本文是
《
如何七周成为数据分析师》
的第二十二篇教程,如果想要了解写作初衷,可以先行阅读七周指南。温馨提示:如果您已经熟悉Python,大可不必再看这篇文章,或只挑选部分。
大家学习Python,不练习怎么行
?
这次依旧使用网络抓取的数据分析师的招聘薪资作为练习数据。在早期我们已经用它进行了Excel、BI可视化、SQL三方面的实战训练,想必大家已经很熟悉了,我不再赘述。
没有下载过的同学,后台发送「练习数据」获得链接。
主要内容是进行数据读取,数据概述,数据清洗和整理,分析和可视化。按照本教程,相信大家的Pandas会上到一个新台阶,遇到文中没有提及的错误,通过搜索引擎解决吧。
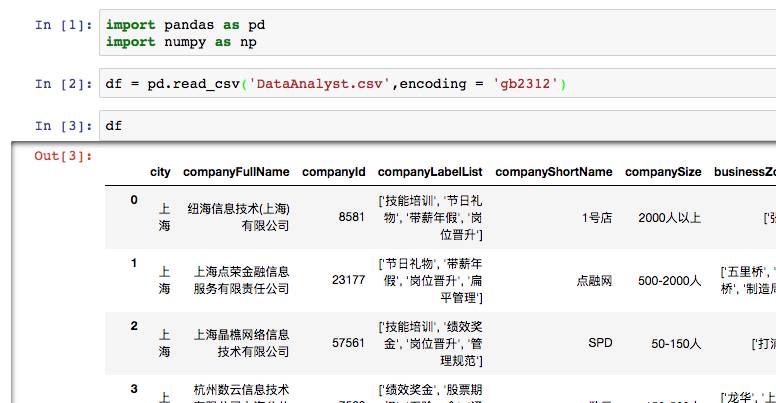
首先载入我们的练习数据。
在pandas中,常用的载入函数是read_csv。除此之外还有read_excel和read_table,table可以读取txt。若是服务器相关的部署,则还会用到read_sql,直接访问数据库,但它必须配合mysql相关包。
read_csv拥有诸多的参数,encoding是最常用的参数之一,它用来读取csv格式的编码。这里使用了gb2312,该编码常见于windows,如果报错,可以尝试utf-8。
sep参数是分割符,有些csv文件用逗号分割列,有些是分号,有些是\t,这些都需要具体设置。header参数为是否使用表头作为列名,默认是。names参数可以为列设置额外的名字,比如csv中的表头是中文,但是在pandas中最好转换成英文。
