不同于以 SCI 期刊作为评价标志的其它学科,计算机学科由于成果更新迅速而倾向于通过会议优先发表成果,因此计算机学科各方向的顶级会议大多比相应的顶级期刊更有权威性和影响力(顶会接收率一般低于顶刊)。人工智能(Artificial Intelligence, AI)/机器学习作为引领未来发展的主导学科之一,该领域的相关会议有上百个,其中 CCF 推荐的 A 类顶级会议有 7 个,而 NIPS 和 ICML 是机器学习领域最受认可的两大顶会。
本届 NIPS 共收到 3240 篇论文投稿,创历年新高,有 678 篇论文被选中作为大会论文,录用比例 20.9%。其中有 40 篇被选中作口头报告(oral),112 篇选为亮点(spotlight)进行展示,亮点论文的接收率仅为 3.4%。
受机器之心邀请,清华博士生宋朝兵对以他为第一作者的一篇 NIPS 2017 亮点论文进行解读。
值得一提的是,该论文完全由清华师生完成,没有校外人员参与。历年来 NIPS 上国内单位独立完成的论文极少,如 NIPS 2015 [1]共录用 403 篇论文,仅有 5 篇由国内独立完成。

论文链接:https://arxiv.org/pdf/1702.07842v2.pdf
作为一项面向未来的技术,机器学习目前被广泛应用在工作生活的方方面面。很多机器学习模型都可以归纳为一个凸优化问题。机器学习模型的有效性源于对大规模数据的利用,
而应用大规模数据提升机器学习模型有效性的同时也带来优化的瓶颈。
为了求解大规模凸优化问题,只使用梯度信息的一阶方法由于其低成本的迭代复杂度被广泛使用。为了进一步提升收敛率并减少迭代复杂度,有两种重要策略被应用在一阶方法中:Nesterov's 加速和随机优化。
一般而言,Nesterov's 加速旨在通过某种代数 trick 加速一阶算法;随机优化则是指每次迭代中采样一个训练样本或者一个对偶坐标的优化方法。假设
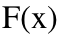 凸且平滑并用
凸且平滑并用
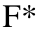 表示最小化问题
表示最小化问题
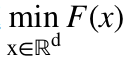 的最优值。为了找到满足
的最优值。为了找到满足
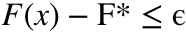 的近似解 X, 经典的梯度下降方法需要
的近似解 X, 经典的梯度下降方法需要
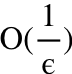 次迭代。然而在使用 Nesterov's 加速机制后,所得到的加速梯度下降算法仅需要
次迭代。然而在使用 Nesterov's 加速机制后,所得到的加速梯度下降算法仅需要
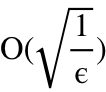 次迭代。该迭代次数对一阶优化算法而言是最优的。另外,假设
次迭代。该迭代次数对一阶优化算法而言是最优的。另外,假设
 同时也是 n 个样本凸函数的有限和。那么通过采样一个训练样本,随机梯度下降 (Stochastic Gradient Descent, SGD) 和它的变种能够以样本大小为倍数减少迭代复杂度。作为 SGD 的一种替代选择,通过优化
的对偶问题,随机坐标下降 (Randomized Coordinate Descent, RCD) 也能以样本大小为倍数减少迭代复杂度并通过 Nesterov's 加速获得最优收敛率
。 梯度下降和 RCD 的发展过程不禁让人问:Nesterov's 加速和随机优化策略能否用于提升其它的一阶优化算法?
同时也是 n 个样本凸函数的有限和。那么通过采样一个训练样本,随机梯度下降 (Stochastic Gradient Descent, SGD) 和它的变种能够以样本大小为倍数减少迭代复杂度。作为 SGD 的一种替代选择,通过优化
的对偶问题,随机坐标下降 (Randomized Coordinate Descent, RCD) 也能以样本大小为倍数减少迭代复杂度并通过 Nesterov's 加速获得最优收敛率
。 梯度下降和 RCD 的发展过程不禁让人问:Nesterov's 加速和随机优化策略能否用于提升其它的一阶优化算法?
