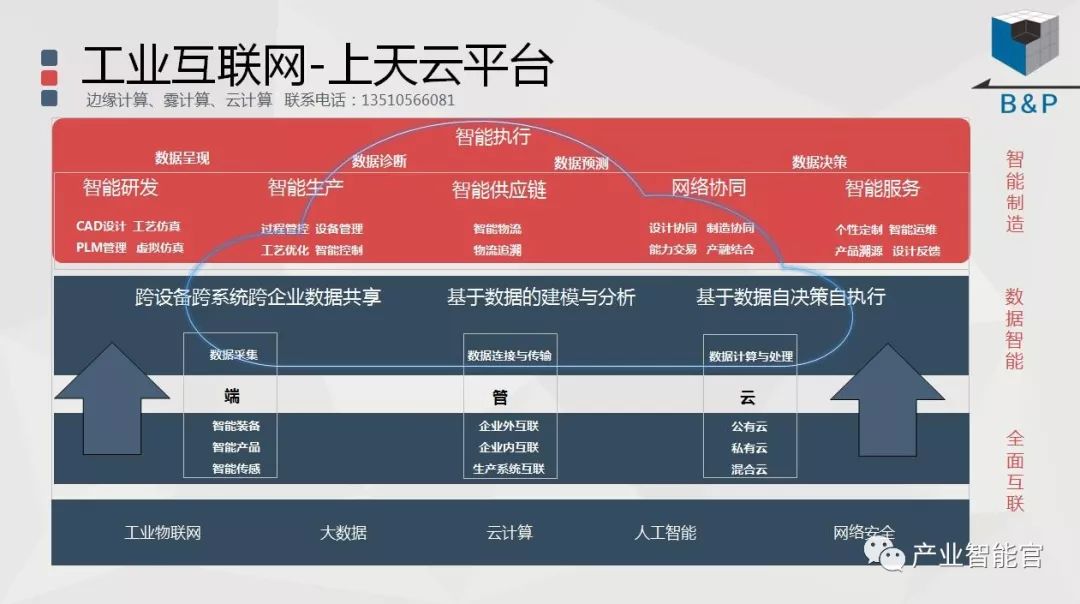
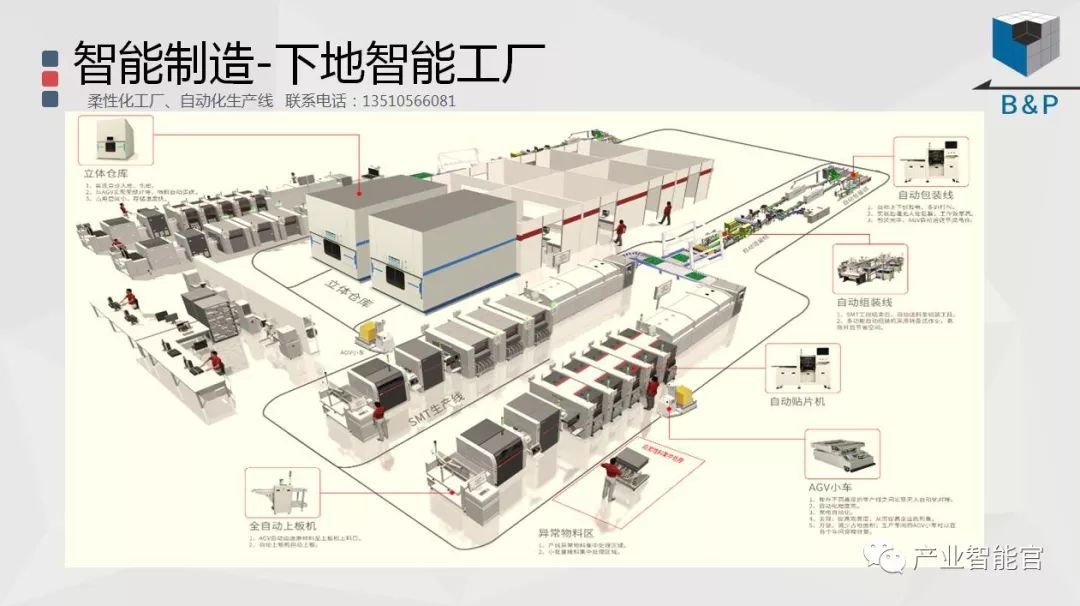
人工智能进展的关键要素:基础科学理论、数据、计算力、算法软件