上述是主要的参数,其他参数有兴趣可以学习。一般来说,csv的数据都是干净的,excel文件则有合并单元格这种恶心的玩意,尽量避免。
现在有了数据df,首先对数据进行快速的浏览。
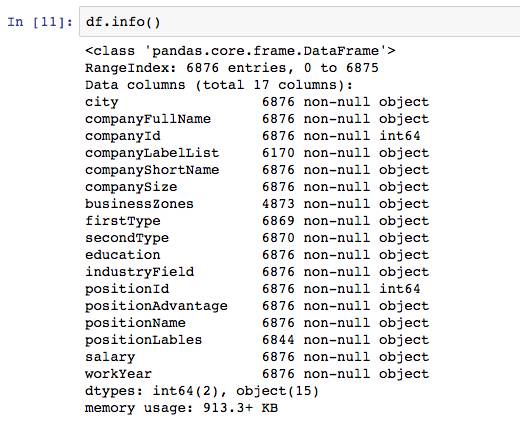
这里列举出了数据集拥有的各类字段,一共有6876个,其中companyLabelList,businessZones,secondType,positionLables都存在为空的情况。公司id和职位id为数字,其他都是字符串。
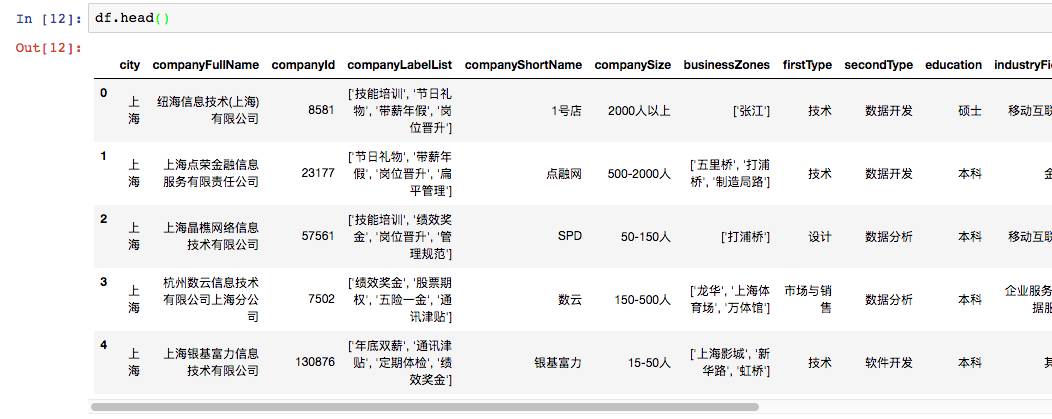
因为数据集的数据比较多,如果我们只想浏览部分的话,可以使用head函数,显示头部的数据,默认5,也可以自由设置参数,如果是尾部数据则是tail。
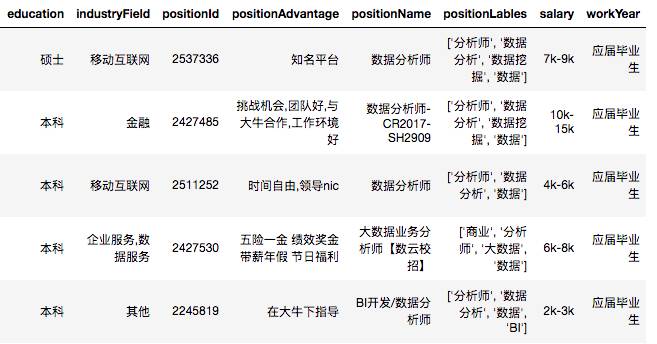
数据集中,最主要的脏数据是薪资这块,后续我们要拆成单独的两列。
看一下是否有重复的数据。
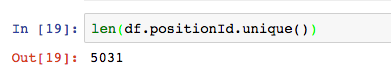
unique函数可以返回唯一值,数据集中positionId是职位ID,值唯一。配合len函数计算出唯一值共有5031个,说明有多出来的重复值。
使用drop_duplicates清洗掉。
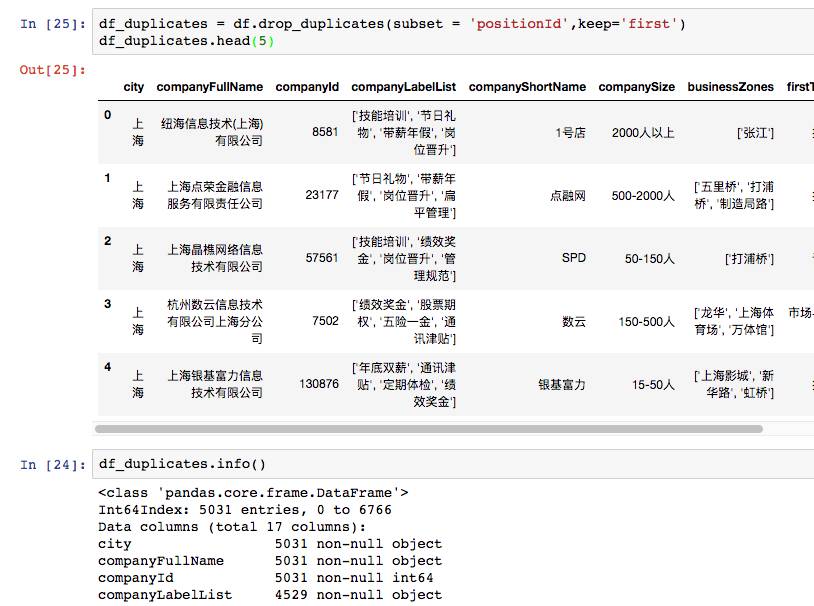
drop_duplicates函数通过subset参数选择以哪个列为去重基准。keep参数则是保留方式,first是保留第一个,删除后余重复值,last还是删除前面,保留最后一个。duplicated函数功能类似,但它返回的是布尔值。
