作者:高翔(
Sean
)、唐僧
前不久有位朋友问我,随着近些年来企业存储的发展,每个阶段大致可以达到什么性能水平?直到前两天,我才想起来
5
年多前写过一篇《
SPC-1
:闪存
vs.
磁盘新旧势力的战场》
(链接
http://storage.chinabyte.com/264/12249264.shtml
),从一个侧面分析了企业级
SSD
大范围应用前夜的产品技术格局。到今天我想再补充一个简单的图表:
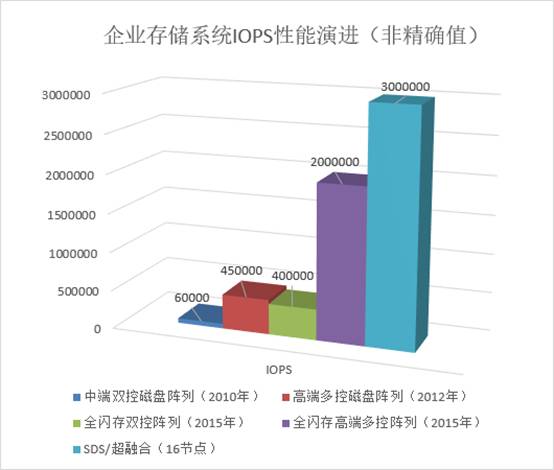
上面数值除了最右边的
SDS
(软件定义存储)
/
超融合之外,仍然参考自几份
SPC-1
测试报告,具体数字进行了一定模糊处理,以免大家对号入座:)
SDS/
超融合一项选择了其它测试方法获得的混合读写
IOPS
,一方面目前参与
SPC-1
测试的分布式
/
软件定义存储还不多(具体原因我放在本文结尾部分);另外如果用更多节点数量在这里“欺负”传统存储,可能也有点不够厚道吧:)
简单来说,早期磁盘阵列
IOPS
受限于
HDD
机械硬盘的平均访问时间,到了
SSD
时代介质的瓶颈相对容易解决。我给出的参考值不能充分代表所有厂商,也并不是每家厂商都积极参与
SPC-1
这样的军备竞赛,因为
性能不是存储的全部
。比如同样是全闪存高端多控阵列(
AFA
),有的可能只是在
4K
读
IOPS
达到
200
万,而这并不能简单评价为“性能差”,因为它同时还打开了重复数据删除和压缩等
数据服务
。
在初创的
All-Flash Array
厂商中,有些已经是分布式控制器的架构。随着多副本和纠删码技术的流行,人们也慢慢开始不再对
FC
、
iSCSI
这些标准协议情有独钟。未来的
NVMe over Fabric
如果还是只限于
Initiator-Target
一对一,那么专用客户端和一些非标准块存储协议就有存在的价值。
如今,我们看到在一些
使用标准服务器硬件的软件定义存储,其每节点贡献的性能已经开始不逊于专门优化的闪存阵列控制器,并且具有更好弹性的和扩展性
。有了这些再加上逐渐的成熟,越来越多的传统存储用户开始青睐
SDS
和超融合(
HCI
)。
下面开始介绍本次测试的内容,大体上分为前后两部分,包括随机
IOPS
、顺序带宽这些基准测试结果,以及模拟
SQL Server OLTP
的表现。
第一部分:
IOPS
、带宽和
SSD
性能的发挥
从
IOPS
测试看分布式存储软件的效率
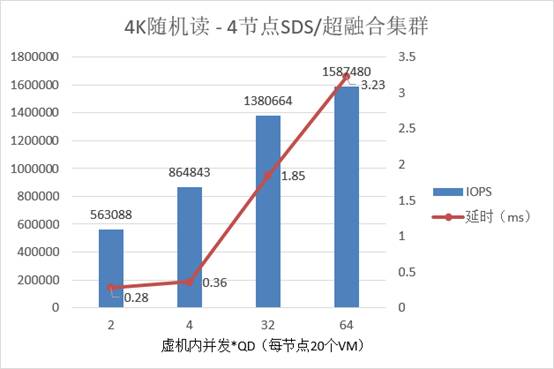
注:上表中的
延时都是在虚拟机中直接收集的
(如无特别说明,以下同),相当于用户
/
应用最实际的感受。
我们部署了一个
4
节点
SDS/
超融合集群
,每节点上除了系统盘之外,有
7
块
SATA SSD
参与组建分布式存储,并采用最常见的
3
副本
配置。每台物理机上使用
20
个虚拟机(共
80 VM
)进行测试。
我们测出的
4
节点
4KB
随机读最大性能为
1,587,480 IOPS
,平均每节点接近
40
万
IOPS
,此时的平均延时为
3.23ms
。总共
28
个
SSD
平均贡献
56,595IOPS
,这里使用的
Intel SSD S3610
官方标称
4KB
随机读
IOPS
为
84,000
,分布式存储软件的效率还不错吧?