在本文中,
通过研究基于Gauss-Southwell选择的坐标下降,
也就是贪心坐标下降 (Greedy Coordinate Descent, GCD), 我们部分回答了这个问题。GCD 被广泛用于机器学习里的求解稀疏优化的问题中。如果一个优化问题具有稀疏解,GCD 将比和它对应的算法 RCD 更为适合。然而,GCD 的理论收敛率依然只是
。与此同时,虽然迭代复杂度可比较时,GCD 优于 RCD. 然而,在一般情形,为了实现准确的 Gauss-Southwell 选择,事先计算完整梯度是必要的,但这导致 GCD 具有远高于 RCD 的迭代复杂度。具体的讲,本文研究如下有名的用于稀疏优化的 l1 范数正则化问题:
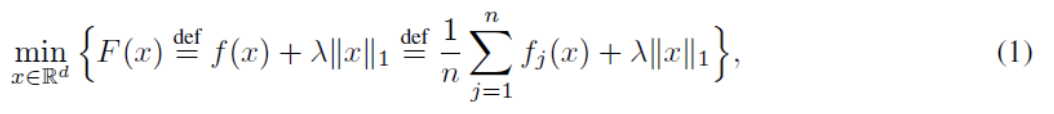
其中,
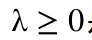 是正则化参数,
是正则化参数,
 是一个平滑凸函数,是 n 个平滑凸函数
是一个平滑凸函数,是 n 个平滑凸函数
 的有限和。给定样本
的有限和。给定样本
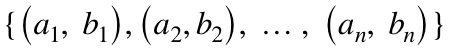 , 其中
, 其中
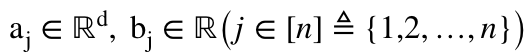 。 如果,
。 如果,
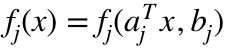 ,那么 (1) 是著名的 l1 范数正则经验风险最小化问题. 如果
,那么 (1) 是著名的 l1 范数正则经验风险最小化问题. 如果
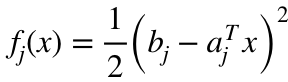 , 那么 (1) 是 Lasso; 如果
, 那么 (1) 是 Lasso; 如果
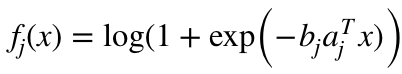 , 那么 (1) 是 l1 范数 logistic 回归。
, 那么 (1) 是 l1 范数 logistic 回归。
在以上非平滑的情形,Gauss-Southwell 规则有 3 个变种:GS-s, GS-r 和 GS-q. 使用以上 3 个规则的 GCD 算法可以概括为如下过程: 基于
 的一种均方逼近,在每次迭代中,以方向向量最多有一个非 0 元为约束的前提下,最小化一个代理函数。这三种规则情形下的问题容易求解但由于方向向量的基数约束,是非凸的。然而,当使用 Nesterov's 加速机制时,为了推导最优收敛率, 凸性是必须的。因此,基于以上 3 种规则,不太可能通过 Nesterov's 加速机制对 GCD 算法加速。
的一种均方逼近,在每次迭代中,以方向向量最多有一个非 0 元为约束的前提下,最小化一个代理函数。这三种规则情形下的问题容易求解但由于方向向量的基数约束,是非凸的。然而,当使用 Nesterov's 加速机制时,为了推导最优收敛率, 凸性是必须的。因此,基于以上 3 种规则,不太可能通过 Nesterov's 加速机制对 GCD 算法加速。
在本文中,通过 l1 范数逼近而不是均方逼近,我们提出了 Gauss-Southwell 规则的一个新的变种。该变种旨在解决一个 l1 正则化 l1 范数平方逼近 (l1-regularized l1-norm square approximation) 问题,如下所示:
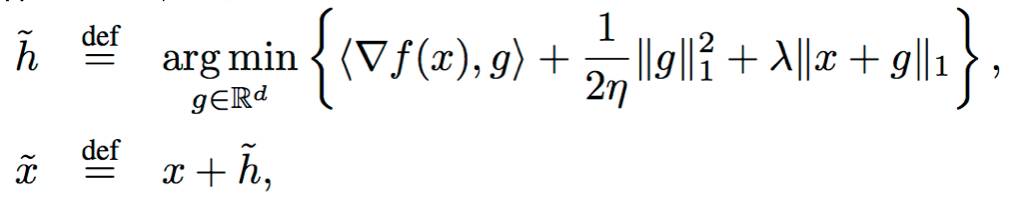
该问题坐标不可分,且有2个非平滑项,不易求解,但是凸的。本文的主要挑战在于解决该优化问题。在本文中,我们提出一个高效的软门限投影 (SOft ThreshOlding PrOjection, SOTOPO) 去准确的求解该问题。SOTOPO 的复杂度是
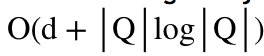 ,
理论发现和实验都一定程度上表明
,
理论发现和实验都一定程度上表明
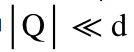 。该复杂度结果比它相对应的的欧式投影方法 SOPOPO 的
。该复杂度结果比它相对应的的欧式投影方法 SOPOPO 的
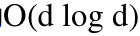 要好很多。SOTOPO 可以看做是 SOPOPO 的非平凡的推广。SOTOPO 算法的描述如下:
要好很多。SOTOPO 可以看做是 SOPOPO 的非平凡的推广。SOTOPO 算法的描述如下:

关于推出SOTOPO算法所依据的引理和SOTOPO可准确求解l1正则化l1范数平方逼近的证明请见原文(非camera-ready)。
然后基于该新规则和软门限投影算法,通过和一个被精心选择的镜面下降 (mirror descent) 算法做线性耦合,我们加速 GCD 使之达到最优收敛率
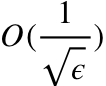 。与此同时,我们的第二个贡献是我们发现没有必要事先计算完整梯度:采样一个训练样本并计算噪声梯度而不是完整梯度,将足以实现贪心选择。该随机优化方法可以样本大小的倍数减少贪心选择的复杂度。最终的结果是一个加速随机贪心坐标下降算法 (Accelerated Stochastic Greedy Coordinate Descent,ASGCD)。ASGCD 描述如下:
。与此同时,我们的第二个贡献是我们发现没有必要事先计算完整梯度:采样一个训练样本并计算噪声梯度而不是完整梯度,将足以实现贪心选择。该随机优化方法可以样本大小的倍数减少贪心选择的复杂度。最终的结果是一个加速随机贪心坐标下降算法 (Accelerated Stochastic Greedy Coordinate Descent,ASGCD)。ASGCD 描述如下:









