历效数学模型教你如何成为星际争霸高手·下
——向机器学习
来源:科普最前线 sd_equation
孔子说:“温故而知新,可以为师也”。“知新”意在探索未知,而未知往往能极大地满足人们与生俱来的好奇心,这是我们大家都喜欢的。这句话真正的难点在于“温故”——“故”代表人们所知道或学过的东西,不及“知新”那么有挑战性。新鲜感一旦褪色,动力也随之消沉,“温故”自然也变得遥不可及了。
小编在《星际争霸上》
中用逻辑增长模型
(Logistic Growing)
和捕食者模型
(Predator-prey Model)
告诉大家星际争霸高手的修炼途径。不过因为缺乏“温故”,小编再次惨败于电脑。
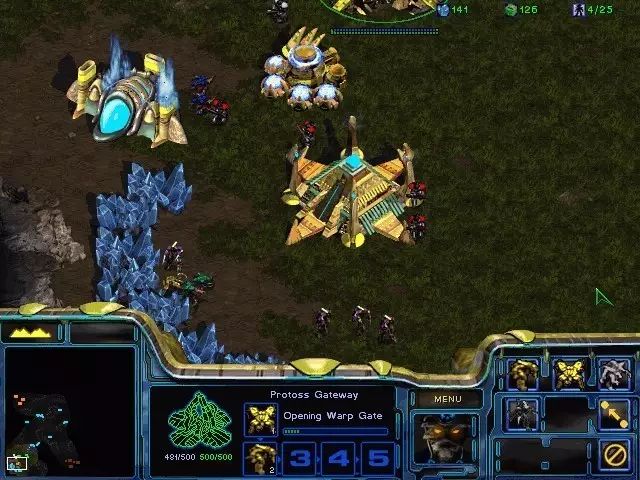
既然“温故”并不易,而且方程模型又不易掌握,难道高手之路就这么被阻断了吗?答案显然是否定的——
知己知彼方能百战百胜,
既然电脑这么厉害,那么我们何不参考参考电脑的策略呢。
小插曲
:
不少读者提到了虫族“口水兵”的翻译问题。把“口水兵”(Hydralisk)翻译成“多头怪”并不是小编的独创,事实上这是最早的中文翻译。如下图:
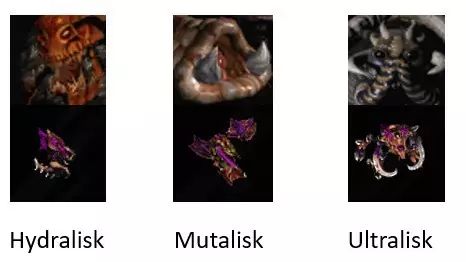
我们注意到这三个虫族单位都以“lisk”结尾,前面各有一前缀。口水兵的前缀是“hydra”,又名海德拉,就是希腊神话中的九头蛇:

所以使用“多头怪”而非“九头怪”,已经是星际争霸翻译组们手下留情了。不过随着星际争霸的普及,大家渐渐发现“多头怪”只有一个脑袋,所以渐渐采用了“口水兵”或者“刺蛇”的翻译。而“Mutalisk”和“Ultralisk”分别翻译为“飞龙”和“巨魔怪”,都很符合兵种特色,从而延续至今。
第一部分 传统AI的策略
除了人类选手的循环赛
(例如WCG)
,电脑
(星际争霸AI)
之间也有每年一度的华山论剑,叫做SSCAIT