如果要看低延时
IOPS
,在
0.36ms
的
IOPS
为
864,843
,平均每节点也超过了
20
万。我们虽然没有使用
NVMe SSD
,但可以给大家看一个之前的测试参考——在《
Intel Optane P4800X
评测
(3)
:
Windows
绑核优化篇
》中
Intel P3700
在
128
队列深度下达到
46
万
IOPS
的峰值,对应的延时为
226
μ
s
。初步预计
换成
NVMe SSD
将有更好的表现
(
CPU
等配置可能也需要升级)。

上图为在
2
节点
上进行
4K
随机读测试的最高性能,
每节点贡献
44
万
IOPS
反映出了
SDS/
超融合的线性扩展能力和本地读优化(后面我还会细谈这个主题)。另外此时
从物理机
OS
看到的存储读延时只有
0.28ms
,可见虚拟机中的延时很大一部分是由于队列,高
I/O
压力对
VM
内
CPU
有明显的开销。
这时读者朋友可能会问,你们测试的是哪家
SDS
?先别着急,再看看随机写的表现。
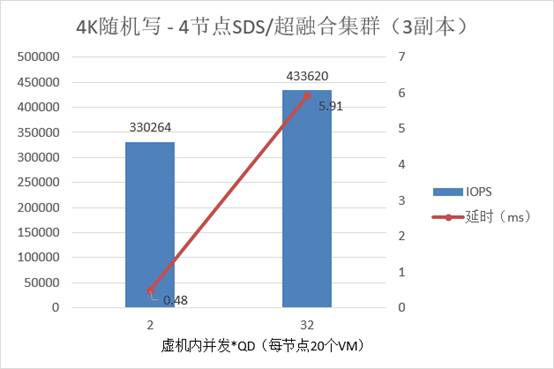
如上图,在每个虚拟机设置
QD=32
时测出的
433,620 4K
随机写
IOPS
已经接近
4
节点集群的峰值。按照这时的数字来计算,
落到每个
SSD
上的
IOPS
就达到了
15,486 x 3=46459
(因为是
3
副本),已经超过了
IntelSSD S3610
官方标称的
27,000
稳态随机写
IOPS
?
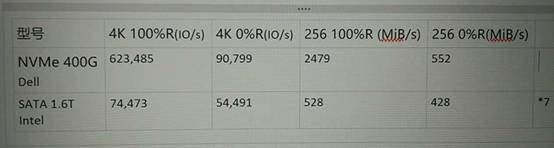
上面是我们在开始测试时
SSD
简单摸底的成绩——
Intel SATA 1.6TB
的
54,491 4KB
随机写并未达到稳态。对这一点我们并不是太在意,因为本次测试考察的是
SDS
存储软件的效率,
SSD
写表现快一点不是坏事吧:)
同理,由于企业级
SSD
是有带掉电保护的写缓存,所以在较低队列深度下
SDS/
超融合集群也能有较好的表现——
330,264 100%
随机写对应的延时只有
0.48ms
。

如果在物理节点上看,写延时也降低了不少。大家都知道直接在物理节点中测试
SDS
效果更好,但由于本文评估的是
虚拟化
&
超融合环境,所以仍然以应用感知的
VM
内延时结果为准
。
再谈副本数量与可靠性
有的朋友可能记得我写过一篇《
为什么
ScaleIO
和
VSAN
不要求三副本?
