大数据文摘出品
来源:Medium
编译:张秋玥、夏雅薇
经济学人杂志除了色彩鲜明的文章之外,其在数据可视化方面也自成一派。
绝妙的颜色搭配,风格鲜明的图表总能让读者过目不忘。
据图表编辑编辑Sarah Leo在一篇博客中介绍到:虽然对于每一张图表,他们都尽量准确地以最能支持故事表达的方式来可视化数字,但有时候也会犯错。
为了能够做的更好,他们在从错误中不断总结教训,不断的自我改进。为此Sarah Leo还把经济学人的错误总结为3点,并写成一篇博客,供大家参考,大数据文摘对文章编译如下☟
深入了解我们的记录后,我找到了几个有用的例子。我将针对数据可视化的问题分为三类:
免责声明:大多数“原始”图表是在我们的图表重新设计之前发布的。改进的图表是为了符合我们的新规格而绘制的。它们的数据完全一致。
以误导的方式呈现数据是数据可视化中最严重的问题,虽然我们从不故意这样做,但它确实时不时发生。我们来看看三个例子。
错误:截断标尺
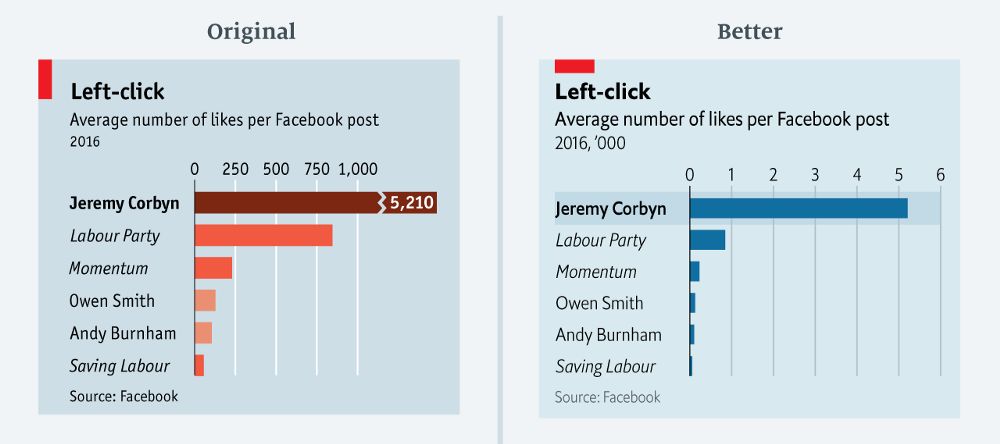
这图就很左翼分子对不对
此图表显示了政治左翼Facebook页面上帖子的点赞平均数量。这张图表的重点是显示Corbyn先生与其他帖子之间的差异。
原始图表不仅低估了Corbyn先生的数量,还夸大了其他帖子的数量。在重新设计的版本中,我们完整地展示了Corbyn先生的数据并保证所有其他数据长条仍然可见。
另一个奇怪的是颜色的选择。为了模仿工党的配色方案,原图使用了三种橙色/红色色调来区分Jeremy Corbyn与其他国会议员和政党。虽然颜色背后的逻辑对许多读者来说可能是显而易见的,但对于那些不太熟悉英国政治的人来说,这可能没什么意义。
错误:通过故意操纵坐标轴来假装存在相关关系
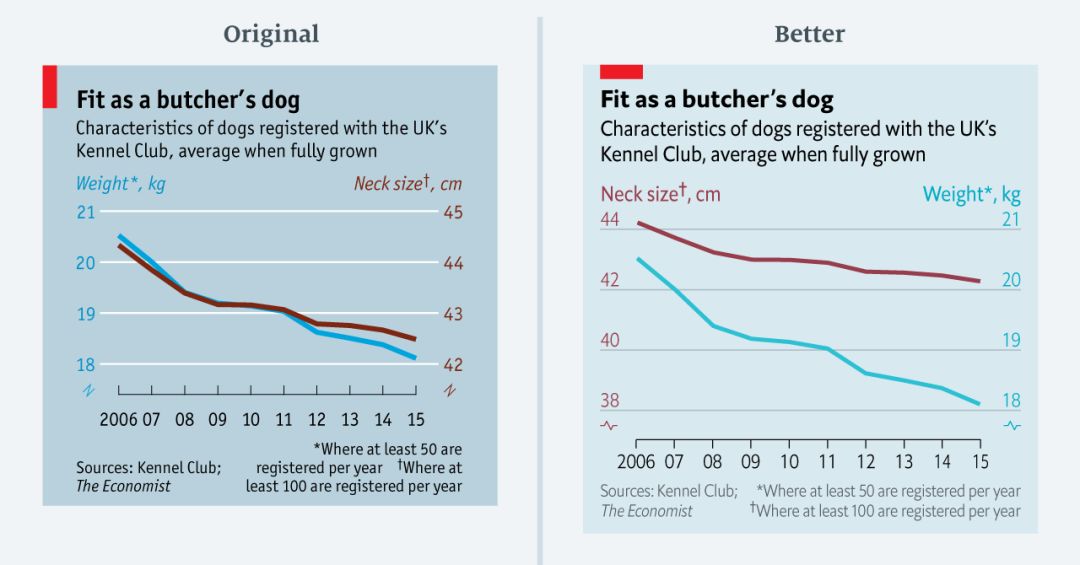
难得的完美关联?并不是的。