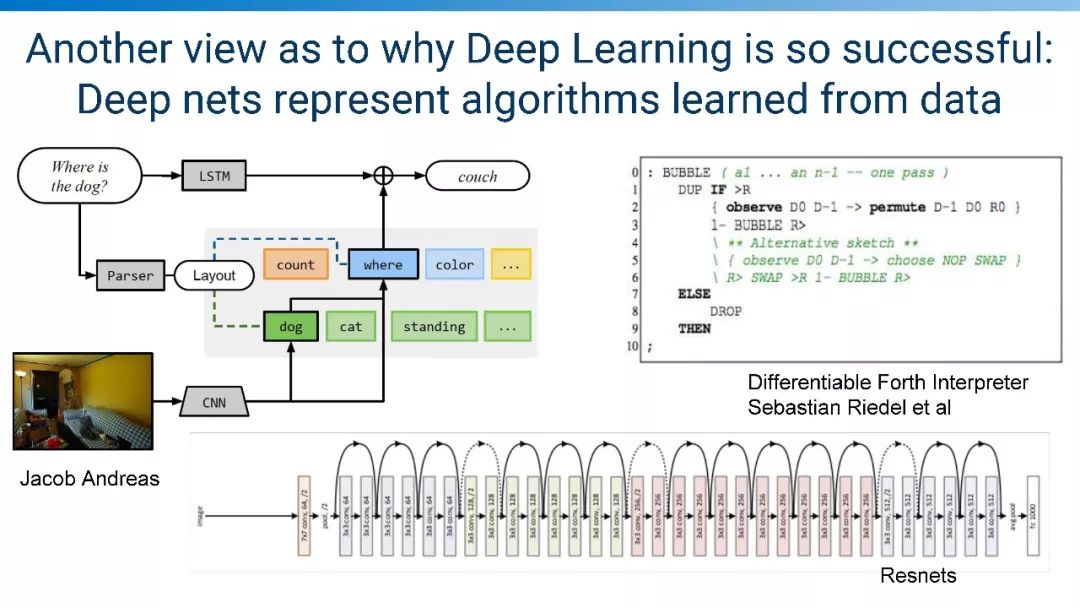
深度学为什么成功的另一视角: 深度神经网络从数据中学习
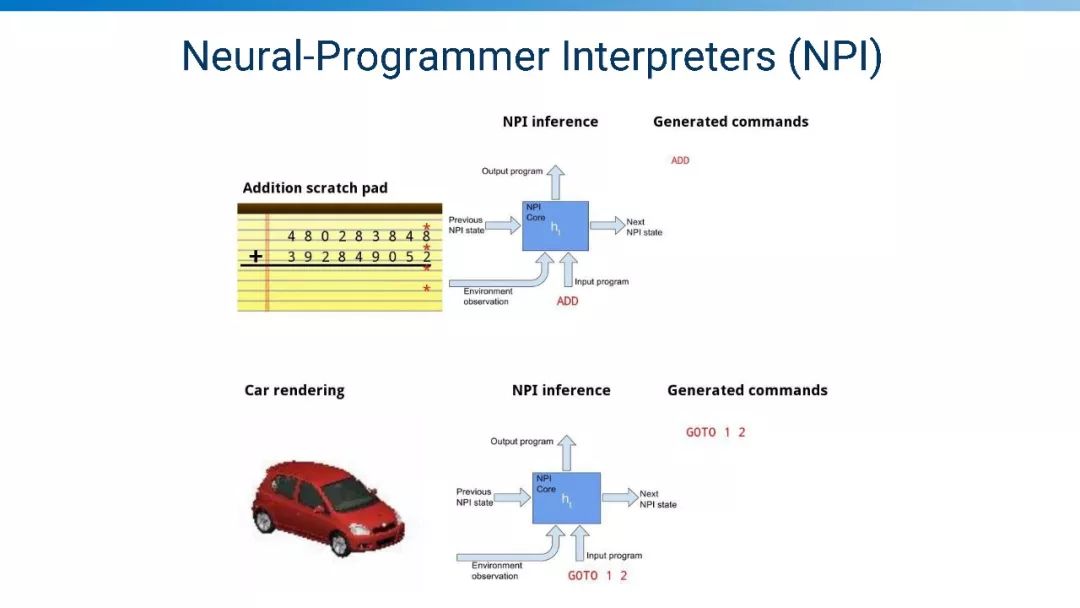
神经编程编译器

人工智能前沿7大热点:
-
强化学习
-
元学习
-