》,其中提到
VSAN
“不打散”所以双副本可用,而
ScaleIO
通过保护域和故障集的配合、以及重构速度来保障
2
副本可靠性。
也就是说双副本的应用不是完全没有限制的,包括
Ceph
在内的更多强一致性分布式存储软件,大多建议生产环境使用三副本。我在这里想说的一点就是,
在
POC
等性能测试中,对于建议三副本的
SDS
产品使用双副本测试固然能看到更好的数字
,但实际使用又是另一种情况。
对于宣称良好支持双副本的分布式存储,也要像我上面提到的
2
款那样有相应的理论设计基础到充分的测试和实践验证。毕竟
对于企业存储产品来说,数据可靠性重于一切,如果不能保证稳定跑再快也没用
。
微软
S2D
测试环境:
100Gb/s RoCE
网络成亮点
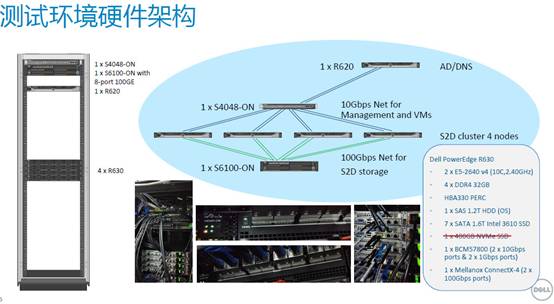
每节点
2
颗
E5-2640 v4 10
核
CPU
只能算是
Intel XeonE5
系列中的主流配置,不属于“跑分很漂亮”但更接近大多数用户的环境。
以上就是本次微软
S2D
(
Storage Spaces Direct
)的测试平台——在上海的戴尔客户解决方案中心(
CSC
)进行,并特邀相关领域专家高翔亲自操刀。

高翔
(
Sean
)上海维赛特网络系统有限公司
副总工程师

早在
3
年前,高翔老师就主持过微软
SOFS
(
Windows Server 2012 Storage Spaces
)的测试及相关项目实践,可以说是国内为数不多精通微软
Storage Spaces
的专家。
关于
RDMA
网络对分布式存储性能的影响,我们先稍后再谈。
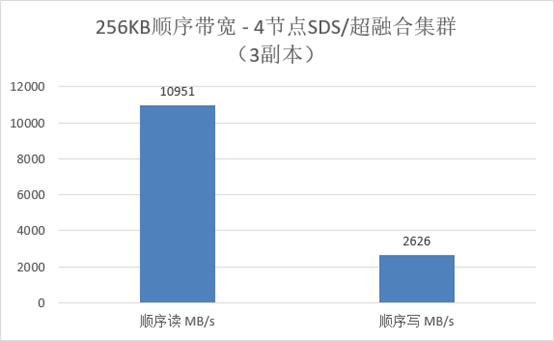
除了
2
节点集群,微软建议
S2D
用户配置
3
副本(另有部分用途适合纠删码)。
我们测出
4
节点
S2D
集群的
顺序读带宽为
10951MB/s
,平均每个
SSD
达到
391MB/s
,对比下前面列出的裸盘性能效率也不低了。至于
2626MB/s
的顺序写,考虑到
3
副本的开销,平均每节点的底层
SSD
总写入量依然达到了
1969MB/s
。
第二部分、
SQL Server
数据库
OLTP
模拟
I/O