(Student StarCraft AI Tournament)
[1]。这个比赛创始于2011年,旨在加强计算机方向的学生们对AI的认识。
本文中的传统AI
(Artificial Intellegence,人工智能)
都是指没有学习能力的AI。按照人工智能先驱亚瑟·塞缪尔的说法,这里的“学习”是指“机器在没有人为指令情况下的学习能力”[2],从数学角度看来也就是
自我更新参数
的能力。玩过星际争霸的读者会对对战模式下,电脑神族开头的狂剑客流
(Zealot Rush)
印象深刻:
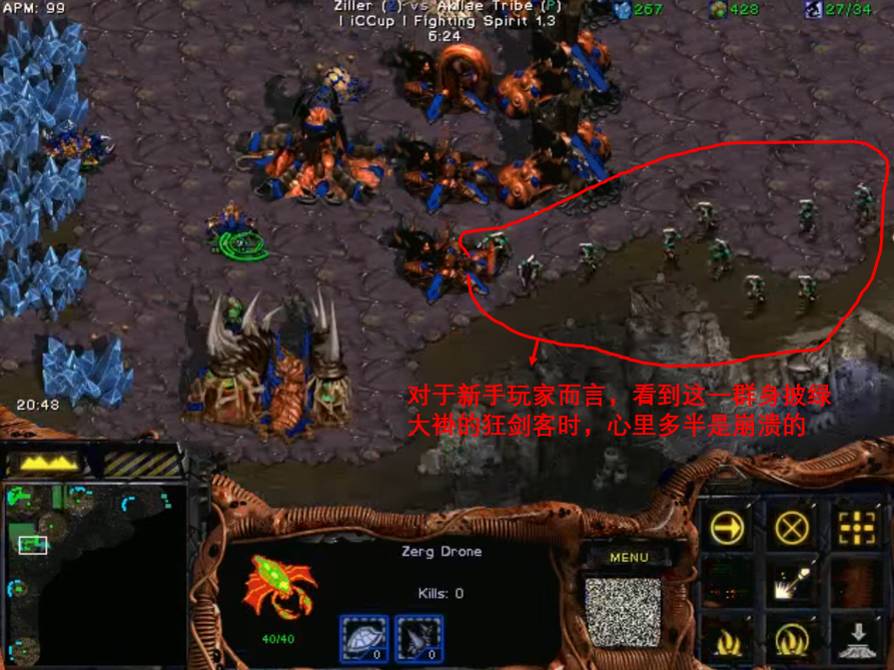
万事开头难,星际争霸也不例外。如果能撑过这一个开头,细心的读者会发现电脑也不过尔尔,因为电脑的所有进攻和行动都是千篇一律的,并且没有任何微操
(Micro-Operation)
。为什么呢?这可以从设置AI的代码中找到答案:

AI战术是这样被设置出来的
所以“狂剑客”对我们造成的心理阴影,完全控制在区区几行代码中!之所以这么简单的战术也能产生如此强大的威力,是因为电脑能够心无旁骛地执行每一项任务。尽管没有微操和随机应变的能力,但靠着
精密和严格
的态度,这种战术也能独领一片天地。
如果电脑拥有一定的微操能力又会如何呢?下面是一个例子
(机枪兵)
:
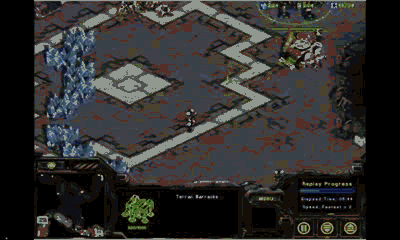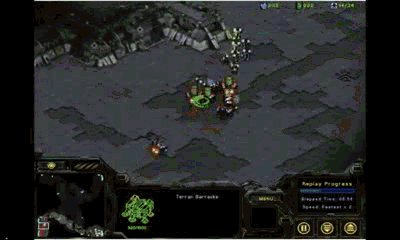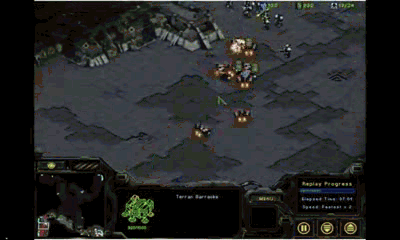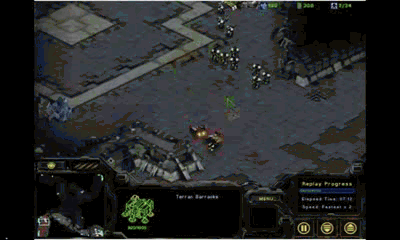
这是2014年SSCAIT半决赛,作战双方是不同学生制作的AI。我们注意到,拥有机枪兵的AI具有较好的微操能力
(会躲避对手的攻击并自动判断射程)
,而另一方则表现糟糕,竟然用最基本单位
(工程师)
去对付机枪兵,纯粹的肉包子打狗!