接下来加工salary薪资字段。目的是计算出薪资下限以及薪资上限。
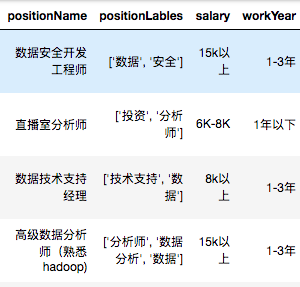
薪资内容没有特殊的规律,既有小写k,也有大小K,还有「k以上」这种蛋疼的用法,k以上只能上下限默认相同。
这里需要用到pandas中的apply。它可以针对DataFrame中的一行或者一行数据进行操作,允许使用自定义函数。
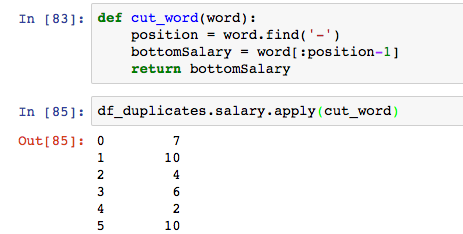
我们定义了个word_cut函数,它查找「-」符号所在的位置,并且截取薪资范围开头至K之间的数字,也就是我们想要的薪资上限。apply将word_cut函数应用在salary列的所有行。
「k以上」这类脏数据怎么办呢?find函数会返回-1,如果按照原来的方式截取,是word[:-2],不是我们想要的结果,所以需要加一个if判断。

因为python大小写敏感,我们用upper函数将k都转换为K,然后以K作为截取。这里不建议用「以上」,因为有部分脏数据不包含这两字。
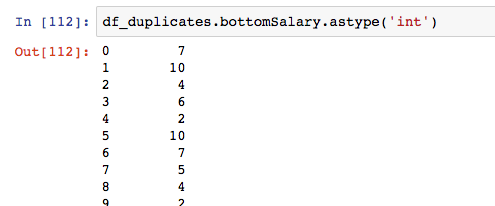
将bottomSalary转换为数字,如果转换成功,说明所有的薪资数字都成功截取了。
薪资上限topSalary的思路也相近,只是变成截取后半部分。
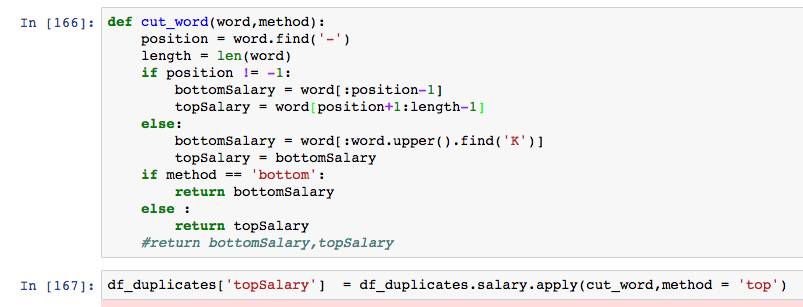