测试
在下面的测试中,我们选择继续使用
DiskSpd + VM Fleet
产生存储压力。其中
DiskSpd
是微软提供的一个类似
fio
和
Iometer
的工具,而
VM Fleet
则是配合
DiskSpd
使用的一套脚本,便于同时使用多个虚拟机进行测试。在后续的文章中我们也会用到其它工具,而总的原则如下:
1、
尽量避免因存储之外的配置造成测试瓶颈;
2、
通用性强,易于对比。虽然我们在本文中不做横向比较,但测试过程和结果方便复现,能够为用户和技术同行提供参考价值。
我们也考虑过在数据库中模拟交易
/
查询的测试方法,但其结果受多方面因素影响,包括:执行的
SQL
复杂(优化)程度、
CPU
性能、读写比例、内存命中率等等。想要跑出好看的
TPS
(
TPM
)
/QPS
,许多时候瓶颈会出在
CPU
核心数
x
主频而不是存储上,而用户的业务模型又是千差万别的。所以最终还是决定用微软官方建议的
SQL Server
存储性能评估方法。
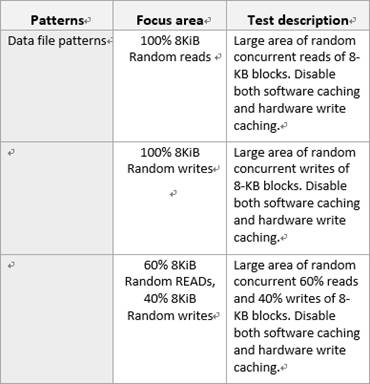
上图截自《
UsingDiskspdforSQLServer
》文档中的范例,在听取几位朋友的意见之后,我们觉得
40%
的写入比例相对于各种
OLTP
用户平均的情况还是偏高了,因此选择了更有代表性的
8KB 70%
随机读
/30%
随机写。
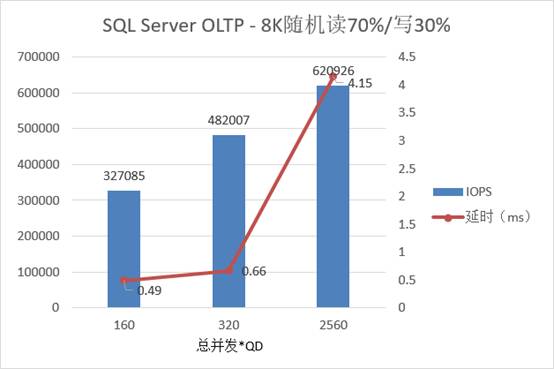
对于实际应用来说,
SQL Server
数据库虚机机在每台物理服务器上的部署数量往往不会很多,但每个
VM
内的
IO
并发
/
队列深度却可能比较大,最终给存储带来的压力应该是同等效果。根据上面图表,在
每台物理机
80 QD
时达到
48
万读写混合
IOPS
,延时为
0.66ms
;当每台物理机总
QD
达到
640
测出接近
最高的
62
万
IOPS
(平均每节点超过
15
万),对应的延时在
5ms
以内。
以上都是
4
个节点上的虚拟机同时压测。如果数据库只是运行在单个虚拟机,或者是
1-2
个物理机上,底层存储仍然由
4
节点
Windows Server 2016
超融合集群提供,这时又会是什么样的性能表现呢?