模仿学习
-
机器人
-
概念与抽象
-
感知与意识
-
因果推理
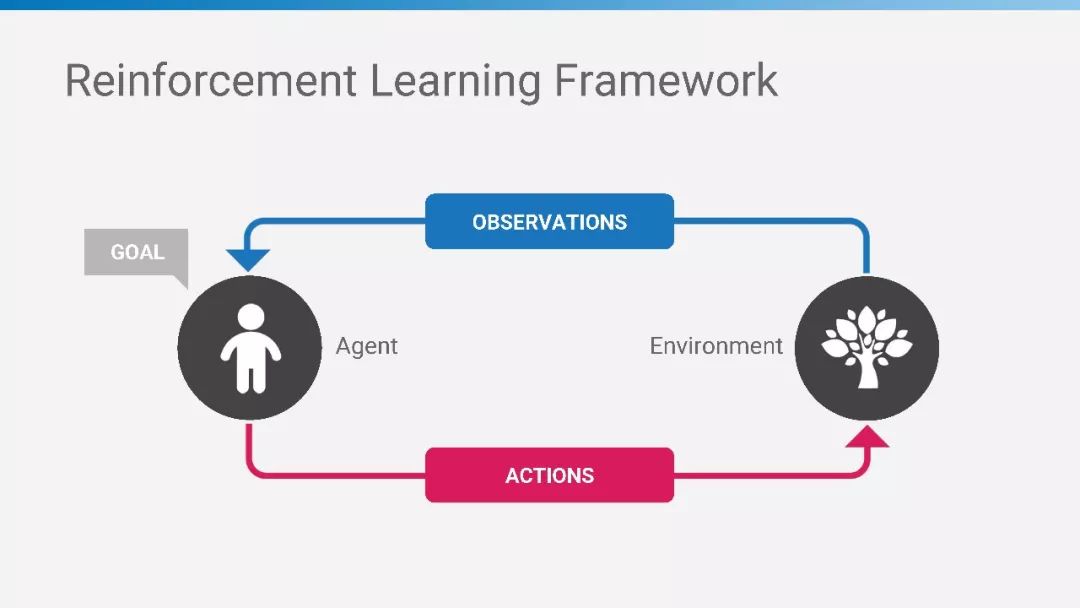
强化学习框架
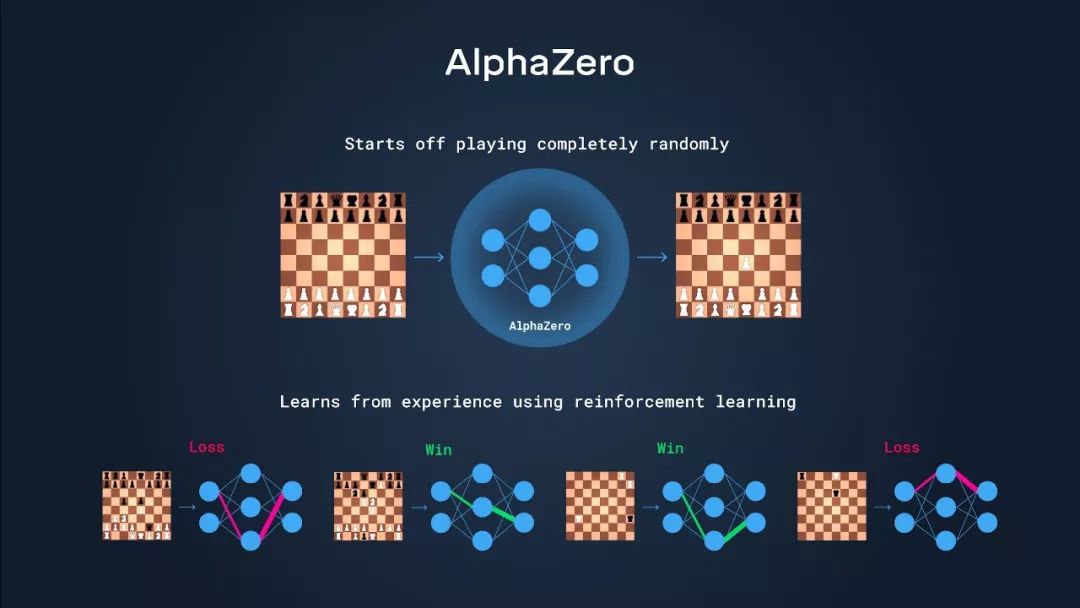