上面的图表附有一个关于狗重量下降的故事。乍一看,似乎狗的体重和颈部大小完全相关。但这是真的吗?其实并不是很相关哦。
在原始图表中,两个坐标轴的跨度均为三个单位(左边是21到18;右边是45到42)。按百分比计算,左边的比例下降了14%而右边则下降了7%。在重新设计的图表中,我保留了双坐标轴的设计,但调整了它们的范围以反映可比较的比例变化。
考虑到这个图表的休闲主题,这个错误可能看起来并没有那么重要。毕竟,图表的信息在两个版本中都是相同的。但我们从中学到的事情很重要:如果两个变量过于紧密相关,那么再仔细观察一下坐标轴尺度可能是一个好主意。
错误:选择错误的可视化方法
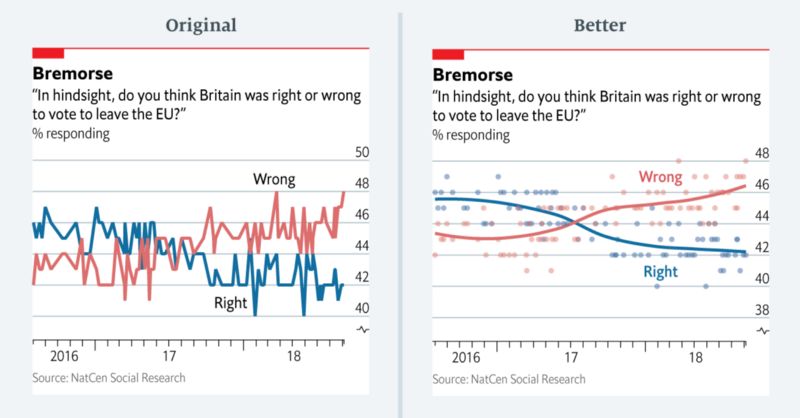
对脱欧的看法几乎和谈判结果一样不稳定
我们在每日新闻应用Espresso中发布了此投票图表。它显示了民众对欧盟公投结果的态度,并以折线图绘制。从数据来看,似乎受访者对公投结果的看法相当不稳定——每周都会增加或减少几个百分点。
我们并未使用平滑曲线绘制单个民意调查来显示趋势,而是连接每个民意调查的实际值。这主要是因为我们的内部图表工具没有绘制平滑线条的功能。我们直到最近才逐渐开始熟悉更复杂的可视化统计软件(如R)。今天,我们团队所有人都能够绘制一个类似上面重新设计的投票图表了。
此图表中需要注意的另一件事是坐标轴如何起点的方式。原始图表将数据扩展到全部空间。而在重新设计的版本中,我在坐标轴开始的部位和最小数据点之间留下了更多空间。弗朗西斯·加农(Francis Gagnon)为此制定了一个很好的规则:我们应当试着在一个不从零开始的折线图下留出至少33%的空白区域。
这没有误导性图表那么过分,但是一份难以阅读的图表还是表明可视化工作做得很糟糕。
错误:“发散性思维”过于发散了
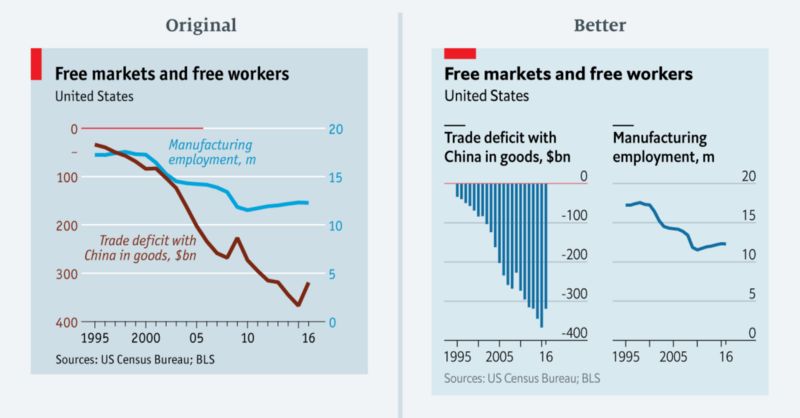
…这啥玩意?