在word_cout函数增加了新的参数用以判断返回bottom还是top。apply中,参数是添加在函数后面,而不是里面的。这点需要注意。
接下来求解平均薪资。

数据类型转换为数字,这里引入新的知识点,匿名函数lamba。很多时候我们并不需要复杂地使用def定义函数,而用lamdba作为一次性函数。
lambda x: ******* ,前面的lambda x:理解为输入,后面的星号区域则是针对输入的x进行运算。案例中,因为同时对top和bottom求平均值,所以需要加上x.bottomSalary和x.topSalary。word_cut的apply是针对Series,现在则是DataFrame。
axis是apply中的参数,axis=1表示将函数用在行,axis=1则是列。
这里的lambda可以用(df_duplicates.bottomSalary +
df_duplicates.topSalary)/2替代。
到此,数据清洗的部分完成。切选出我们想要的内容进行后续分析(大家可以选择更多数据)。

先对数据进行几个描述统计。
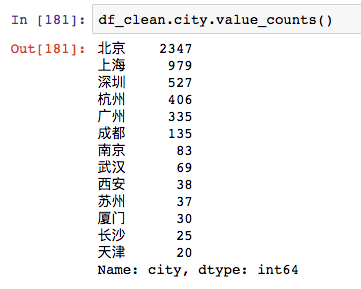
value_counts是计数,统计所有非零元素的个数,以降序的方式输出Series。数据中可以看到北京招募的数据分析师一骑绝尘。
我们可以依次分析数据分析师的学历要求,工作年限要求等。
针对数据分析师的薪资,我们用describe函数。
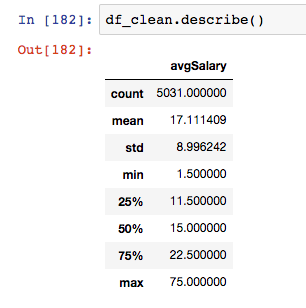