AlphaZero



模仿:帮助我们在强化学习中解决探索

模仿人学习非常重要:翻译、语音模型,通用协同
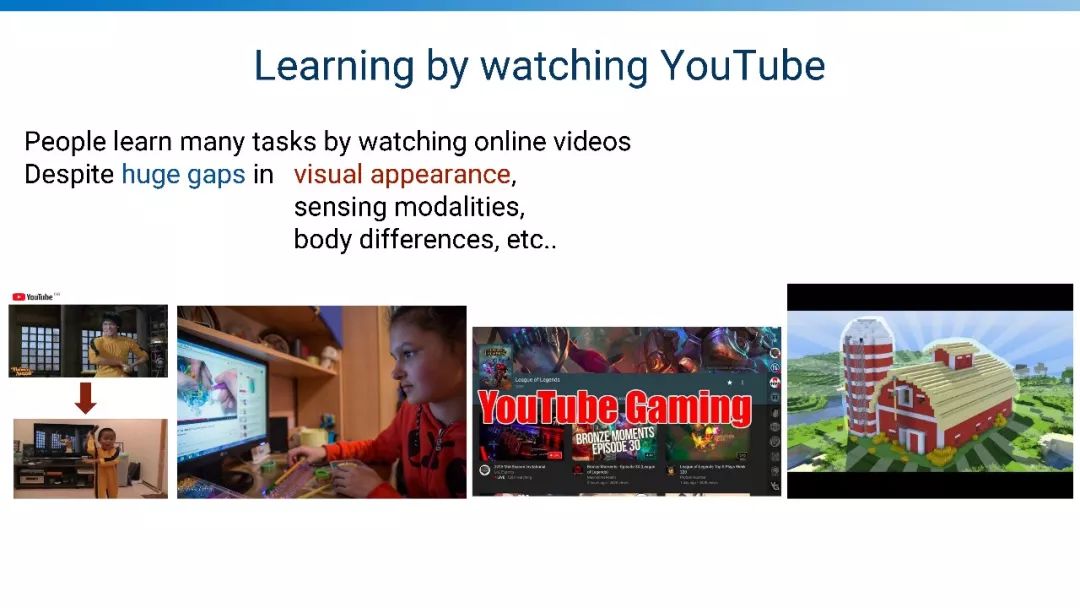
观看Youtube视频学习,人可以从视频中学习各种技能,机器是否同样来学习?