在“经济学人”杂志上,我们被鼓励创造“发散性思维”的新闻报道。但是有时候,我们会认为这有点太过分了。上图显示了美国的商品贸易逆差和制造业就业人数。
该图表非常难以阅读。它有两个主要问题。首先,一个变量(贸易逆差)的值完全是负数,而另一变量(制造业就业)都是正数。将这些差异结合在一个图表中而不平坦化任一变量非常不合理。有一个显而易见的解决方案,但这却会导致第二个问题:两个变量不共享共同基线。贸易赤字的基线位于图表的顶部(通过图表左半边那截红线突出显示),而右半部分的基线则位于底部。
重新设计的图表显示其实并没有必要组合这两个数据系列。贸易逆差与制造业就业之间的关系仍然很明显,而这一图表并没有额外占据多少空间。
错误:莫名其妙的颜色使用
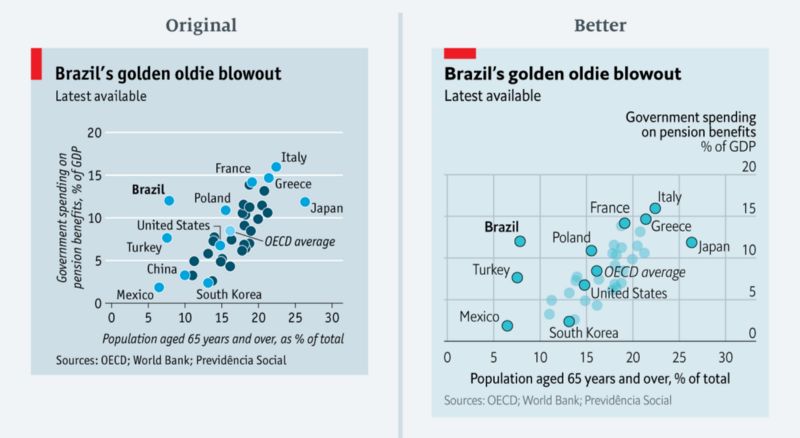
该图表将政府在养老金福利方面的支出与国家65岁以上人口比例进行了比较,并特别关注了巴西的情况。为了使图表占据较小版面,可视化工具仅标记了部分国家/地区,并以电蓝色突出显示。经合组织的平均值则以淡蓝色突出显示。
可视化者忽略了这样一个事实,即不同颜色通常意味着不同分类。乍一看,这个图表似乎也是如此——所有电蓝色似乎属于与深蓝色不同的组合。但其实压根不是这样的,区别只是一个有打上国家标签,一个没有而已。
在重新设计的版本中,所有国家/地区的圆圈颜色保持不变。我将没有标签的数据点的透明度调高了。剩下的就靠排版了:巴西是重点国家所以用字体加粗;而经合组织则用斜体字表示。
最后一类的错误不太明显。像这样的图表不会误导读者,也不会让人感到困惑。他们只是没有证明他们存在的合理性 - 通常是因为可视化
不合理,或者因为我们非要在小版面内塞进过多信息。