它能快速生成各类统计指标。数据分析师的薪资的平均数是17k,中位数是15k,两者相差不大,最大薪资在75k,应该是数据科学家或者数据分析总监档位的水平。标准差在8.99k,有一定的波动性,大部分分析师薪资在17+—9k之间。
一般分类数据用
value_counts,数值数据用
describe,这是最常用的两个统计函数。
说了这么多文字,还是不够直观,我们用图表说话。
pandas自带绘图函数,它是以matplotlib包为基础封装,所以两者能够结合使用。

%matplotlib inline是jupyter自带的方式,允许图表在cell中输出。plt.style.use('ggplot')使用R语言中的ggplot2配色作为绘图风格,纯粹为了好看。
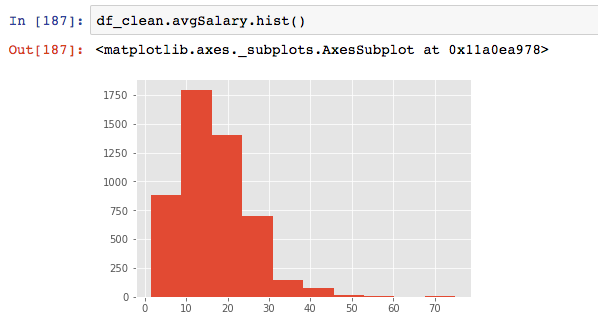
用hist函数很方便的就绘制除出直方图,比excel快多了。图表列出了数据分析师薪资的分布,因为大部分薪资集中20k以下,为了更细的粒度。将直方图的宽距继续缩小。
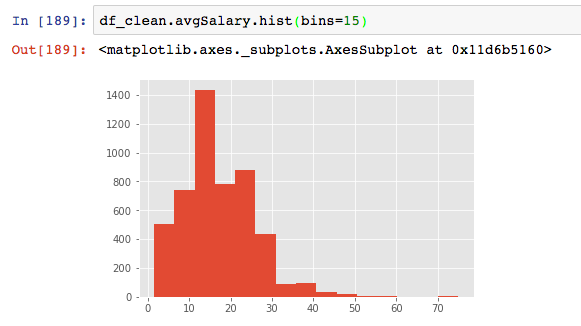
数据分布呈双峰状,因为原始数据来源于招聘网站的爬取,薪资很容易集中在某个区间,不是真实薪资的反应(10~20k的区间,以本文的计算公式,只会粗暴地落在15k,而非均匀分布)。
数据分析的一大思想是细分维度,现在观察不同城市、不同学历对薪资的影响。箱线图是最佳的观测方式。
图表的标签出了问题,出现了白框,主要是图表默认用英文字体,而这里的都是中文,导致了冲突。所以需要改用matplotlib。
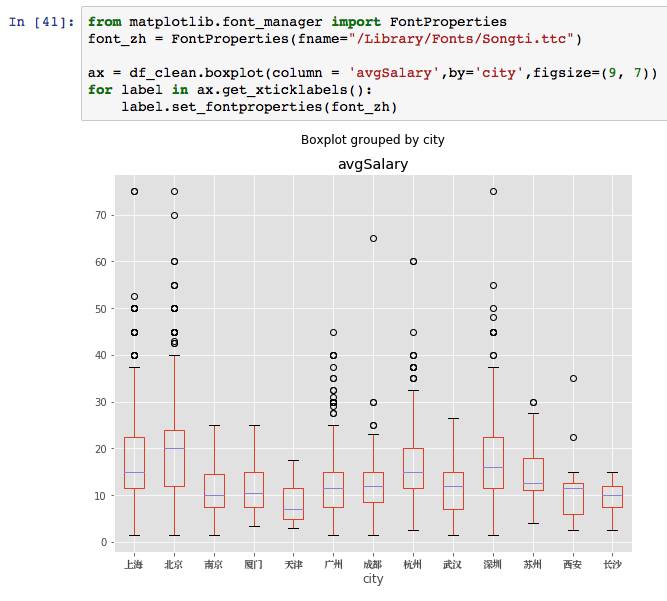