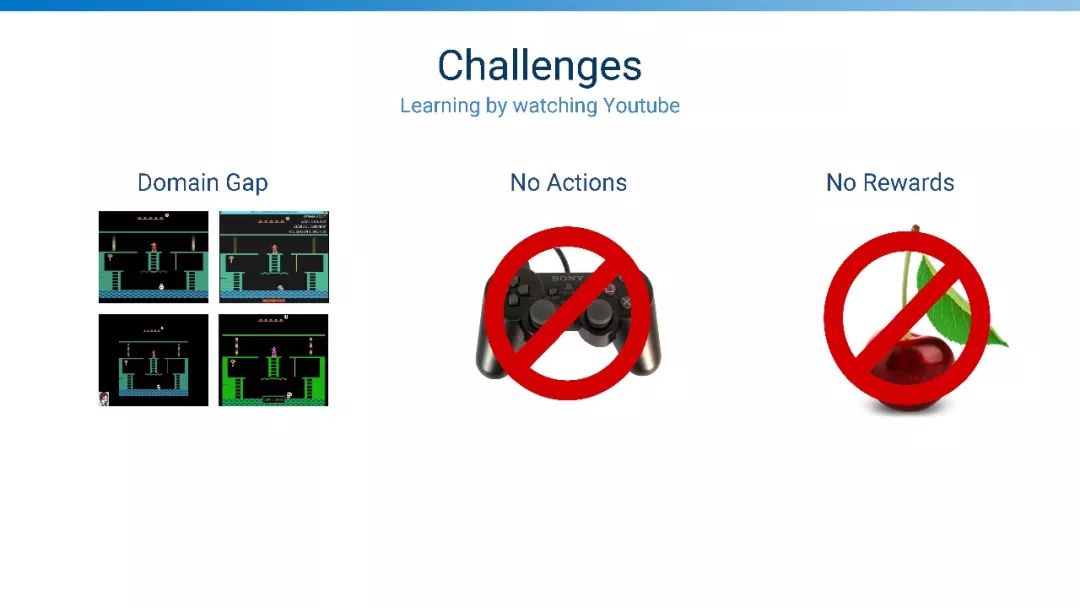
挑战:领域鸿沟、没有动作、没有奖赏
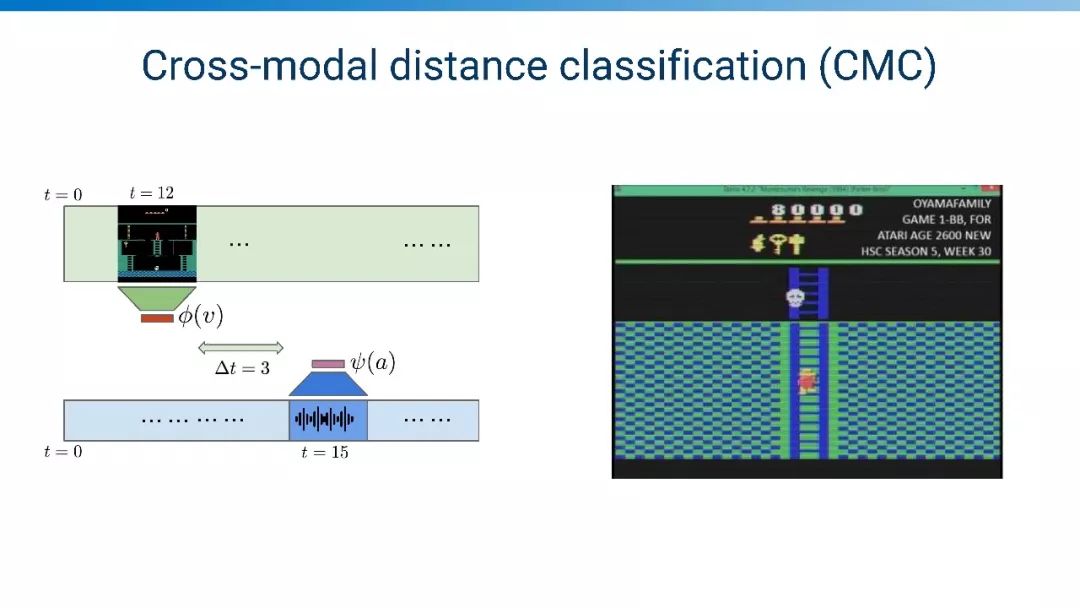
跨模态距离分类
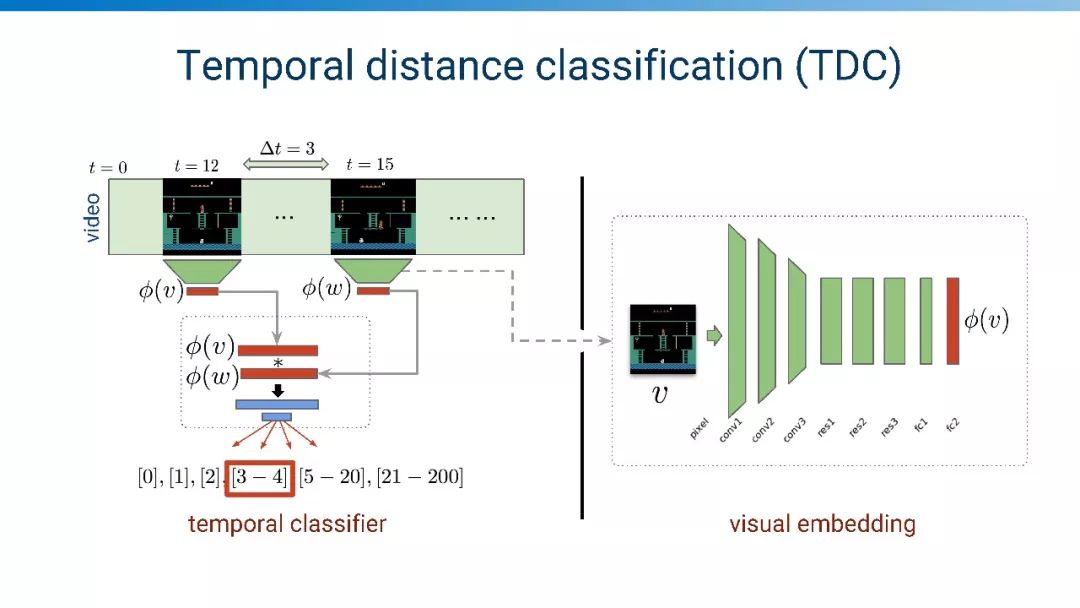
时序距离分类

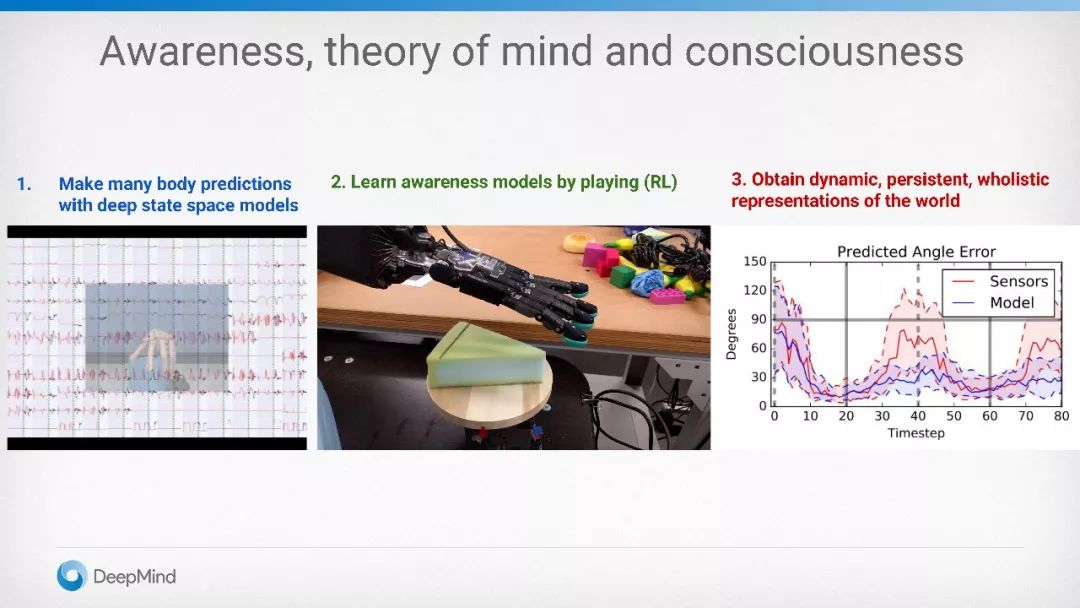
感知意识:思维意识理论
世界自身的知识能够帮助解构和表示学习
学习确认的智能代理、行为和意图非常重要
一个智能机器必须知道它知道什么和它不知道什么
感知意识提供一个模仿学习的框架

慢学习以更快学习

few shot 元学习

条件策略的one-shot 模仿学习

因果推理

其他人工智能的前沿领域包括:
-
抽象,概念、关系,物体,程序,架构
-
自监督自动选取任务
-
持续性知识表示
-
基准性语言理解
-
情感性动机型系统
-
鲁棒性、灵活性与软件框架
-
模块发明
-
道德和治理

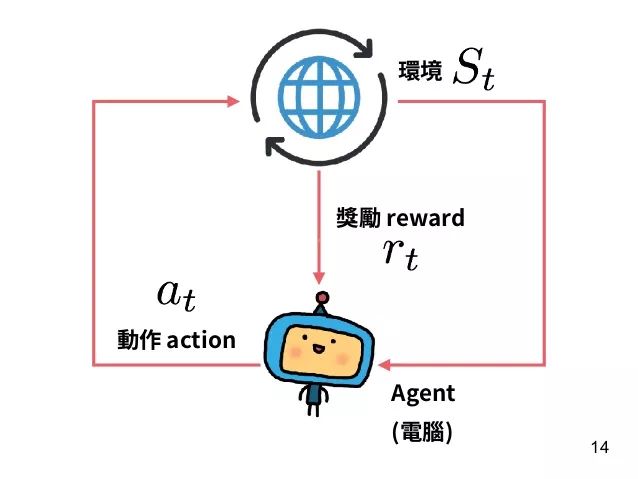
【导读】强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。David Sliver 总结了强化学习的十大原则,以指导强化学习的良好进行。
作者 | David Sliver
