伙伴们,还记得在上篇推文中我们得到的
json
格式的
txt
文件吗?今天,我们就来处理这个文件。
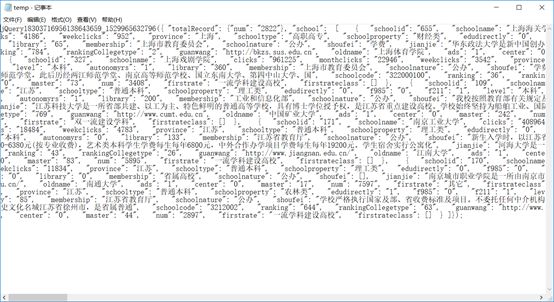
在这里,小编首先附上我们得到上边这个
txt
文件所用到的程序:
clear
cap mkdir E:\中国教育在线\
cap mkdir E:\中国教育在线\全国热度\
cd E:\中国教育在线\全国热度\
!curl -o temp.txt ///
"https://data-gkcx.eol.cn/soudaxue/queryschool.html?messtype=jsonp&callback=jQuery18303716956138643659_1529965632796&province=&schooltype=&page=8&size=30&keyWord1=&schoolprop=&schoolflag=&schoolsort=&schoolid=&_=1529965633197" ///
-H "Accept-Encoding: gzip, deflate,sdch" ///
-H "Accept-Language:zh-CN,zh;q=0.8" ///
-H "User-Agent: Mozilla/5.0 (WindowsNT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112Safari/537.36" ///
-H "Accept: */*" ///
-H "Referer:https://gkcx.eol.cn/soudaxue/queryschool.html?keyWord1=&schoolflag=&1=1&page=8" ///
-H "Cookie: tool_ipuse=223.104.20.26;tool_ipprovince=21; tool_iparea=2" ///
-H "Connection: keep-alive" ///
-H "Cache-Control: max-age=0" ///
--compressed
首先,我们用
fileread()
函数把
txt
文件读入
stata
,并且利用正则表达式将所有的空白字符(包括空格、制表符、回车符、换行符等)删掉。
clear
set obs 1
gen v = fileread("temp.txt")
replace v = ustrregexra(v,"\s","")
这样我们就把整个
txt
文件里面的内容读入到一个单元格里,如下图:
我们将这一个观测值里面的内容复制到
word
中进行分析。

通过分析我们发现:在这里可以根据
①
和
④
对这一个单元格的内容进行拆分、转置,这样一来,每一条观测值就只包含一所高校的基本信息。同时,我们可以看到,标号
②
中
shoufei
和
jianjie
的内容比较杂乱,所以我们删掉每所高校中的这部分信息,标号
③
中
oldname
之后的内容没有意义,我们同样将其删掉。
split v , p(`"[{"'`"},{"')
drop v v1
sxpose,clear
replace _var1 = ustrregexra(_var1,`"(shoufei.+?")schoolcode"',"")
replace _var1 = ustrregexra(_var1,`"(oldname.+)"',"")
结果如下:

再根据逗号对
_var1
进行拆分:
split _var1,p(`","')
drop _var1
结果如下:

我们可以看到,在上图中每一个变量都是“
变量名称+具体内容
”的样式,接下来我们对每一个变量都进行如下操作:将变量名称提取出来放入局部宏里,替换
_var*
,并将观测值中的变量名称删除,只保留具体内容。
程序如下:
foreach c of varlist _all {
if ustrregexm(`c',`""(.+?)":"') local varname = ustrregexs(1)
cap rename `c' `varname'
cap replace `varname' = ustrregexs(1) if ustrregexm(`varname',`"":"(.+)""')
}
drop _var*
将我们希望看到的变量排在前边,再将数据按照全国热度排序,这时我们就得到了我们想要的数据。
order schoolid ranking
destring(ranking),replace
sort ranking
save temp.dta,replace
结果如下:
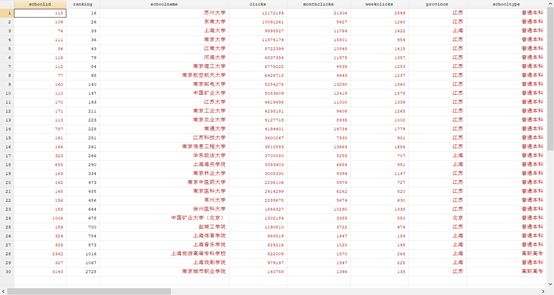
我们可以发现源代码中所含有的信息远远超过了网页本身所显示的信息!可见这次的爬虫收获颇丰啊,当然,
stata
经常会给我们这样的惊喜,只要我们和
stata
君互相熟识,就会发现它有无与伦比的魅力。
二、利用循环,把全部高校的基本信息生成excel表格

通过观察网站信息,我们发现这类表格总共有95页,用一个简单的循环即可,将网页链接中的
page=8改为page=`j’
。再对程序做适当更改,即可得出我们想要的
excel
表格。
程序如下:
clear
cap mkdir E:\中国教育在线\
cap mkdir E:\中国教育在线\全国热度\
cd E:\中国教育在线\全国热度\
forvalues j = 1(1)95{
!curl-o `j'.txt ///
"https://data-gkcx.eol.cn/soudaxue/queryschool.html?messtype=jsonp&callback=jQuery18303716956138643659_1529965632796&province=&schooltype=&page=`j'&size=30&keyWord1=&schoolprop=&schoolflag=&schoolsort=&schoolid=&_=1529965633197" ///
-H "Accept-Encoding: gzip, deflate, sdch" ///
-H "Accept-Language: zh-CN,zh;q=0.8" ///
-H "User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36" ///
-H "Accept: */*" ///
-H "Referer:https://gkcx.eol.cn/soudaxue/queryschool.html?keyWord1=&schoolflag=&1=1&page=8" ///
-H "Cookie: tool_ipuse=223.104.20.26; tool_ipprovince=21; tool_iparea=2" ///
-H "Connection: keep-alive" ///
-H "Cache-Control: max-age=0" ///
--compressed
clear
set obs 1
gen v = fileread("`j'.txt")
replace v = ustrregexra(v,"\s","")
split v , p(`"[{"' `"},{"')
drop v v1
sxpose,clear
replace _var1 = ustrregexra(_var1,`"(shoufei.+?")schoolcode"',"")
replace _var1 = ustrregexra(_var1,`"(oldname.+)"',"")
split _var1,p(`","')
drop _var1
foreach c of varlist _all {
if ustrregexm(`c',`""(.+?)":"') local varname = ustrregexs(1)
cap rename `c' `varname'
cap replace `varname' = ustrregexs(1) if ustrregexm(`varname',`"":"(.+)""')
}
drop _var*
order schoolid ranking
save `j'.dta ,replace
}
clear
cap rm temp.dta
fs *.dta
return list
foreach n in `r(files)'{
append using `n'
rm `n'
}
destring(ranking),replace
sort ranking
compress
export excel using 中国教育在线.xlsx,replace first(variables)
shellout 中国教育在线.xlsx
结果如下:
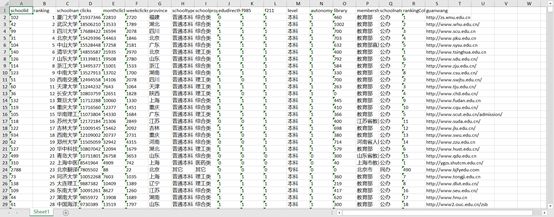
不知道这样一个
excel
表合不合你的胃口,快来这里找找你心仪的高校吧!细心的小伙伴一定会发现,表格第一列出现了
schoolid
,它到底是一种怎样的存在?它对我们后续的爬虫又有什么作用呢?敬请关注下期推文——
大结局
。
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~