单
VM
即可发挥一半性能:“另类”
S2D
扩展性验证
由于这里想压测出单个虚拟机在
S2D
上的最大性能,“
1 VM
”用的计算尺寸比较大,是
16 Core
、
56GB
内存,相当于
Azure
上的
D5V2
配置
。而其它测试每台物理机上
20
个
VM
用的是
A2
实例——
2 Core
、
3.5GB
内存。
注:
S2D
其实也是源自
Azure
公有云中的存储技术。
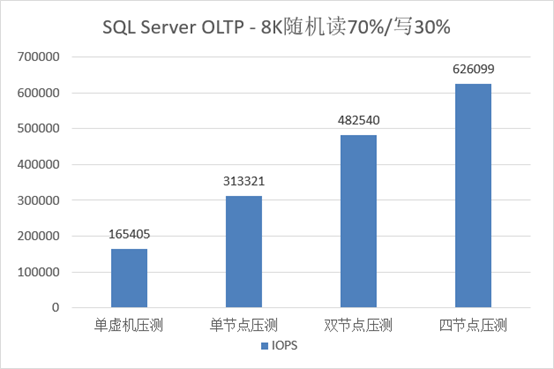
对于
1
个虚拟机中的
165,405 8KB
混合读写
IOPS
结果,我们比较满意。采用不同节点数量对
S2D
集群(仍为
3
副本)加压,
2
节点混合读写
IOPS
大约是单节点的
1.5
倍,
4
节点大约是单节点
2
倍。
上面的标题为什么称“另类”扩展性验证呢?因为人们普遍用整个集群、大量虚拟机来压测超融合的存储,而往往容易
忽略单一负载的效率表现
?我除了想验证这一点,还有服务器
计算资源对性能发挥的影响
(前提是网络在测试环境中不是瓶颈)。不得不承认,
3x-4x
万
IOPS
在
VM
内(客户端)加上
SDS
分布式存储软件本身的开销,对于
2
颗主频一般的
10
核
CPU
已经够忙活了:)
换句话说,如果改用更好的
CPU
和
NVMe SSD
,就应该能达到下面的测试结果:

4
节点
S2D
跑到
3
百万随机读
IOPS
,这应该是我目前看到过平均每节点跑得最快的一个分布式存储测试报告,当然盘的配置也比我们实测要高不少——
2
个
Intel P3700
做缓存层,
8
个同样
NVMe
的
P3500
做容量层。
从超融合本地读优化到分离式部署
通过更多测试,我们观察到
S2D
在
3
副本配置的情况下,写入数据时会全局打散到所有节点,而在读数据时
一旦有副本在本地节点就优先从本地读取
,对于超融合应用有助于减少网络的开销(尽管本文的测试环境网络不是瓶颈)。
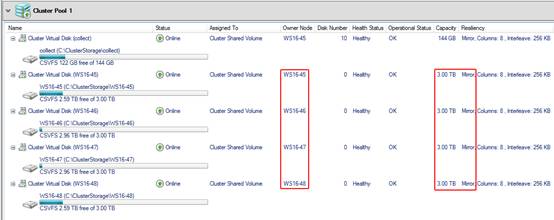
上面只是我们配置过程中的一个截图,可以看到
S2D
上
4
个用于测试的
CSV
(集群共享卷)
Onwer
分别指向了不用的节点,这样在对应服务器上加压时就可以享受到本地读的效果。如果某个
Onwer
节点故障,会重新选举新的
Onwer
接管
CSV
。
不知是否有朋友会问:我的
Hyper-V
服务器平均存储压力没有这么大,
S2D
如此性能水平
可否支持为集群外面的主机提供服务?
答案是肯定的。
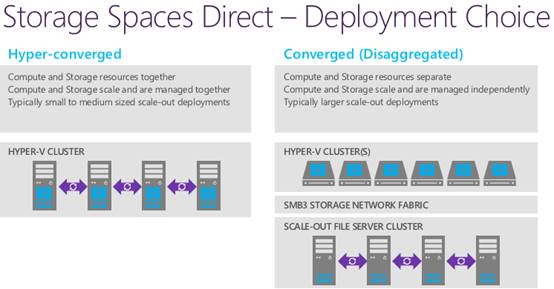
上图我在以前的文章中列出过,右边就是
Hyper-V
集群和
SOFS on S2D
集群分离部署(非超融合)。应用主机和存储节点通过
SMB3
协议网络连接,依然可以选用
RDMA
。
根据
IDC
的预测,“
在
2017
年到
2021
年期间,全球软件定义存储市场的复合年增长率将达到
13.5%
,到
2021
年收入接近
162
亿美元。
HCI
不仅增长最快,复合年增长率为
26.6%
,同时也是最大的子领域
,到
2021
年收入将达到
71.5
亿美元。在预测期内,对象存储的复合年增长率将达到
10.3%
,而文件存储和块存储的复合年增长率将分别达到
6.3%
和
4.7%
。
”
除了技术之外,再谈一下微软
S2D
在销售策略上的特点:与
VMware VSAN
、
NSX
单独销售不同的是,微软将
Windows Server 2016
数据中心版定位成软件定义数据中心的基础,将所需功能集成,一个
License
就搞定
OS
许可
+Hypervisor+SDS+SDN
。
Windows Server 2016
三种部署方式:图形化界面、
Server Core
和
Nano Server
均支持
S2D
。
更多应用针对性的
S2D
测试数据,我们将在后续的文章中继续分享。敬请关注:)
最后,特别感谢上海戴尔客户解决方案中心
Tony Wang
对本次测试的大力支持!