编译 | Xiaowen
原则#1
:
评估(Evaluation)
推动进步
客观,量化的评估推动了进步:
●评估指标的选择决定了进度的方向
●可以说是项目过程中最重要的单一决策
排行榜驱动的(
Leaderboard-driven
)研究:
●确保评估指标对应最终目标
●避免主观评估(例如人工检查)
假设驱动的(
Hypothesis-driven
)研究:
●提出一个假设:
○“Double-Q学习优于Q-learning,因为它减少了向上偏差(upward bias)”
●在广泛的条件下验证假设
●比较相似的现有stat-of-the-art技术
●寻求理解而不是排行榜绩效
原则#2
:
可伸缩性(Scalability)
决定成功
●算法的可伸缩性是其相对于资源的性能梯度
○给定更多资源,性能如何提高?
●资源可以是计算(computation),内存(memory)或数据(data)
●算法的可扩展性最终决定了它的成功与否
○图像
●可伸缩性始终(最终)比起点更重要
●给定无限资源,(最终)优化算法是最佳的
原则#3
:
通用性(Generality)
未来证明算法
●不同的RL环境中,算法的通用性表现不同
●避免过度拟合当前任务
●寻求推广到未知未来环境的算法
●我们无法预测未来,但是:
○未来的任务可能至少与当前任务一样复杂
○当前任务遇到的困难很可能会增加