首先加载字体管理包,设置一个载入中文字体的变量,不同系统的路径不一样。boxplot是我们调用的箱线图函数,column选择箱线图的数值,by是选择分类变量,figsize是尺寸。
ax.get_xticklabels获取坐标轴刻度,即无法正确显示城市名的白框,利用set_fontpeoperties更改字体。于是获得了我们想要的箱线图。改变字体还有其他方法,大家可以网上搜索关键字「matplotlib 中文字体」,都有相应教程。
从图上我们看到,北京的数据分析师薪资高于其他城市,尤其是中位数。上海和深圳稍次,广州甚至不如杭州。
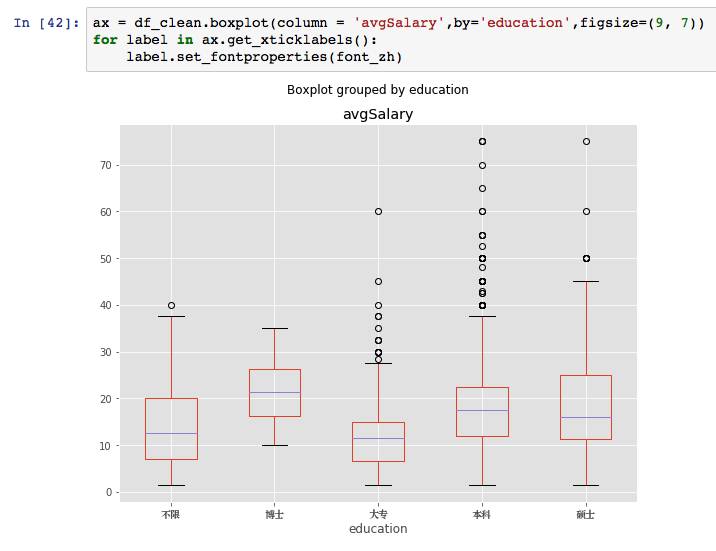
从学历看,博士薪资遥遥领先,虽然在top区域不如本科和硕士,这点我们要后续分析。大专学历稍有弱势。
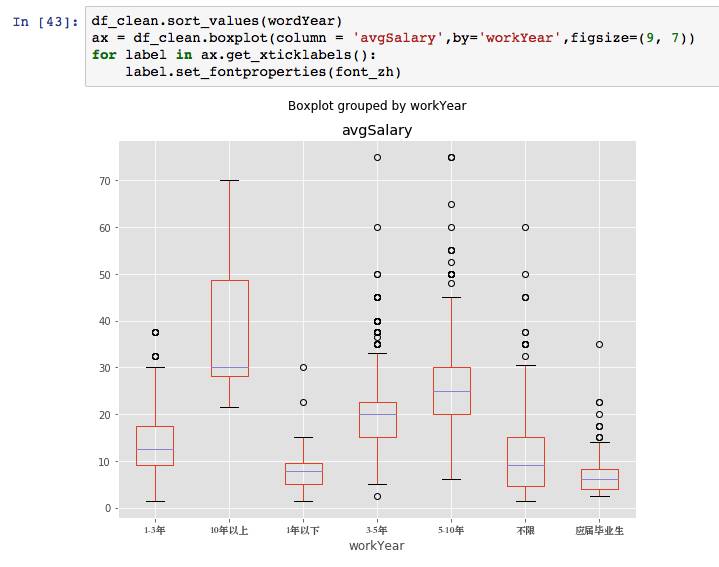
工作年限看,薪资的差距进一步拉大,毕业生和工作多年的不在一个梯度。虽然没有其他行业的数据对比,但是可以确定,数据分析师的职场上升路线还是挺光明的。
到目前为止,我们了解了城市、年限和学历对薪资的影响,但这些都是单一的变量,现在想知道北京和上海这两座城市,学历对薪资的影响。
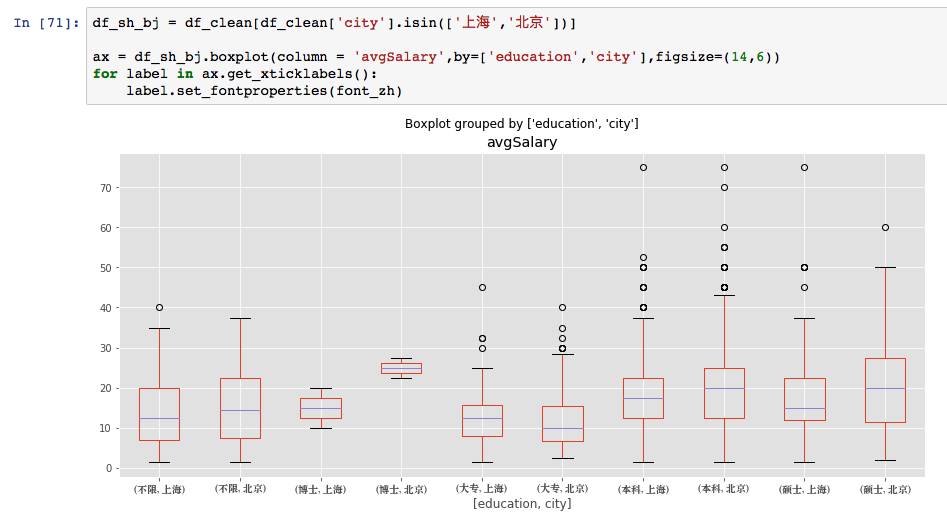
在by传递多个值,箱线图的刻度自动变成元组,也就达到了横向对比的作用(这方法其实并不好,以后会讲解其他方式)。这种方法并不适宜元素过多的场景。从图上可以看到,不同学历背景下,北京都是稍优于上海的,北京愿意花费更多薪资吸引数据分析师,而在博士这个档次,也是一个大幅度的跨越。我们不妨寻找其中的原因。