附
1
:
RDMA
性能影响、
SSD
混合存储规则
笔者之前还写过
2
篇
S2D
相关的东西:
《
微软
WS2016
原生分布式存储:还在追赶
VSAN
?
》
《
Azure Stack
中的超融合存储
-S2D
进阶篇
》
现在看来,一年多之前由于资料有限,当时写的一些技术点还不够准确。比如一位微软的朋友就曾指出:“
Built-In Cache
”和“
ReFS Real-Time Tiering
”在
S2D
里可以都看成是缓存技术,区别主要在于后者是先将数据写入副本分层来改善纠删码的性能。
回过来接着看前面的架构图:本次测试使用了
4
台
Dell PowerEdgeR630
服务器,比较豪华的一点是
100Gb/sRDMA
作为
S2D
集群互连网络,包括
Mellanox ConnentX-4
双端口
100Gb
网卡和
Dell Networking S6100-ON
交换机。
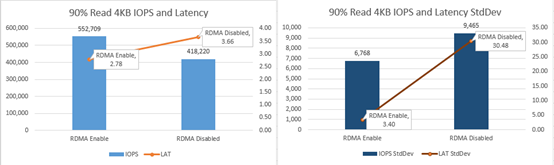
上图来自微软提供的参考数据,启用
RDMA
之后,
S2D
的
IOPS
和延时性能都有明显的改善。如果说在
RDMA
网络下
S2D
的效率才能充分发挥,换个角度也证明
微软于
RDMA
(包括
SMB Direct
)方面在业内较早地进行了比较充分的优化
。

另外说明一点,在这阶段测试中我们并未使用每台服务器上的
1
个
NVMe SSD
,因为不符合当前
Windows Server 2016 S2D
的规则。
S2D
支持
SSD + HDD
或者
NVMe + SSD
的缓存配置,但要求
Cache
层
SSD
每节点不少于
2
个
。关于混合
S2D
配置与全闪存的性能差异,后续我想在另一篇文章中给大家介绍。
附
2
:企业存储系统发展的三个阶段
1
、
5-10
年前的传统
HDD
磁盘阵列
相信许多朋友都看到过以下这组公式,根据硬盘的平均访问(寻道
+
旋转)延时来计算单盘的
IOPS
参考值:
15000rpm
硬盘
1000/(2+3.5)
≈
180
10000rpm
硬盘
1000/(3+3.5)
≈
150
7200rpm
硬盘
1000/(4.17+8)
≈
80
利用每块硬盘的
IOPS
,乘以盘数(主轴数量)
可以得到一个存储系统的经验
IOPS
值,比如设计合理的情况下
256
块
15K HDD
可达
4-6
万随机读
IOPS
,此时控制器的处理能力往往还不会是瓶颈。随机写的情况相对复杂一些,
RAID 1
的写惩罚
=2
,
RAID 5/6
写惩罚则是
4/6
,所以我们看到各存储厂商在测试
SPC-1
这些交易类型的
BenchMark
时,大多会选择
RAID 1
(双副本镜像)以获得较好的表现。
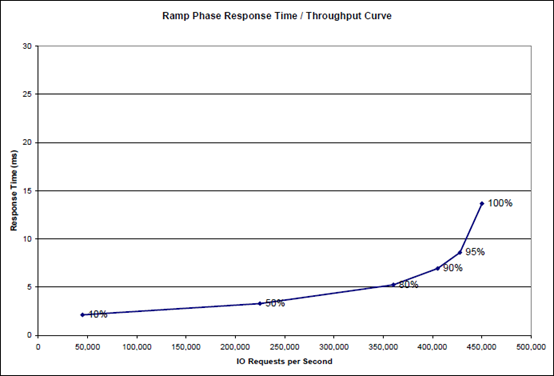
上图来自于
6
年前某高端存储(
8
控制器)的
SPC-1
测试报告,在此只用于技术举例无意提及品牌型号。它配置了
1920
块
15K HDD
硬盘,按照总共
45
万
IOPS
来计算,平均每块盘贡献大约
230 IOPS
。
为什么比前面的经验公式要高呢?我认为有以下几个方面的原因
a.