●结论:针对RL环境进行测试
原则 #4
:信任Agent的经验
●经验(观察observations,行动actions,奖励rewards)是RL的数据
○
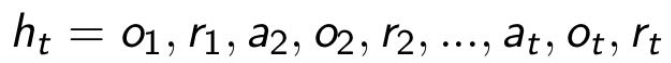
●相信经验是唯一的知识来源
○总是有诱惑力来利用我们的人文专长(人类数据,功能,启发式,约束,抽象,域操作)
●从经验中学习似乎是不可能的
○接受RL的核心问题很难
○这是人工智能的核心问题
○值得努力
●从长远来看,从经验中学习总能赢得胜利
原则#5
:
状态(State)
是主观的
●Agents应根据自己的经验构建自己的状态
○
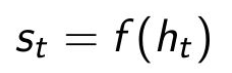
●Agent状态是先前状态和新观察的函数
○
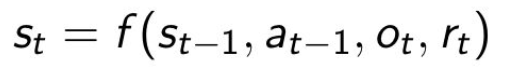
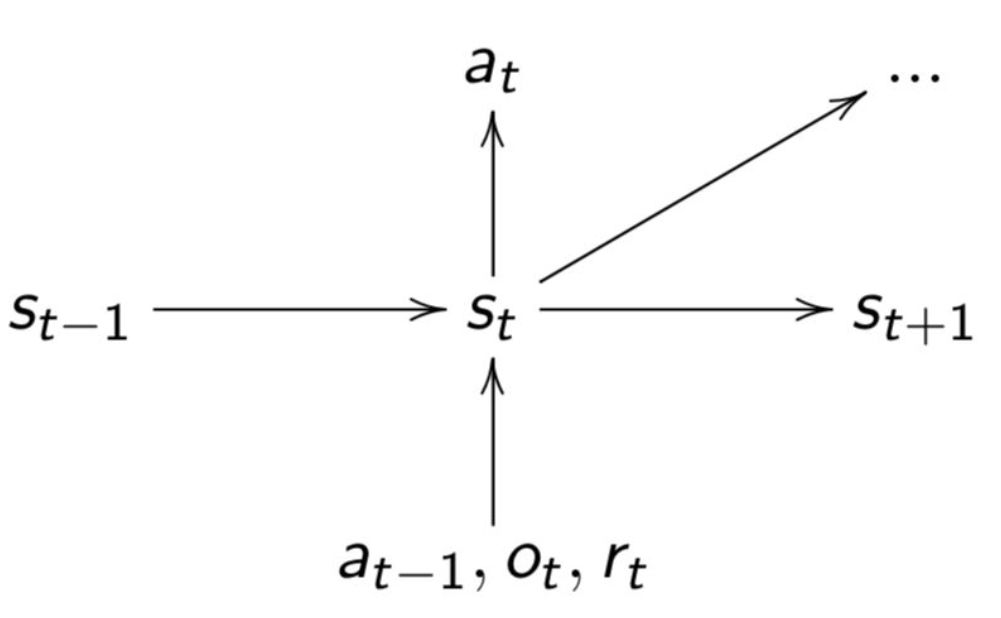
●它是循环神经网络的隐藏状态
●从未根据环境的“真实”状态定义
原则#6
:
控制流(Control theStream)
●Agents生活在丰富的感觉运动数据流中
○Observations流入Agent
○Actions流出Agent
●Agent的操作会影响流
●
控制功能=>控制流
●控制流=>控制未来