事实上这样能做到这一步的AI仍然不需要具有学习能力,因为在AI眼中,控制己方单位是通过计算敌我双方的距离来更新的。当未发现敌方目标时,条条大路通罗马,这时候具体往哪个方向前进,全看被控制单位的心情:
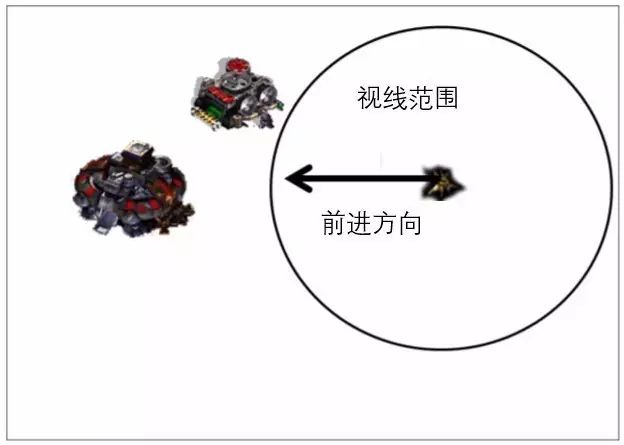
没人能阻挡我前进的步伐
当视线内出现地方建筑目标时,电脑一看不对,有几条路怕是到不了罗马的。所以必须
先计算两个建筑和己方单位的位置向量S1和S2,然后再更新被控制单位的路线
(这里新的路线方向垂直于S1+S2)
,达到曲线救国的目的。上面的动图对机枪兵的操作也是同样道理。
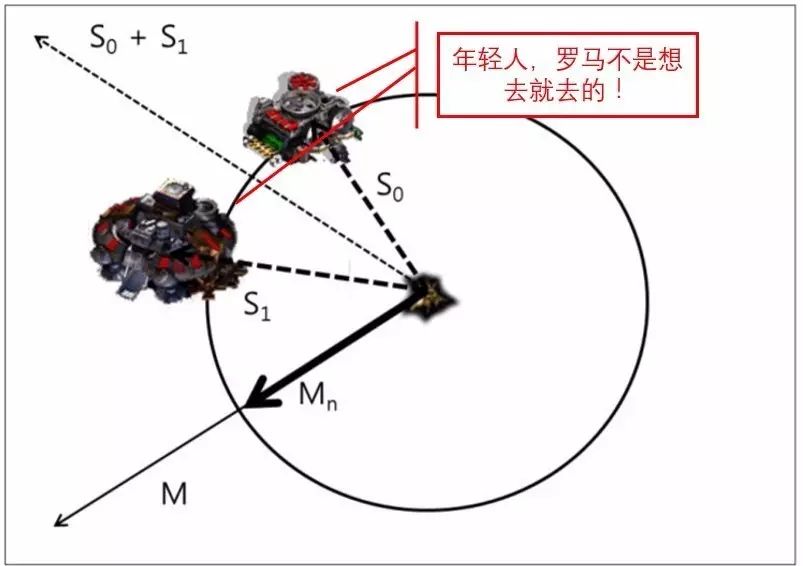
算法取自文献[3]
一些新手也许会感到疑惑:“既然是敌方单位,为什么不直接消灭呢?”其实这和下围棋是一个道理。围棋中我们经常可以注意到一个现象——明明可以提掉对方的子,但通常没人会这么做,因为提掉对方的子尽管令人神清气爽,效率却太低,毋宁高瞻远瞩一番。星际争霸中
(非防御性)
建筑物通常可以作为路障使用,攻击建筑实乃效率低下的选择,所以在多数AI设定中,建筑物的攻击优先率是放在最后的。
第二部分 会自我学习的机器
小编在《爱因斯坦vs阿尔法狗》(传送门)中大概总结了机器学习的一些基本思想,现在我们来复习一下。
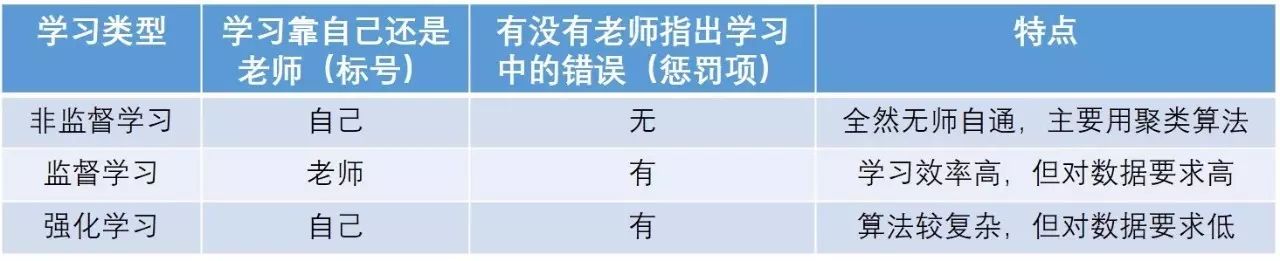
机器学习有三种:
监督
学习
(Supervised Learning)
,
非监督学习
(Unsupervised Learning)
和
强化学习
(Reinforcement Learning)
,它们的区别如下:
前面提到过,从数学的观点看来,机器学习本质上就是更新参数。那么有哪些参数需要更新,以及需要怎么更新它们呢?这个和上面几个学习类型有关。在星际争霸等即时战略游戏中一般用到的是强化学习,所以我们以强化学习应用最广的算法——Q-学习为例。
Q-学习本质上其实是一个
优化问题
(Optimization Problem)
,目的是确定一系列参数使得
回报函数
(Reward function,一般用R表示)
的期望达到最大
,并在这个过程中确定
最佳策略
(Optimal Policy,关于行动的分布函数)
。而回报函数最大期望就是所谓的
Q函数
。数学描述为:

Q学习最早可以追溯到
动态规划
(Dynamic Programming,也就是在与时间有关的限制条件下,使目标函数达到最优。这是控制论的核心内容)
之父贝尔曼的工作[5]。贝尔曼假设回报函数总是采取如下格式:
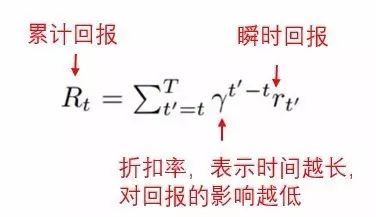