在pandas中,需要同时用到多个维度分析时,可以用groupby函数。它和SQL中的group by差不多,能将不同变量分组。

上图是标准的用法,按city列,针对不同城市进行了分组。不过它并没有返回分组后的结果,只返回了内存地址。这时它只是一个对象,没有进行任何的计算,现在调用groupby的count方法。

它返回的是不同城市的各列计数结果,因为没有NaN,每列结果都是相等的。现在它和value_counts等价。
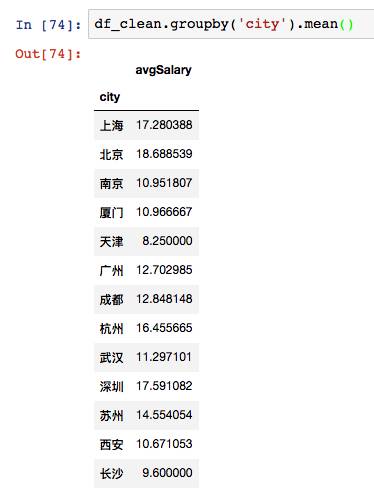
换成mean,计算出了不同城市的平均薪资。因为mean方法只针对数值,而各列中只有avgSalary是数值,于是返回了这个唯一结果。
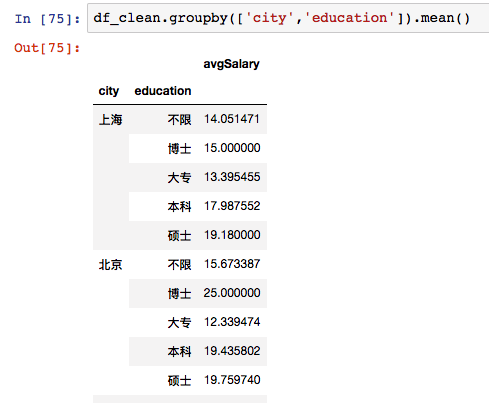
groupby可以传递一组列表,这时得到一组层次化的Series。按城市和学历分组计算了平均薪资。
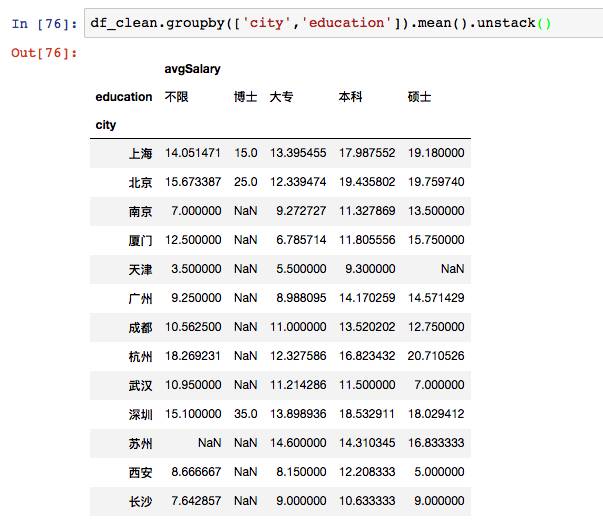
后面再调用unstack方法,进行行列转置,这样看的就更清楚了。在不同城市中,博士学历最高的薪资在深圳,硕士学历最高的薪资在杭州。北京综合薪资最好。这个分析结论有没有问题呢?不妨先看招聘人数。

这次换成count,我们在groupby后面加一个avgSalary,说明只统计avgSalary的计数结果,不用混入相同数据。图上的结果很明确了,要求博士学历的岗位只有6个,所谓的平均薪资,也只取决于公司开出的价码,波动性很强,毕竟这只是招聘薪资,不代表真实的博士在职薪资。这也解释了上面几个图表的异常。