●控制未来=>可以最大化任何奖励
原则#7
:
值函数(Value Functions)
建模世界
为什么要使用值函数?
●价值功能有效地总结/缓存未来
●将计划减少到恒定时间查找,而不是指数前瞻
●可以独立于其跨度进行计算和学习
学习多种值函数:
●有效地模拟世界的许多方面(控制流)
○包括后续状态变量
●多个时间尺度
避免在原始时间步骤对世界进行建模。
原则#8
:
规划(Planning)
:从想象的经验中学习
一种有效的规划方法:
●想象一下接下来会发生什么
○模型中状态的样本轨迹
●从想象的经验中学习
○使用我们应用于实际实验的相同RL算法
现在,关注值函数近似值。
原则#9
:授权
函数近似器(FunctionApproximator)
●差异化的网络架构是强大的工具,可以促进:
○丰富的状态表示
○不同的记忆
○不同的计划
○分层控制
○...
●将算法复杂性推入网络架构
○降低算法的复杂性(如何更新参数)
○
提高架构的表现力(参数的作用)
原则#10
:
学会学习(Learn toLearn)
人工智能的历史显示了明确的进展方向:
●第一代:良好的老式人工智能
○手工预测
○什么都不学
●第二代:浅学习
○手工功能
○学习预测
●第3代:深度学习
○手工算法(优化器,目标,架构......)
○端到端地学习功能和预测
●第4代:元学习
○无手工
○端到端学习算法和功能以及预测