从定义我们不难推测,回报函数在经济金融领域也有广泛用途
于是我们就得到了大名鼎鼎的
贝尔曼方程
(又名贝尔曼优化原理,Bellman's Principle of Optimality)
[5]:
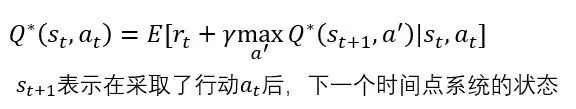
贝尔曼方程的重要性在于,
它使得Q函数的优化问题得以通过迭代的方法完成
。更详细地说,只要知道了所有的初始条件,那么我们就可以使得Q函数极大化,并最终确定出行动函数的最佳策略
(最优分布)
π。
经过强化学习后的AI表现如何呢?我们来看一个例子。
刚开始时,双方兵力完全相同,各有
六个龙骑士和三个执政官
(白色球状物)
。区别是左边一方AI经过了加强学习,右边一方是普通AI。
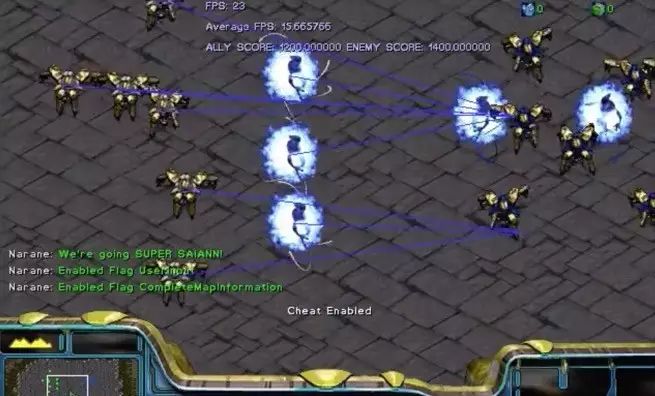
截图取自视频[6]
结果如下:
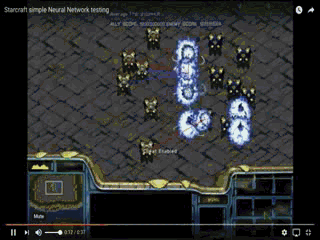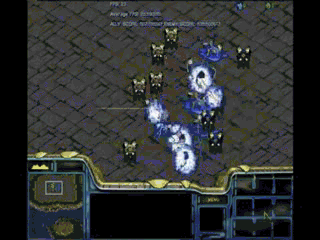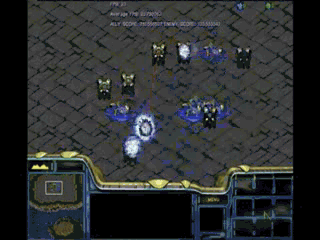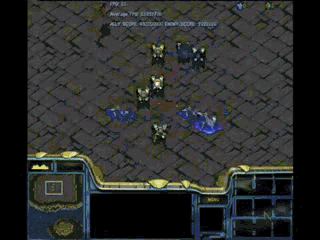
左边一方以净胜五个龙骑取胜!当其他条件没有差别时,细节不仅能决定成败,而且能显著拉开成王败寇之间的距离,这就是操作和策略的精髓所在。无论是游戏中还是生活中,细节都可以成为决定性因素,不可轻易忽视。
尽管贝尔曼方程应用广泛,可谓桃李芬芳遍天下,理论工作者们则更关心它的合理性:如何保证用迭代的方法使得Q学习收敛呢?其根本原因在于
贝尔曼方程中γ小于1的缘故。这也可以通过泛函分析中的
压缩映照定理
(Contract Mapping Theorem)
来解释。此外,如果把贝尔曼方程
(离散动态规划方程)
同物理学中的基本原理,
哈密顿·雅克比方程相结合
,则可以得到控制论中应用最为广泛的连续的动态规划方程——
哈密顿·雅克比·贝尔曼方程
(HJB Equation)
,
具体可参考[9]。
从贝尔曼方程的例子中我们可以看到,伟大的思想也许看起来各有风采,但它们的内在总是相通的。如果能把不同的思想结合起来取长补短,或许能产生颠覆性的新发现。
第三部分 阿尔法狗怎样玩星际争霸2
去年当阿尔法狗战胜围棋大师李世石后,DeepMind公司便宣称接下来的任务是挑战星际争霸2的全球高手,但至今没有任何相关报道。原因只有一个——阿尔法狗在星际争霸2排位赛中表现并不拔尖。
作为即时战略类游戏
(Realtime Strategy Game)