groupby是不是和数据透视表比较像?pandas其实有专门的数据透视函数,在另外一方面,groupby确实能完成不少透视工作。
接下来计算不同公司招聘的数据分析师数量,并且计算平均数。
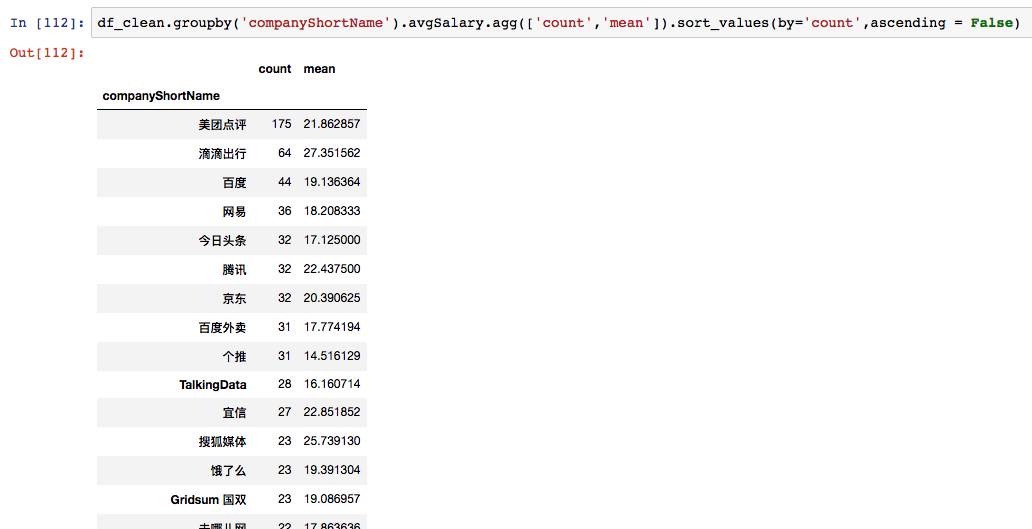
这里使用了agg函数,同时传入count和mean方法,然后返回了不同公司的计数和平均值两个结果。所以前文的mean,count,其实都省略了agg。agg除了系统自带的几个函数,它也支持自定义函数。

上图用lamba函数,返回了不同公司中最高薪资和最低薪资的差值。agg是一个很方便的函数,它能针对分组后的列数据进行丰富多彩的计算。但是在pandas的分组计算中,它也不是最灵活的函数。
现在我们有一个新的问题,我想计算出不同城市,招聘数据分析师需求前5的公司,应该如何处理?agg虽然能返回计数也能排序,但它返回的是所有结果,前五还需要手工计算。能不能直接返回前五结果?当然可以,这里再次请出apply。
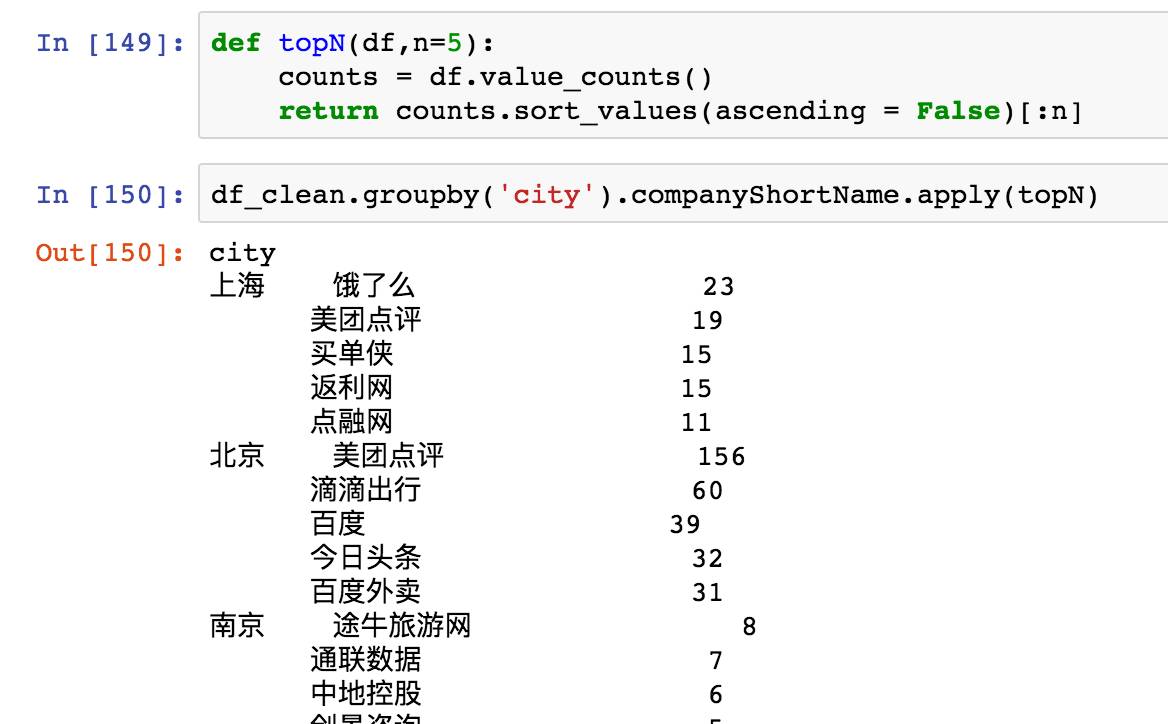
自定义了函数topN,将传入的数据计数,并且从大到小返回前五的数据。然后以city聚合分组,因为求的是前5的公司,所以对companyShortName调用topN函数。
同样的,如果我想知道不同城市,各职位招聘数前五,也能直接调用topN。