SPC-1
测试负载中包括一部分顺序读写;
b.
阵列的预读
/
写缓存有一定
I/O
合并效果(
HDD
阵列低于
5ms
延时也是因为
Cache
优化);
c.
有些参测阵列并未划分全部容量,使实际的平均访问时间低于全盘范围(类似于短击的效果,只针对机械硬盘)。
记得在《
存储极客:
SPC-1
负载分析与
AFA
寿命评估
》一文中,我对
SPC-1
曾有过粗略研究,根据
IOPS
计算出写入的数据量。
SPC-1
是个比较复杂的混合负载,包括约
39%
的读
IO
(应该主要是随机)和
61%
的写
I/O
,而后者当中至少有接近一半(占整体
28%
)的日志
/
顺序写入
。在数据块大小方面,分为
4KB
和
SMIX
两种类型,
SMIX
是按照一定比例的混合块,经计算其平均
I/O
大小为
14.4KB
。整体上看,
读
I/O
平均尺寸为
6.76KB
,写
I/O
平均
8.83KB
。
注:后来推出的
SPC-1 V3
测试模型有所变化,以上
仅针对
SPC-1 V1
讨论。
2
、当前的全闪存阵列
随着基于
NAND
闪存
SSD
的普及,只需要数量少得多的驱动器就可达到以前“堆硬盘”的效果。
中端双控
AFA
阵列普遍能达到数十万
IOPS
的水平
,此时性能瓶颈已经从存储介质转到了控制器上,
SPC-1
测试
平均到每个
SAS SSD
能贡献
2
万
IOPS
就算效率比较高的
。再加上性能更高的双端口
NVMeSSD
刚开始成熟,人们普遍更加看好
Server SAN/
分布式软件定义存储(
SDS
),特别是超融合(
HCI
)部署形态的发展。
3
、分布式软件定义存储
如今虽然
Server SAN/SDS
厂商如雨后春笋般涌现,但参与
SPC-1
的热度似乎不如以前高。
SPC
组织收费高昂是一方面,此外一位国内做存储研发比较资深的朋友还告诉我一些限制:
SPC-1 V1
应该是只支持
UNIX
和
Windows
客户端;
SPC-1 V3
加入了
Linux
,但还是要求
FC
、
iSCSI
、
iSER
这些标准块设备连接协议,专用客户端访问的存储产品无法参与测试。
这样一来,像
VMware VSAN
、
Dell EMC ScaleIO
、微软
S2D
(
Storage Spaces Direct
,基于
SMB3
协议)等主流软件定义存储产品就不太适合用
SPC-1
来测试。
Ceph
其实也是如此,
iSCSI/FC
网关显然没有原生的
librbd
效率高。
从性能角度来看,
Server SAN/SDS
的扩展性普遍不错,而单节点
IOPS
并不是都能做到很高,达到
10
万
IOPS
每节点就算比较好的了,这方面其实我也撰文讨论过。