,星际争霸的变化比围棋多太多了。通过排列组合计算,我们可以大概估算出围棋的复杂度是250的150次方
(国际象棋是35的80次方)
[7]。由于即时战略类游戏的时间是连续变化的,策略组合又多,复杂度大得惊人。这是星际争霸的最大难点所在。
尽管本自同根生,星际争霸2和星际争霸又有不小的区别。从画风上,星际争霸2显然具有更好的艺术性:

星际争霸到星际争霸2——华丽的变身
不过在阿尔法狗眼里,游戏界面是这样的:

再美丽的画面也不过是几个圆圈
这种图像识别方法叫做
卷积神经网络
(Convolutional Neural Network)
。和复杂的
全连接网络
(Fully Connected Network)
不同,卷积神经网络
模仿人类的视觉神经
的工作原理,其主要目的在于
通过分层和提取图像特征的方式来简化图像识别
。我们知道图像是由像素构成的,像素的数量能很大程度上决定图像的质量,当像素点过多时,AI对图像的读取效率减慢,就需要简化图像的读取步骤
(提取特征可以通过对一系列权重张量和数据本身的卷积来完成)
[8]
。一般说来,卷积层数越多,能处理的图像越复杂。
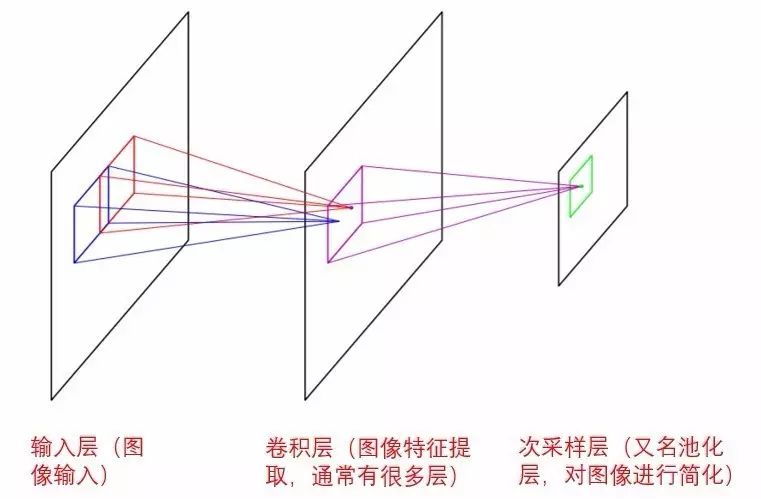
卷积神经网络的三个主要层次
到目前为止,DeepMind已经把卷积神经网络和Q学习运用到一些红白机小游戏当
中
(潜水艇,星际大战等)
[9]。至于到底多久能在星际争霸中和人类顶尖玩家抗衡,这还很难说。不过这给予普通玩家的提示是,如果可以像机器一样找到属于我们自己的Q函数并有针对性地去优化它,那么游戏技能是一定可以提高的。
第四部分 总结和其他
事实上人工智能领域的思想还有很多很多。例如基于Lisp语言的遗传算法
(Genetic Algorithm,模仿生物进化的模式)
和软计算
(Soft computing,运用模糊集合的概念)
等
。这些传统思想常常和统计学习方法相结合,产生举世瞩目的成果。阿尔法狗、机器翻译和自动驾驶等都是出名的例子。
于2017年5月7日
(昨日)
刚过世的吴文俊院士,最著名的贡献之一就是提出了机器证明中的“吴方法”。吴方法基于的是Lisp和Fortran等语言的
泛函式编程系统
(Functional Programming)
,这和今天流行的C/C++、python和java等计算思想都有较大差异。这种方法在几何命题的数学证明中有很大效果,具体说来就是先把几何命题转化为代数方程组,然后用消元的思想去解这个方程组,只关心“xyz”和“+-*/”等符号,而不关心它们的具体计算数值。吴方法在数学机械化领域具有奠基性的作用。

吴文俊院士(1919-2017)同时也是拓扑示性类的大师
