
0.介绍
Tesseract是一个开源的OCR引擎,能识别100多种语言(中,英,韩,日,德,法...等等),但是Tesseract对手写的识别能力较差。
1.安装

2.下载语言库
下载地址:https://github.com/tesseract-ocr/tessdata
根据自己的需求选择所要的语言库,在这里我们选择的是简体中文所以选择的库是:
chi_sim.traineddata
将文件拷贝到到:/usr/local/Cellar/tesseract/3.04.01_2/share/tessdata目录下。
3.Tesseract使用
终端输入命令:
tesseract --help
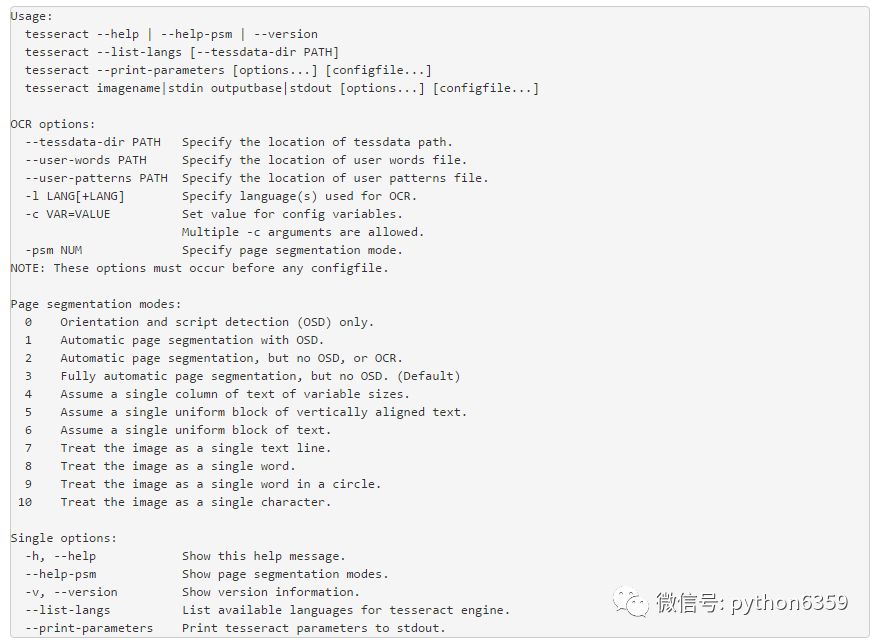
一般使用:
//默认使用eng文字库, imgName是图片的地址,result识别结果
tesseract imgName result
指定语言:
//指定使用简体中文
tesseract -l chi_sim imgName result
//查看本地存在的语言库
tesseract --list-langs
指定多语言:
//指定多语言,用+号相连
tesseract -l chi_sim+eng imgName result
有个地方需要特别注意,参数psm
//输入命令,查看psm的参数
tesseract --help-psm
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
翻译(可能不是很准,最好看原文):
0 定向脚本监测(OSD)
1 使用OSD自动分页
2 自动分页,但是不使用OSD或OCR(Optical Character Recognition,光学字符识别)
3 全自动分页,但是没有使用OSD(默认)
4 假设可变大小的一个文本列。
5 假设垂直对齐文本的单个统一块。
6 假设一个统一的文本块。
7 将图像视为单个文本行。
8 将图像视为单个词。
9 将图像视为圆中的单个词。
10 将图像视为单个字符。
根据情况选择不同的psm值,这很重要,如果选择到不恰当的值会导致识别失败。
比如:
1234.png
使用命令:
//不设置psm值的命令
tesseract 1234.png 1234 -l chi_sim
打印:
Tesseract Open Source OCR Engine v3.04.01 with Leptonica
Info in fopenReadFromMemory: work-around: writing to a temp file
Empty page!!
Empty page!!
//不设置psm值的命令
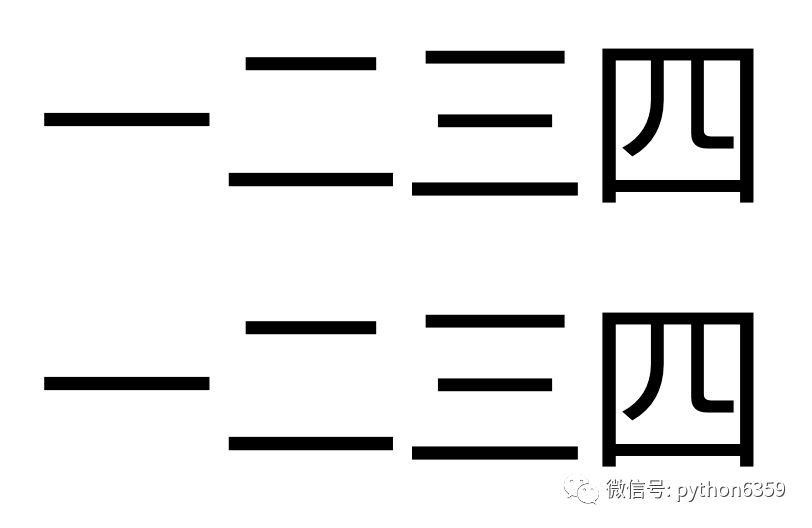
tesseract 1234.png 1234 -l chi_sim -psm 6
成功识别:
一二三四
一二三四
4.语言训练
提前准备:
1.training tools。(在安装tesseract时候运行
brew install --with-training-tools tesseract
这句命令会同时安装training tools)
2.jTessBoxEditor工具。
3.训练素材
在这里准备的素材如下:

hui.png

yi.png
执行命令:
tesseract hui.png hui -l chi_sim -psm 10
识别结果:瞧
tesseract yi.png yi -l chi_sim -psm 10
识别结果:=
显然自带chi_sim库对隳易这两个字的识别不是很好。为了识别这两个字,我们要对这两个字进行训练。
1.素材合成,(多个素材合成)
打开jTessBoxEditor工具,菜单栏:
tools->Merge TIFF...
,选中要合成的图片并保存为为:
huiyi.fitt
。
2.生成box文件
//命令
tesseract huiyi.tif huiyi -l chi_sim -psm 10 batch.nochop makebox
执行后会在生成一个名为
huiyi.box
的box文件。
用文本编辑器或者xcode打开:
瞧 31 37 112 119 0
= 51 86 93 106 1
修改为:
隳 31 37 112 119 0
易 51 86 93 106 1
保存文件。
3.生成.tr文件
//命令
tesseract huiyi.tif huiyi -psm 10 nobatch box.train
4.生成unicharset文件
//命令
unicharset_extractor huiyi.box
注意
unicharset_extractor
命令是training tools里面的集成命令,如果运行时说没有找到该命令则说明你没有安装training tools。
5.创建font_properties文件
字体特征文件,Tesseract-OCR 3.01 及以上版本在训练之前都要创建font_properties文件。文件格式内容格式如下:
fontname italic bold fixed serif fraktur
//翻译
字体名字 倾斜 加粗 固定宽度 衬线体 哥特字体
除了字体之外其他的值都是bool值,0或1
在这里
font_properties
的内容是:
font 0 0 0 0 0
执行命令:
echo 'font 0 0 0 0 0' > font_properties
5.training
执行命令:
shapeclustering -F font_properties -U unicharset huiyi.tr
会生成:
shapetable
文件,重命名为
huiyi.shapetable
执行命令:
mftraining -F font_properties -U unicharset -O huiyi.unicharset huiyi.tr
会生成:
huiyi.unicharset
、
inttemp
,
pffmtable
文件,将
inttemp
,
pffmtable
重命名为:
huiyi.inttemp
,
huiyi.pffmtable
执行命令:
cntraining huiyi.tr
会生成:
normproto
文件,重命名为
huiyi.normproto