吴方法也只是人工智能的一个例子。至于人工智能未来发展到底会如何,或许没人能真正解答。
我们应该辩证地看待人机之间的异同和两者间的关系,用一首词来概括:
青玉案
神经系统寓群岭,根须漫,首尾端。
一触伸缩,二目耀观,万千情相连。
人工智能筑广厦,欲指穹顶破群山。
人心惶惶青出蓝。
山岭杳杳
,广厦灼灼
,天涯共相伴。
因此从星际争霸的角度看来,就算电脑真的打败了人类顶尖玩家我们也不必过于担心——
从目前看来,人类的学习能力是电脑无法企及的;那么
既然电脑可以向人类学习并不断自我强化,我们为什么就不能向电脑学习呢?
参考文献
[1] http://wiki.teamliquid.net/starcraft/SSCAIT.
[2] Andres Munoz,
Machine Learning and Optimization
.
[3] Jay Young et. al,
Prediction of Early Stage Opponents Strategy for StarCraft AI using Scouting and Machine Learning
.
[4] Volodymyr Mnih et. al,
Human-level control through deep reinforcement learning
.
[5] Bellman, R. E. (1957). Dynamic Programming. Princeton, N.
[6] https://www.youtube.com/watch?v=3LdR2sJQ6pA.
[7] David Silver et. al,
Mastering the game of Go with deep neural networks and tree search
.
[8] Christopher M Bishop,
Pattern recognition and machine learning
.
[9] https://en.wikipedia.org/wiki/Hamilton%E2%80%93Jacobi_equation.

往期经典文章回顾:
-
第一个被认为“科学家”的人:泰勒斯
-
数学思维比数学运算更重要
-
二十世纪的十大科学骗局
-
瞎扯现代数学的基础
-
x背后的轶闻趣事
-
主宰这个世界的10大算法
-
16个让你烧脑让你晕的悖论
-
机器学习中距离和相似性度量方法
-
传说中的快排是怎样的
-
玻璃秘史:一个人 改变了全世界
-
程序人生的四个象限和两条主线
-
比特币的原理及运作机制
-
概率论公式,你值得拥有
-
分类算法之朴素贝叶斯算法
-
采样定理:有限个点构建出整个函数


